Study design and dataset generation
The data used in this study were derived from the 1999–2002 National Health and Nutrition Examination Survey (NHANES). NHANES is an ongoing national program overseen by the National Center for Health Statistics under the Centers for Disease Control and Prevention, focusing on US non-institutionalized civilians. NHANES utilizes a complex, multistage probability sampling design, integrating face-to-face interviews, physical examinations, and laboratory tests to collect data. For this study, we included 1,199 eligible participants. Detailed description of the inclusion/exclusion criteria is provided in eFigure 1.
NHANES received ethical approval from the National Center for Health Statistics Ethics Review Board, and all participants provided written informed consent. This study was followed the Strengthening the Reporting of Observational Studies in Epidemiology reporting guideline (eTable 1).
Outcome definition
The primary outcome in this study was all-cause mortality. Secondary outcomes included cardiovascular and non-cardiovascular mortality. The date and cause of death were linked to National Death Index records through December 31st, 2019. We used the 10th revision of the International Classification of Diseases to determine the cause of death. The participants were followed from the date of their survey participation until death or the end of the follow-up period.
Laboratory methodology
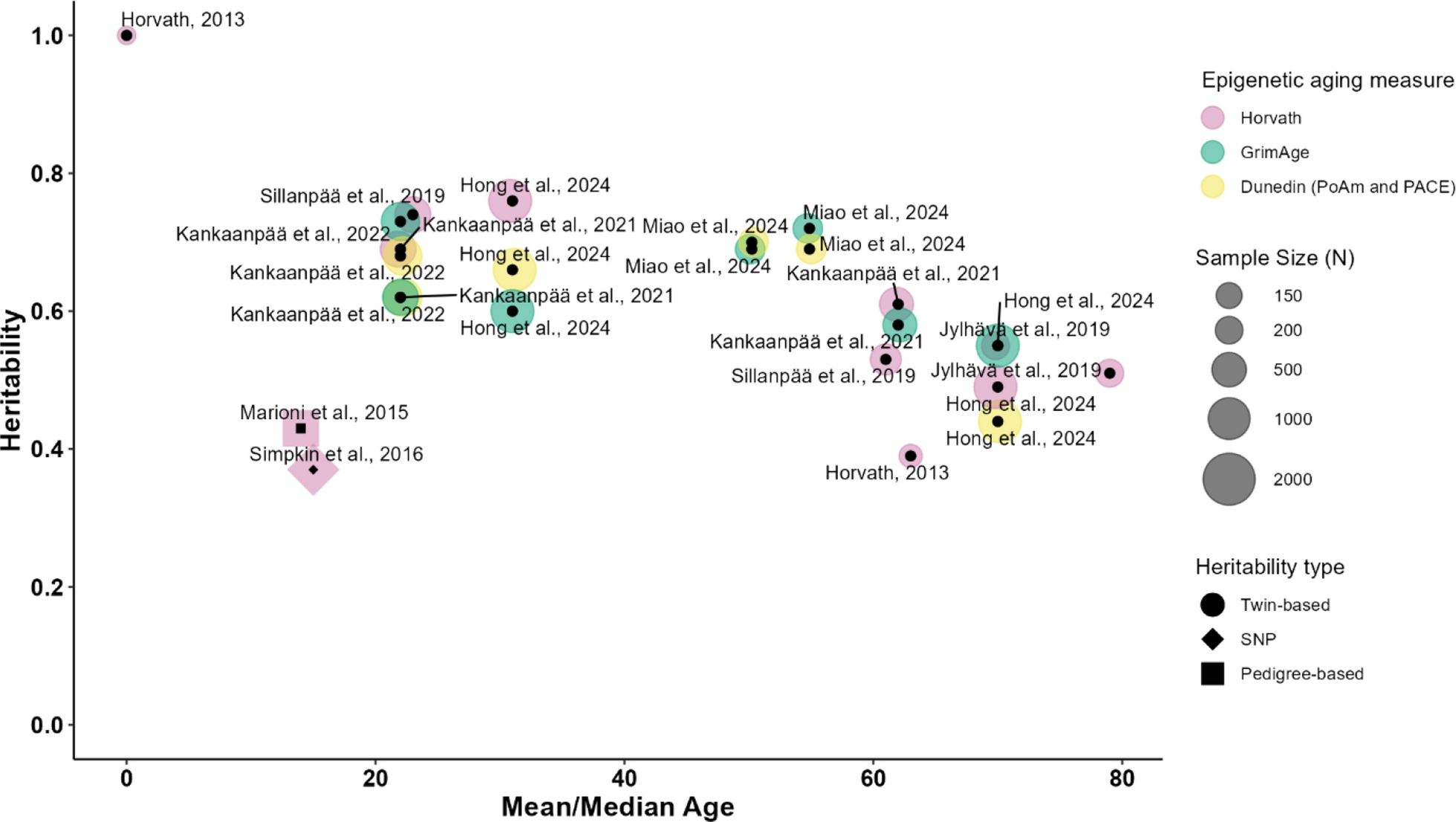
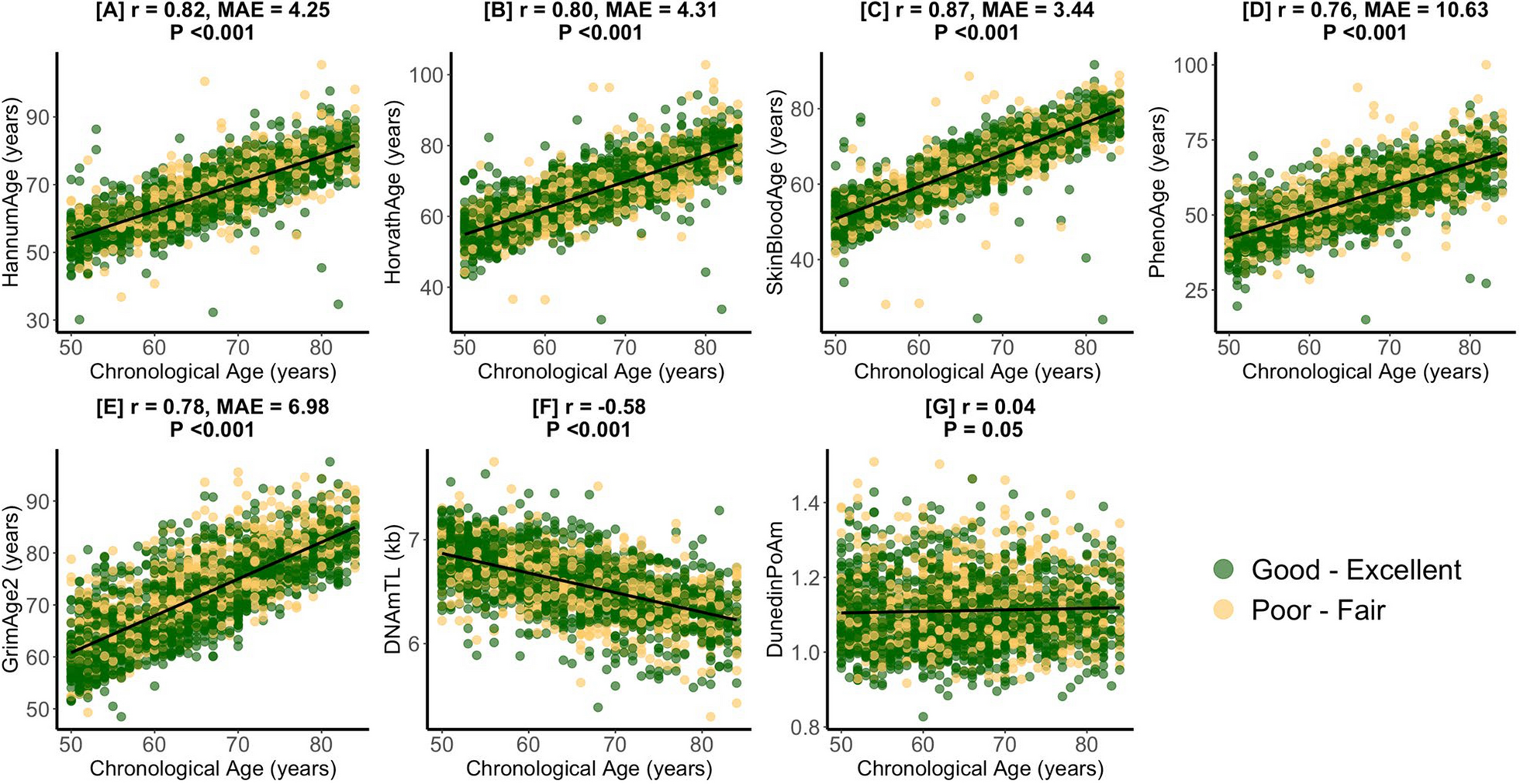
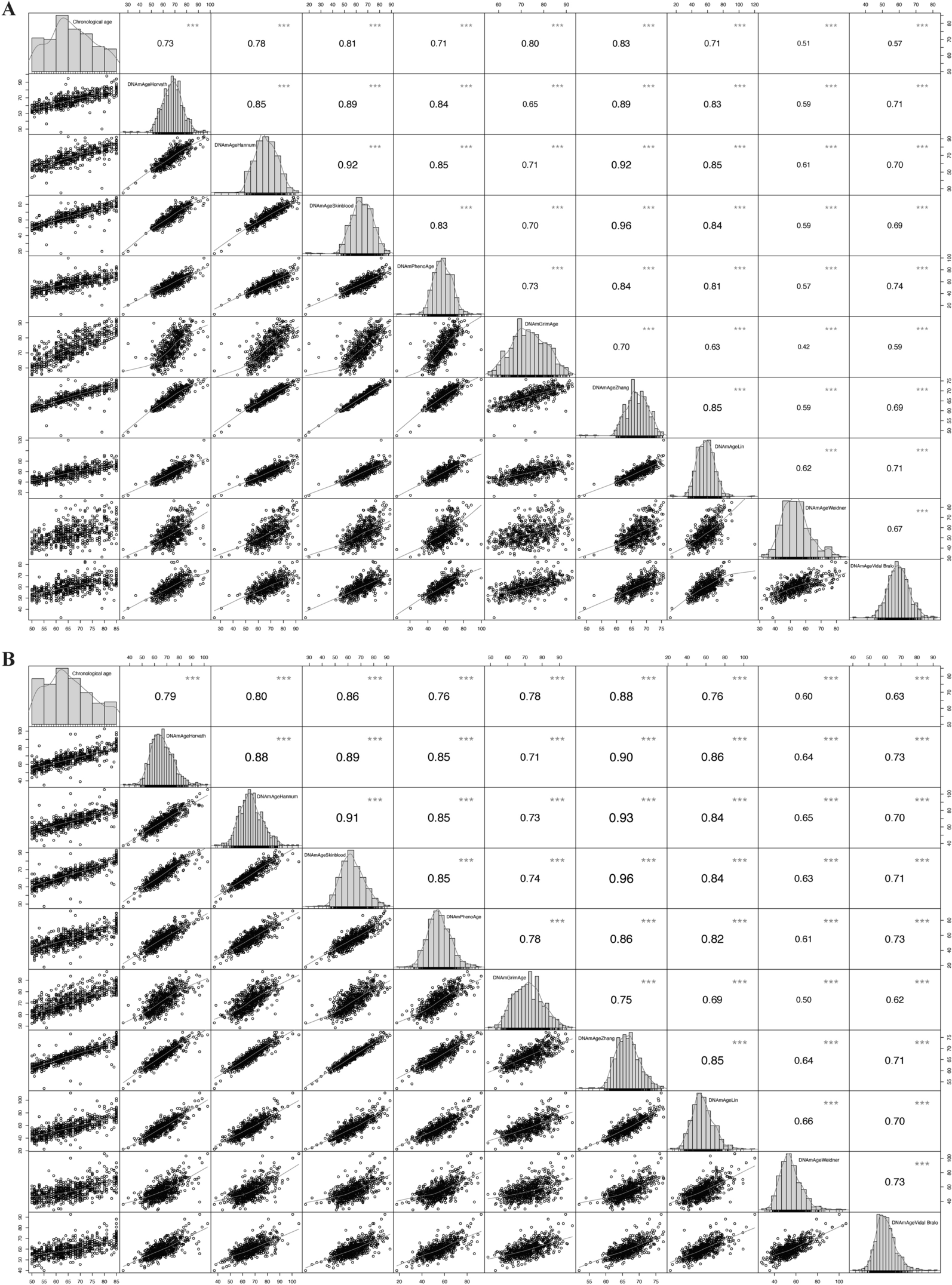
DNA was extracted from whole blood and stored at −80 °C. Bisulfite conversion was performed on 500 ng of DNA using the Zymo EZ DNA Methylation Kit (cat# D5001, Zymo Research, Irvine, CA, USA). Methylation profiling was conducted using the Illumina Infinium MethylationEPIC BeadChip v1.0 (cat# WG317-1001, Illumina, San Diego, CA, USA), following standard protocols for hybridization, amplification, and labeling. The raw methylation data underwent quality control procedures, including outlier detection, imputation, and normalization, and were subsequently used to generate epigenetic biomarkers based on established algorithms: HorvathAge [8], HannumAge [9], SkinBloodAge [23], Vidal-BraloAge [24], WeidnerAge [25], PhenoAge [10], ZhangAge [11], LinAge [26], GrimAge2Mort [12], and DunedinPoAm [13]. Additional details on the DNA-methylation data processing are available at https://wwwn.cdc.gov/nchs/nhanes/dnam/.
These DNAmAge algorithms can be categorized into first-generation, second-generation, and third-generation clocks, each with distinct methodologies, biological focuses, and applications. First-generation clocks (e.g., HorvathAge, HannumAge, SkinBloodAge) predict chronological age using DNAm patterns. Second-generation clocks (e.g., PhenoAge, ZhangAge, LinAge) incorporate health-related biomarkers to estimate biological age and assess disease risk. Third-generation clocks (e.g., GrimAge2Mort) integrate disease-related biomarkers and longitudinal data to predict mortality risk and the pace of biological aging (e.g., DunedinPoAm). These algorithms differ in their CpG site selection, which may reflect unique biological pathways or tissue-specific methylation patterns, and were trained on diverse datasets, ranging from multi-tissue samples (e.g., HorvathAge) to blood-specific samples (e.g., HannumAge) or longitudinal cohorts (e.g., DunedinPoAm). These differences in CpG site selection, training datasets, prediction targets, and biological focus collectively contribute to the variations observed among DNAmAge values. Detailed procedures for each DNAmAge algorithm are provided in the Supplemental eMethods. In this study, DNAmAA was calculated as the residuals from the regression of DNAmAge on chronological age, as described in the previous work [2, 7].
Variables collection
In addition to variable related to DNAmAA, we collected a range of variables for analysis including chronological age, sex, body mass index (BMI), race and ethnicity, poverty-to-income ratio (PIR), smoking status, systolic blood pressure, diastolic blood pressure, systemic immune inflammation index (SII), Oxidative Balance Score (OBS), Life’s Simple 7 (LS7) score, frailty score, Geriatric Nutritional Risk Index (GNRI), comorbidities (atherosclerotic cardiovascular disease [ASCVD], hypertension, hypercholesterolemia, chronic kidney disease [CKD]), hemoglobin A1c, total cholesterol, high-density lipoprotein cholesterol, estimated glomerular filtration rate (eGFR), urine albumin-to-creatinine ratio (UACR).
Race and ethnicity were categorized as non-Hispanic White, non-Hispanic Black, Mexican American, Hispanic and other race (which included participants who identified as non-Hispanic multiracial). Race and ethnicity data were collected as a confounding factor to account for differences among racial and ethnic groups in susceptibility to diabetes, pre-diabetes, and related health outcomes. Therefore, controlling for race and ethnicity helps ensure that any observed associations between DNAmAA and mortality are not confounded by these factors.
SII, calculated as (platelet count × neutrophil count)/lymphocyte count, is a marker of systemic inflammation and immune response. It has been associated with increased risks of chronic diseases and mortality, making it a valuable prognostic tool [28]. OBS is a composite measure of pro-oxidant and antioxidant exposures, including dietary and lifestyle factors. Higher OBS values indicate a greater antioxidant capacity, which has been linked to reduced risks of oxidative stress-related conditions, such as cardiovascular disease and diabetes [29]. LS7, developed by the American Heart Association, is a composite score based on seven modifiable cardiovascular health factors, including smoking, diet, and physical activity. Higher LS7 scores are associated with better cardiovascular health and reduced risks of diabetes and mortality [30]. Frailty index was developed by Searle and colleagues and constructed using 40 variables associated with health status, covering multiple physiological systems, This approach generates a continuous score ranging from total fitness (0) to total frailty (1), providing a comprehensive measure of an individual’s vulnerability to adverse health outcomes [31]. GNRI is a nutritional assessment tool calculated from serum albumin levels, body weight, and height. It is widely used to evaluate malnutrition risk in older adults and has been associated with mortality, frailty, and other adverse health outcomes [32]. Detailed definitions of these covariates are provided in Supplemental eMethod.
Statistical analysis
NHANES initially employed a complex survey design, with all results weighted to yield estimates that are nationally representative of the non-institutionalized civilian population of the USA. In this study, we used the ‘WTDN4YR’ weights from the NHANES 1999–2000 and 2001–2002 DNA-methylation array and epigenetic biomarkers dataset for analysis. Data analysis was conducted between August 1st and October 14th, 2024.
The extent of missing data for each variable is detailed in eTable 2, with PIR exhibiting the highest proportion of missing values at 11.59%, whereas other variables demonstrated missing rates between 0.1% and 0.5%. To address these missing data, we employed the ‘mice’ package in R for multiple imputation using chained equations. A total of 20 imputed datasets were generated through iterative imputation. For each variable, we selected the imputed dataset that minimized the relative difference between the imputed mean and the original mean of the incomplete data. These selected values were combined to construct a single complete dataset, which was used for all subsequent analyses. For the descriptive statistics, continuous variables are expressed as mean (standard deviation [SD]), and categorical variables are expressed as numbers and percentages. Pearson’s correlation analysis was performed to analyze the relationships between chronological age with each DNAmAge and each DNAmAA, and the correlation coefficients (r) were given. Additionally, the relationships between each DNAmAA with laboratory indicators (e.g., eGFR, UACR), multidimensional scores (e.g., SII, OBS), and vital signs were analyzed by partial correlation analysis adjusted by chronological age, sex, and smoking, and the r values were given.
We examined whether each DNAmAA and covariates met the proportional hazards assumption of the Cox proportional hazards model. We adjusted for confounders (including chronological age, sex, race and ethnicity, PIR, smoking status, BMI, GNRI, ASCVD, hypertension, hyperlipidemia, and CKD). These covariates were selected based on literature, clinical relevance, and our data characteristics [33]. Laboratory indicators (e.g., CRP, HbA1c) and multidimensional score (e.g., OBS, SII) were not included into models due to potential multicollinearity with DNAmAA. We reported hazard ratios (HR) with 95% confidence intervals (CI) for each 5-unit increase in the DNAmAAs and for 10% increases in the DunedinPoAm pace of aging to quantify the associations between each DNAmAA and mortality outcomes. For DNAmAAs significantly associated with all-cause mortality, these variables were also analyzed categorically in tertiles, with the first tertile serving as the reference for calculating HRs and 95% CIs. To further validate the robustness of our findings, we conducted the following sensitivity analyses. First, we adjusted for all variables listed in Table 1 in the Cox regression model to account for their potential influence on the association between each DNAmAA and mortality outcomes. Second, we excluded participants with missing data to minimize the impact of missing values on the results. Finally, we removed participants who died within the first two years of follow-up to reduce the risk of reverse causality.
Table 1 Baseline characteristics of all participants categorized by survival statusGiven the significance of AgeAccelGrim2 and DunedinPoAm in predicting mortality, we compared their predictive performance using DeLong’s test, evaluating the area under the curve of the receiver operating characteristic curves across overall participants, as well as subgroups with diabetes and pre-diabetes. Our results indicate that AgeAccelGrim2 shows a stronger predictive advantage over DunedinPoAm for all-cause mortality (eFigure 2). We conducted restricted cubic spline (RCS) analyses with three knots to examine potential nonlinear associations between AgeAccelGrim2 and mortality outcomes. Subgroup analyses were performed to evaluate the association between AgeAccelGrim2 and all-cause mortality, stratified by chronological age (≥ 65 and < 65 years), sex (male and female), and BMI (≥ 30 and < 30 kg/m2). We also evaluated the predictive effect of AgeAccelGrim2 on mortality in non-diabetic/non-pre-diabetic populations to compare whether differences exist relative to diabetic populations.
We investigated the potential mediating role of AgeAccelGrim2 in the association between health-related exposures (in diabetes population: HbA1c, eGFR, OBS, LS7, frailty; in pre-diabetes population: OBS, LS7, frailty) and all-cause mortality using the mediation package in R. As AgeAccelGrim2 serves as a biomarker of biological aging, reflecting accumulated physiological damage, its use as a mediator helps elucidate how health-related factors influence mortality risk by accelerating or decelerating epigenetic aging. Adjusted models were applied, and mediation analyses with 500 bootstrap resamples were conducted to estimate the direct and indirect effects of AgeAccelGrim2.
All analyses were conducted using R version 3.5.2 (R Project for Statistical Computing, Vienna, Austria). P values were two-tailed, and < 0.05 was considered statistically significant.





Comments (0)