
Remember me

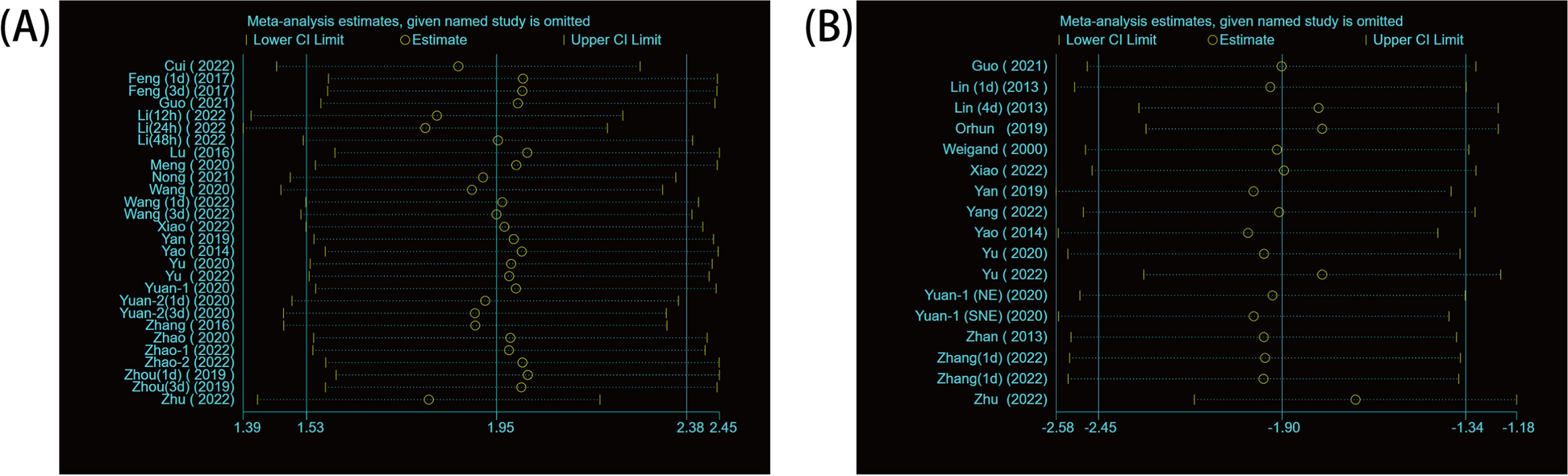
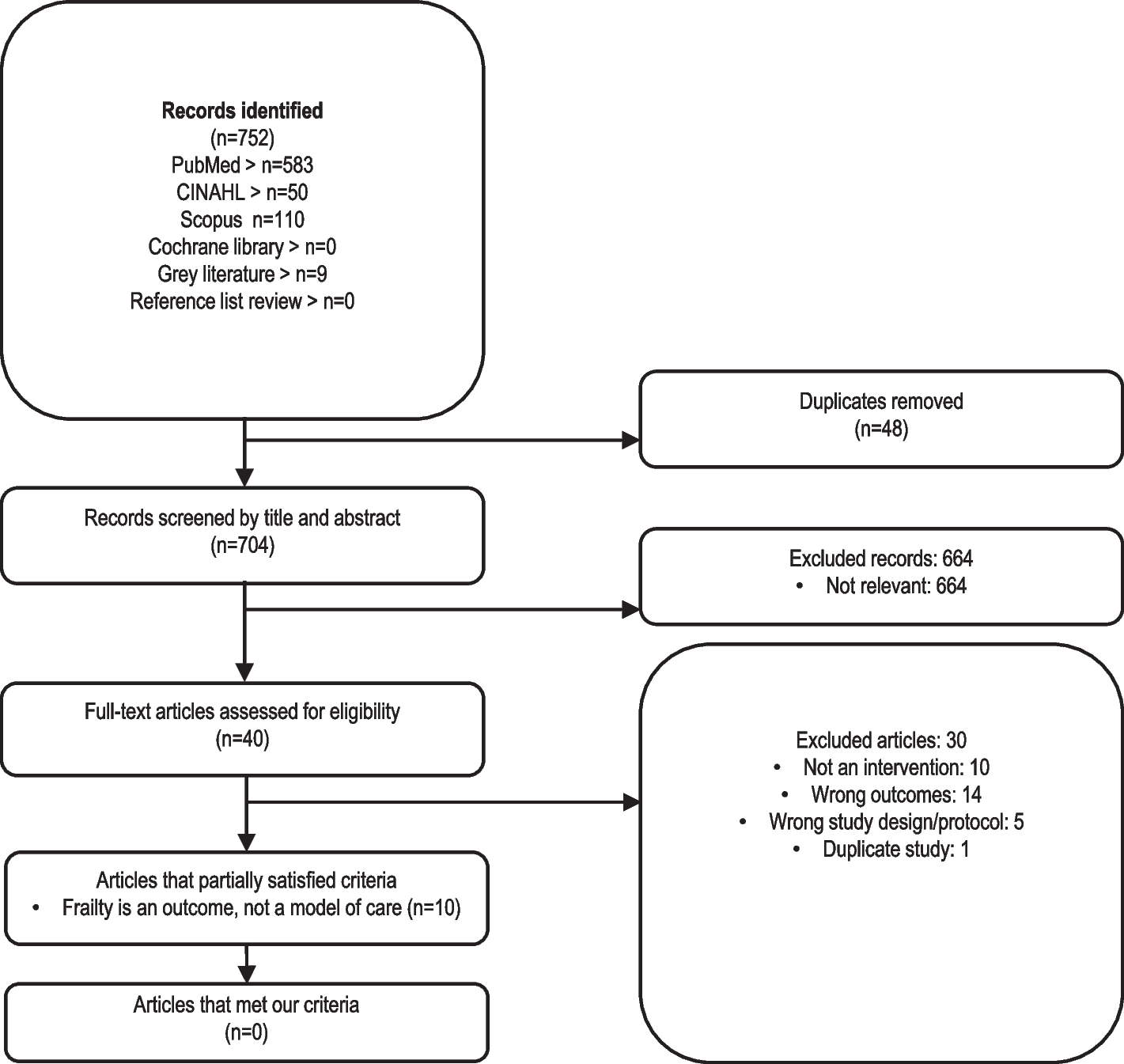
This guideline comprises three main phases, database planning and building and data manipulation; each phase consists of consecutive steps, preferably done in the order listed (Fig. 1). Throughout, input is often needed from content experts, methodologists and statisticians on the outcome(s) data, other data pertinent to the research question, and data needed to evaluate the risk of bias [28]. Expertise in designing and setting up relational databases and data management can also help in the database planning and building phases. The team of content and methods experts, statisticians and database developers is referred to hereafter as the development team.
Fig. 1
Flowchart of the DE steps, Epi Info was applied in Steps 5 and 6 of the database building phase, and R libraries were applied in the data manipulation phase (Steps 9 and 10)
We also compared our proposed guideline with previous DE guidelines. A glossary of terms used in this manuscript is provided in Supplementary Table S1.
Database planning phaseA database should be designed and planned from the outset to ensure consistency and efficiency in how data are extracted [29]. In this phase, the development team plans and drafts a preliminary design for the database. Designing the database could start from scratch, or databases designed for reviews on topics related to the review subject could be used.
Step 1: determine data itemsGenerally speaking, the data collected for SRs should describe the included studies, facilitate the risk of bias and GRADE assessments and enable meta-analyses. In this step, the development team addresses the following question: which data should be collected to answer the review question(s)? Previous knowledge of the topic area, a sample of key eligible articles and/or previously conducted SRs on the same or related topics can help identify pertinent data items. Data items can be dropped or modified, and additional data items can be identified when piloting the DE tool (Step 7); however, the review team needs to be updated with any changes.
Some DE software, e.g. RevMan [22], has the data items needed for bias assessment already built-in. The development team has to decide whether data items needed for bias assessment would be implemented in the DE tool, or standalone tools for bias assessment, such as the Excel ROB2 [30, 31] and the Access ROBINS-I [32, 33] would be used. Data items required for assessing the quality of the body of evidence using the GRADE approach, such as those needed to evaluate the comparability of the populations, interventions, comparators and outcomes of the studies forming the body of evidence to the target population (i.e. indirectness) [34] also have to be determined.
Different meta-analysis methods might be required to answer the review question(s); for instance, if the reviewers aim to identify sources of effect size variation across studies, more data items would be needed than if the aim is only limited to estimating an overall summary of effect sizes [35].
Step 2: group data items into distinct entitiesThe identified data items need to be logically grouped according to their relevance and position in the hierarchy into one or multiple entities, which would be translated into database tables in the following database-building phase. Entities, in database terminology, represent the principal data objects about which data needs to be collected [36].
In this step, the development team has to address this question: What would each row in the dataset represent (a study, a report (trial), or an outcome)? [29]. The organisational structure of the entities can be depicted using a simple tree diagram (e.g. Fig. 2), in which the root entity (top of the hierarchy) captures the data that only occur once in the article, e.g. study characteristics. Branch entities are then added to capture data repeated throughout the article due to multiple outcomes and/or interventions [25]. When more than one outcome value are extracted from each study, the resulting data will form a hierarchical (clustered) structure with studies at the top level. Such multiple outcome values may come from multiple interventions, other within-study subgroups or genuinely different outcomes [25, 28]. In Fig. 2, data items related to the intervention, including dose, route and administration frequency, are assigned to the GROUP entity; hereafter, entities’ names will be capitalised throughout the text. The database structure described herein is for DE purposes only; however, the resulting dataset can be wrangled into different formats for analysis [29].
Fig. 2
The tree diagram illustrates the hierarchical organisation of the data, including 5 entities arranged from top to bottom as STUDY, GROUP, OUTCOME, ARM and CONTRAST, along with their corresponding data items
Step 3: specify the relationships among entitiesEach pair of entities can be connected through one-to-one (1:1), one-to-many (1:M) or many-to-many (M:M) relationships, depending on how each instance (a particular occurrence or entry) in the first entity relates to instance(s) in the second entity [36]. However, the relationship of primary importance for the hierarchical structure is the 1:M, where each instance in the higher-level entity can connect to many instances in the lower-level entity. Relationships among the different database entities can be depicted using an entity-relationship (ER) diagram where each entity is represented as a rectangle with the entity name written inside (e.g. Fig. 3).
Fig. 3
The full ER diagram shows the relationships among the different entities in the database. Each box symbolised a single entity corresponding to an Epi Info form, except the ARM and CONTRAST, which were constructed as grids (i.e. table-like data entry fields) and added to the main form. The data items were listed within each entity. The lines with ‘1’ and ‘M’ markings show the 1:M relationships among the entities. The primary and foreign keys are indicated as GlobalRecordId and FKEY in Epi Info, respectively
Identification (key) variables, primary and foreign keys connect entities together, where the primary key uniquely identifies each row in the higher-level entity, and the foreign key matches the primary key record(s) in the lower-level entity [37]. The primary and foreign keys can be indicated in the ER diagram (e.g. Fig. 3). Existing or new automatically generated data items can be used as identification variables [38].
Step 4: develop a data dictionaryA data dictionary is a document that describes entities, their corresponding data items and the database structure (ER diagram) [29, 39]. Data dictionaries are more comprehensive than codebooks; they include explanatory notes about the database structure, and the information describes variables’ names, labels, types, formats, lengths and other special requirements (e.g. read-only, optional or mandatory) [40].
Following a consistent manner for naming the variables, e.g. camelCase or snake_case, makes them easily recognised when used in statistical software [29]. Using clear and simple language when wording variables’ labels, particularly when they form questions, would avoid confusion and facilitate the reviewers’ learning. More guidance on phrasing the data items and developing codebooks for SRs can be consulted [3, 41]. The categories of different variables should be predefined in an exhaustive and non-overlapping (i.e. mutually exclusive) way [41]; yet, for some variables, a complete list of categories cannot be anticipated. Creating separate lists of categories for such variables is recommended to add new or missed categories flexibly. An informative and well-structured data dictionary helps simplify the subsequent steps of the database building phase, ensures consistent responses among reviewers [41, 42] and enables the implementation of different data entry checks (Step 5). The variables should be listed in the same order as they would appear in the data entry forms.
Database building phaseThe database building phase forms the backbone of the DE guideline, where the conceptual database design gleaned from the planning phase turns into a physical database. Each entity turns into a database table, in which data are stored; each data item becomes a variable in this table, and data entry forms are also created in which data are keyed.
Step 5: create data entry formsThe data entry forms are the front interfaces that directly communicate with the reviewers; therefore, customisable and user-friendly forms are preferable. Data entry fields are created in each form, where reviewers enter data for individual data items. Generally, well-designed forms help minimise errors from miskeying or misclicking and reduce the time and effort spent extracting data [43]. Specifically, when the order of the forms and data entry fields closely follows the reporting flow of the information in the articles, they become easy to locate, and the number of cross-form moves is reduced. Relevant fields can also be logically grouped with suitable headings [6, 43]; for example, breed, age, inclusion and exclusion criteria can be gathered in one section of the form, so all information about the participants’ characteristics can be entered at once. A well-structured data dictionary (Step 4) minimises the time spent creating the forms [44] by directly guiding the development team to the appropriate field types (e.g. text, numeric, or dropdown lists) and other needed details.
Moreover, quality control checks, such as value range, field type and logic checks, help ensure compliance with data entry rules and reduce the likelihood of entry errors [44]. The value range checks are used for numeric fields with permissible ranges of answers, while field type checks verify that the data entered in a field are of the correct type; for instance, a decimal number will not be allowed in an integer-type field. Finally, logical relationships between fields can be set using if statements combined with conditional expressions (logic checks) to ensure logically consistent answers. For example, when the field “Nature of the infection” is answered as “Natural”, filling in the field “Challenge bacterial dose” gives an error message. Invalid answers for text fields can be much reduced using dropdown lists, even when permitting a free-text answer for an “other” category. Free-text fields can also be used to collect additional comments and capture direct verbatim quotes from the study whenever possible to support answers that can imply judgements in other fields [3].
Step 6: set up the databaseIn contrast to the flat-file databases, the DE tools based on relational databases comprise multiple structurally related tables where the data entered by reviewers reside [24, 39]. The relational database allows tables to be connected to each other using primary and foreign keys, as explained in Step 3. The user guide or manual of the software on which the development team decides must be consulted for setting up the database.
Step 7: pilot the DE toolTesting the initial version of the DE tool on a small set of eligible studies would help identify any entry difficulties such as (1) the tool is not working properly (e.g. program glitches), (2) improper storage of the data, (3) omission of the logic or range checks, (4) incorrect labelling of variables or categories of dropdown lists and (5) missing relevant data items [3, 7, 43]. Although previous literature did not specify a particular number of studies needed to test the DE tool, a purposive sample of studies with one or multiple outcomes whose data are reported in different ways is recommended [16].
Quantifying the agreement between reviewers during the piloting process and postponing the extraction until reaching a satisfactory agreement level have also been reported, albeit no specific agreement thresholds were recommended [45, 46]. However, the piloting might need to be iteratively repeated until no major changes in the tool are needed. The review team, including reviewers, statisticians and content experts, are encouraged to participate in piloting the DE tool. Problems with the tool may still surface after pilot testing; therefore, the review team needs to be notified of any further changes.
Step 8: documentation and reviewer trainingDetailed instructions on filling in the data fields and navigating among forms will increase the consistency of the extracted data between reviewers. We also advocate including illustrative examples in the tool manual to help reviewers learn and understand the data fields.
Training acquaints reviewers with the forms and helps solve any issues that may arise during the extraction [6, 7]. The training can be organised as a tutorial using a purposively selected sample of eligible studies. The involvement of the entire review team in training would allow for a comprehensive discussion between data extractors, clinicians and methodologists. Each data item should be carefully described during the training, and none should be overlooked or considered obvious.
Data manipulation phaseIn this phase, after the reviewers extract data from the studies included in the review, the data stored in the database tables are exported and combined into a single file. Then, the data need to go through some manipulation processes. In this phase, we assume that two reviewers would extract data independently from the same set of studies using two identical copies of the DE tool.
Step 9: data export and compilationFor each reviewer, the captured data are often individually exported from each database table and combined into a single data file. Even though data are exported as separate datasets, they can still be assembled using the identification (key) variables to make up a complete dataset. Exported datasets can be either combined through side-by-side merging using primary and foreign keys or concatenation, where one dataset is put at the end of another. Different statistical software can accomplish the data compilation procedures [47].
Step 10: data comparison and adjudicationThe end product of independent double data extraction is two datasets, one for each reviewer, that need to be compared to identify any discrepancies. Discrepancies are due to an unmatched number of observations (rows) or different values of observations per se. We do not advocate postponing the data comparison until after data have been extracted from all studies. Instead, we recommend more frequent comparisons using subsets of studies to limit the need to go back to the articles and re-extract data due to systemic errors in interpreting the data items. Further, a comparison of the entire dataset (i.e. all variables together) might not be manageable due to the different hierarchical levels where variables are recorded; therefore, splitting it into subsets of variables might be more feasible.
Data adjudication is when decisions are made to solve disagreements, and subsequent data edits occur. A third reviewer is often called upon to resolve disagreements, and the reconciliation procedure between reviewers should be reported [7].
Comments (0)