Protocol registration
In developing this protocol, the guidelines of the Preferred Reporting Items for Systematic reviews and Meta-analysis Protocols (PRISMA-P) were followed (Additional file 1) [27]. A summary of the protocol was registered on the International Prospective Register of Systematic Reviews (PROSPERO) (CRD42021271358). The conduct of the systematic review and meta-analysis will adhere to the Meta-analyses Of Observational Studies in Epidemiology (MOOSE) guideline [28].
Search strategy and terms
Searches for relevant reports will be conducted across the following databases: MEDLINE (Ovid), Embase (Ovid), PsycINFO (Ovid), Web of Science, and ProQuest. Additionally, we will expand our search to include a grey literature database (OpenGrey) and trial registries (ClinicalTrials.gov, International Standard Randomised Controlled Trial Number [ISRCTN] registry) for potential reports or ongoing or completed studies otherwise not identified in the five main databases. Furthermore, we will complement database searches with hand-searching from the reference list of eligible studies. A sensitive search strategy will be employed with an emphasis on identifying reports of NCI in PLWH. Additional file 2 provides sample search terms we developed for the Ovid databases. We will limit our search to reports published from 1 January 2007 up to 30 September 2023. The start date corresponds to the year of the publication of the revised nosology for HAND which recognizes asymptomatic manifestation of NCI in PLWH [8]. We extended the end date from initially on 31 May 2021 to ensure that the review remains current and up to date.
Eligibility criteria
Cross-sectional or observational cohort studies reporting counts or proportions diagnosed with NCI, or alternatively neuropsychological test performance scores as the basis for estimating such proportions, in both PLWH and HIV-seronegative participants will be included in the review. Reports of NCI proportions must encompass a full spectrum of NCI, including the following: asymptomatic neurocognitive impairment, HIV-associated mild neurocognitive impairment, and HIV-associated dementia [8]. We will exclude reports on paediatric populations (age < 12 years), reports with < 50 participants across HIV serostatus groups, assessments of < 2 of the recommended six neurocognitive domains [8], conference materials, other study designs (i.e. randomized trials or designs with predetermined selection of outcomes in either serostatus group), and studies enrolling historical controls.
Study selection
Records will be managed and stored using EndNote. After the removal of duplicates, editorials, and conference materials, two reviewers (A. P., G. H.) will independently screen the titles and abstracts of the remaining records, supervised and adjudicated by a third reviewer (A. R.) in cases of disagreement. We will contact study authors for reports to which we have no full access. Subsequently, two reviewers (A. P. A., A. R.) will assess the eligibility of each report in full text. The study selection process will be summarized in a PRISMA flow diagram [28].
Outcomes and measures
The primary outcome under investigation is the diagnosis of NCI by study definition. We anticipate a diversity of diagnostic criteria being used across the included studies, which may encompass the following: (a) the Frascati criteria (≥ 1 SD below the mean of normative test scores in ≥ 2 neurocognitive domains [8]); (b) the Gisslén criteria (≥ 1.5 SD below the mean of normative test scores [29]); (c) the global deficit score (the average of reclassified T scores on a 0 to 5 scale for all assessed neurocognitive domains, with a cut-off score exceeding 0.5 to delineate impairment [30]); (d) clinical rating scale (reclassified T scores on a 1 to 9 scale, with scores exceeding 5 in ≥ 2 domains to evidence impairment [30]); (e) multivariate normative comparisons (use of multivariate statistics to construct and compare profiles of test scores [31]); and (f) various cut-off criteria of instrument-specific screening analogues (e.g. Cogstate [32], International HIV Dementia Scale [33], Mini Mental State Examination [34], or Montreal Cognitive Assessment [35]).
The excess burden of NCI will be measured in prevalence ratios (PR), which is the ratio of NCI proportions in seropositive participants to seronegative participants. We will utilize the frequency of cases and non-cases or the reported proportions for each serostatus group to derive crude PR estimates or regression coefficients for adjusted PR estimates. Measures reported in odds ratio (OR) will be converted to PRs by dividing the OR by one minus the product of multiplying the NCI proportion in the seronegative group with the difference in the OR from unity [36].
Data extraction and management
We will classify reports that meet the eligibility criteria into two groups: (a) ‘MoHE-adjusted controls’, whereby ≥ 90% of both HIV-seropositive and HIV-seronegative participants share a single MoHE group, or (b) ‘MoHE-naive controls’, whereby the MoHE is either undefined or had a distribution of < 90% in either serostatus group. We will also record information on the following:
▪ Participant eligibility (e.g. exclusion due to pre-existing central nervous system disorders, major depression, or substance dependence)
▪ Demographics (age, sex, years of education)
▪ Comorbid conditions applicable to all participants (e.g. hepatitis C, depression)
▪ MoHE groups (e.g. men who have sex with men, people who use drugs or alcohol, people exposed to perinatal HIV infection) for reports of MoHE-adjusted controls
▪ HIV clinical characteristics (nadir CD4 counts, the proportions of HIV-seropositive participants on cART)
▪ Neurocognitive evaluation (i.e. evaluation test instrument, number of neurocognitive domains assessed, diagnostic criteria for NCI)
▪ The frequency of NCI or neuropsychological test scores by HIV serostatus
▪ Analytical adjustments (i.e. none, demographics, and/or comorbidities)
Two reviewers (A. P., A. R.) will independently extract these study-level characteristics and outcomes onto a pre-piloted form (Additional file 3), which will then be exported to a spreadsheet to facilitate analysis. The reviewers had been trained to use the extraction form. Disagreements will be resolved through discussion involving expert clinicians in neurocognition and HIV (A. P. A., Y. T.). For education reported in ordinal levels, we will assign a standard duration for each level, capped at university education if the highest reported level is ‘university or above’, to approximate the average years of education, weighted by the proportions completing each level. Similarly, if age groups are reported, we will calculate a weighted average age by assigning a midpoint to age groups other than the oldest category and a quarter of the range from the lower bound to the maximum reported age or to the life expectancy if no upper bound is reported for the oldest age group (e.g. 60 and above).
For reports involving participants in multiple strata, we will extract stratum-specific outcomes provided that each stratum has the required sample size of ≥ 50. Such reports will contribute more than one comparison to the dataset. If any stratum fails to achieve the required sample size, we will combine the participants and average the outcomes and cohort characteristics across the strata, weighted by stratum size or the inverse variance when extracting adjusted outcome measures. For instance, an article reports the numbers of HIV-seropositive and HIV-seronegative participants stratified by age group as follows: 22 and 21 for participants aged < 50 years (Stratum 1) and 25 and 26 for participants aged ≥ 50 years (Stratum 2). Since the size of Stratum 1 (n = 43) is less than 50, the combined data to extract will correspond to a single sample of 94 participants of mixed age groups, of whom 47 are HIV seropositive.
When there are multiple subgroups within an HIV serostatus group, we will extract data only from subgroups that are most similar to the other HIV serostatus group. For instance, if a study enrolled HIV-seropositive smokers and HIV-seronegative participants who did and did not smoke, only data from the HIV-seronegative smokers will be extracted for analysis. Subcohorts with nonoverlapping membership will be treated as independent observations. If unique membership between cohorts from the same study cannot be verified, either through the information provided in the text or from contacting the authors, the largest cohort will be selected for extraction.
We will employ two methods for extracting NCI outcomes. The first of these is direct extraction, which applies to articles reporting the frequency or proportions of NCI by serostatus group from which a measure of excess burden will be calculated. The second is indirect extraction and applies to articles reporting neuropsychological test scores or a summary test score. With indirect extraction, we will first convert the individual test Z scores to T scores (mean = 50, SD = 10) using the reported mean and standard deviation (SD), which will then be averaged over the individual neuropsychological tests and for each serostatus group. In the second step, these global T scores and the corresponding SDs will be used to construct a normal distribution of participant scores. We will then rescale this distribution to global deficit scores. NCI cases will be counts of participants with the global deficit score exceeding 0.5 by this diagnostic criterion [30]. When raw scores, rather than Z scores, are reported, we will standardize the test scores using HIV-seronegative participants as the normative population. If an article reports on more than one diagnostic instrument or criteria, we will extract only NCI outcomes from the neuropsychological test battery, as this is considered the diagnostic gold standard, or from the instrument and the diagnostic criteria that give the strongest evidence of a statistical difference. Only baseline NCI outcomes will be extracted from observational cohort studies.
We will contact study authors by email in three attempts over a 2-week period for clarifications on methodological aspects (e.g. study design, participant characteristics, methods to compute outcomes) that will allow us to better assess the eligibility of a report for inclusion or for missing statistics (e.g. unreported standard deviations) required for meta-analysis. In the event that the contacted authors provide an insufficient response, a consensus judgment will be exercised to determine eligibility or imputation of missing statistics will follow (see below).
Assessment of risk of bias
Risk of bias will be assessed using an adapted Newcastle–Ottawa scale. This adapted version incorporates the design elements specific to cross-sectional studies [37] and includes modifications to refine question items for more relevance to HAND (Additional file 4). The scale comprises seven items organized into three bias domains (participant selection, comparability, and outcomes), with a maximum possible score of nine for studies with a very low risk of bias. Study quality will be divided into ‘good’ (low risk of bias: scores of 3–4 in selection, 1–2 in comparability, and 2–3 in outcomes), ‘fair’ (medium risk of bias: scores of 2 in selection, 1–2 in comparability, and 2–3 in outcomes), and ‘poor’ (high risk of bias: scores of < 2 in selection, 0 in comparability, or < 2 in outcomes). Two reviewers (G. H., G. M.) will independently conduct the quality assessment, with a third reviewer (A. R.) available to adjudicate in the event of any disagreements.
Data synthesis
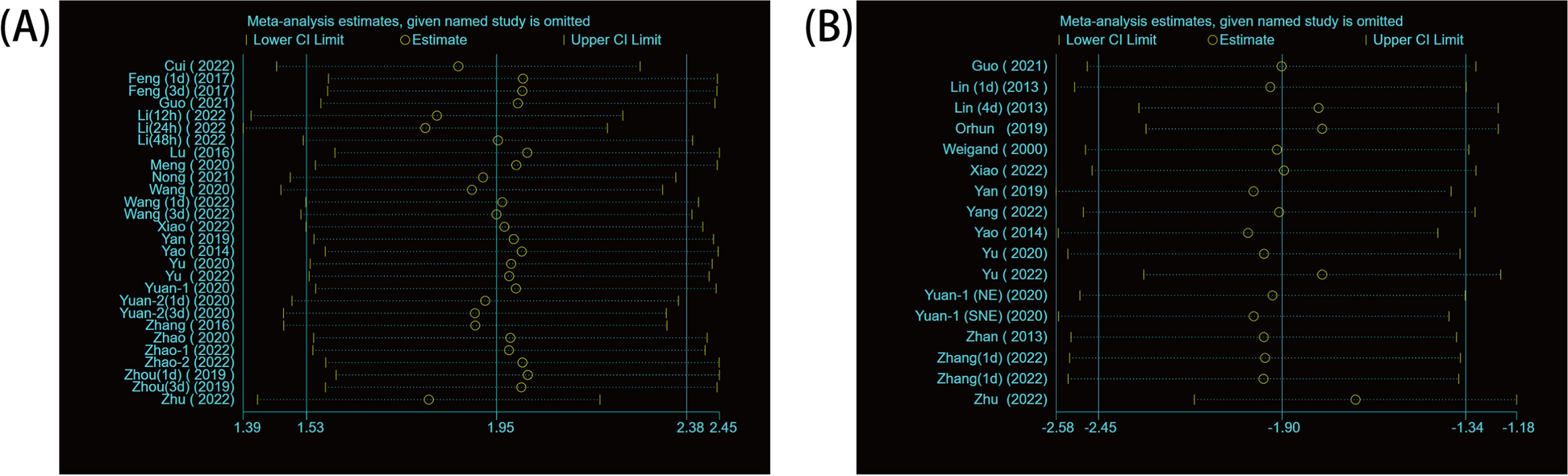
We will first describe the included reports and summarize key study-level characteristics. Next, we will pool the PRs from all eligible studies using the inverse-variance random-effects method of meta-analysis (DerSimonian-Laird) with the Knapp-Hartung adjustment for standard errors [38], stratifying the results by whether or not the studies utilized MoHE-adjusted controls. The Cochran’s Q and I2 statistics will be computed to assess the heterogeneity of the pooled PRs. An I2 value exceeding 50% is taken to indicate substantial heterogeneity [39]. Hypothesis testing of a difference in the pooled PRs from studies with MoHE-adjusted controls and MoHE-naive controls will be performed. We will assess the effect of influential studies by removing studies one at a time or in pairs, whereby one MoHE-adjusted study and one MoHE-naive study are removed simultaneously until all possible pairs are exhausted and re-pooling the PRs from the remaining study population.
We will assess small-study effects by evaluating the symmetry in the distribution of log PRs through visual inspection of a funnel plot and by statistical testing using the Egger’s test for MoHE-adjusted studies and MoHE-naive studies [40]. The Duval and Tweedie trim-and-fill technique will be used to adjust the pooled PRs in the presence of small-study effects (P ≤ 0.100) [41].
In accordance with the MOOSE guideline [28], exploratory analyses of subgroups and potential moderators will be performed and detailed as follows. We will perform subgroup analyses by study location (World Health Organization regions), age groups (mean age < 50 vs. ≥ 50 years), whether the study exclusively enrolled comorbid participants, outcome extraction (direct vs. indirect), NCI diagnostic criteria, and whether the PRs were adjusted for demographics (age, sex, education) and/or any comorbidities. For each level of a subgroup, we will compare the pooled PRs between MoHE-adjusted studies and MoHE-naive studies using the Q test for between-group differences. However, we acknowledge that these statistics may be inestimable or unreliably estimated in a number of subgroups due to sparse studies in either MoHE category.
Finally, we will conduct random-effects meta-regression to explore factors that may modify the pooled PRs. We will consider both continuous and ordinal study-level covariates, including mean age, nadir CD4 count, the proportion of HIV-seropositive participants on cART, number of assessed neurocognitive domains, and study-quality ranking. Because we anticipate fewer studies than would be typically required for multivariate analysis, the effects of these covariates on the pooled PRs will be assessed separately. Where possible, we will further classify MoHE-adjusted studies into behavioural exposure (e.g. men who have sex with men, people who use drugs or alcohol, high-risk heterosexuals) and nonbehavioural exposure (e.g. haemophiliac patients, people who were exposed to HIV perinatally) or similar distinctions to contrast the effects of different MoHEs on the excess burden of NCI. Missing covariate values will be imputed by the average value from the remaining studies sharing the same location and, for MoHE-adjusted studies, MoHE group.


Comments (0)