Breast cancer is the most common cancer among women and one of the leading causes of cancer-related deaths in women worldwide [18, 19]. Among the adverse effects associated with chemotherapy regimens for breast cancer, bone marrow suppression is the most frequent toxicity associated with docetaxel and is a key factor influencing the duration and dosage of chemotherapy [20]. In recent years, artificial intelligence technologies, particularly machine learning algorithms that incorporate statistical models and prior knowledge, have demonstrated strong performance in predicting ADRs [21]. Therefore, investigating the risk factors for severe bone marrow suppression caused by docetaxel-based chemotherapy in breast cancer patients and developing predictive models based on machine learning have significant clinical value.
Major findings and interpretations
This study identified a 47.9% incidence of severe bone marrow suppression in breast cancer patients undergoing docetaxel-based chemotherapy, consistent with previous reports on the hematologic toxicity of taxane-containing regimens [22, 23]. The analysis highlighted three independent risk factors: low absolute lymphocyte count, decreased WBC count, and low prealbumin level prior to chemotherapy. These findings suggest that impaired baseline hematologic and nutritional status significantly increases the risk of severe bone marrow suppression.
Low WBC and lymphocyte count prior to chemotherapy are indicative of compromised hematopoietic and immune systems, which makes patients more susceptible to chemotherapy-induced myelosuppression. Prior studies have demonstrated that lower pre-treatment WBCs counts correlate with an increased risk of hematologic toxicity and treatment delays [24, 25]. Additionally, lymphocyte count has been recognized as a key marker of immune competence and tumor response [26,27,28]. It is worth noting that declining lymphocyte counts are also associated with poor prognosis and reduced treatment tolerance in metastatic breast cancer [29, 30]. Our findings reinforce the role of lymphocyte and WBC counts as easily accessible clinical markers for identifying high-risk individuals.
Prealbumin level, a sensitive marker of nutritional status and hepatic synthetic function, has emerged as an important predictor. Malnutrition has been consistently linked to impaired cellular immunity and higher susceptibility to infections and toxicities during chemotherapy [31,32,33]. The short half-life of prealbumin makes it an early indicator of changes in nutritional status. Previous research suggests that malnourished patients often experience worsened treatment-related outcomes, including an increased incidence of bone marrow suppression [34]. Our data support the integration of prealbumin monitoring with pre-chemotherapy assessments to guide nutritional intervention strategies.
Model interpretation and implications
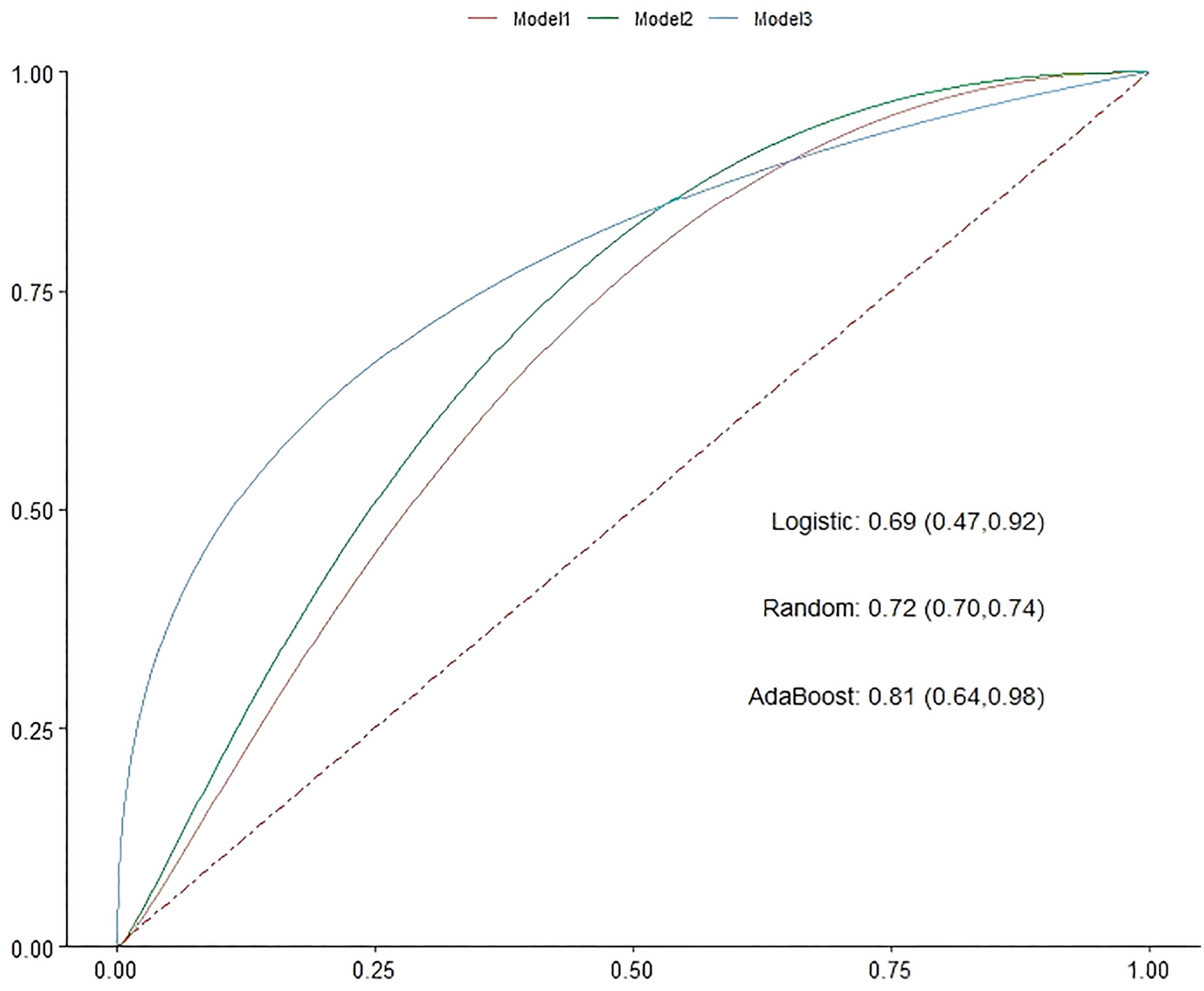
Three modeling approaches were employed to enhance the predictive capabilities: logistic regression, random forest, and Adaboost. Among them, AdaBoost showed the highest AUC (0.81) and specificity (94%), indicating superior overall performance in identifying patients at a high risk of bone marrow suppression. The random forest model had the highest sensitivity (83%) and narrowest confidence interval (0.70–0.74), suggesting better robustness and generalizability. Logistic regression, while inferior in performance (AUC = 0.69), provided clinical interpretability and risk quantification via odds ratios.
This comparative analysis highlights the clinical utility of machine learning methods in oncology. Whereas traditional models rely on linear associations, ensemble methods such as AdaBoost and random forest can integrate non-linear, high-dimensional interactions among clinical features. Such capabilities are particularly valuable in predicting complex adverse events such as myelosuppression. Nevertheless, for bedside applications, logistic regression remains useful because of its simplicity, transparency, and ease of integration into risk calculators and electronic medical record systems.
Clinical implications
This study offers a practical foundation for individualized patient risk stratification before initiating docetaxel-based chemotherapy. Patients with a low lymphocyte count, low WBC, and low prealbumin levels may benefit from intensified monitoring, prophylactic granulocyte colony-stimulating factor (G-CSF) administration, nutritional support, or modified chemotherapy regimens. Integration of machine learning-based models into clinical workflows could enhance the early identification of high-risk patients, optimize treatment decisions, and prevent avoidable complications. The AdaBoost model, with a high specificity of 94%, can be integrated into clinical workflows using a stepwise approach. During pre-chemotherapy evaluation, clinicians input baseline indicators, lymphocyte count, WBC count, and prealbumin level, into a model-embedded system that automatically generates a risk score for severe bone marrow suppression. This score supports decision-making: low-risk patients, accurately identified by the model, can proceed with standard monitoring, avoiding unnecessary interventions, while high-risk patients receive prioritized care such as more frequent blood tests or preemptive G-CSF administration. Future steps could include developing a clinical decision support tool or web-based calculator using the final model to facilitate its implementation in routine oncology practice. Such a tool would streamline the risk scoring process, allowing real-time calculation during patient consultations and seamless integration with electronic medical records to track risk stratification outcomes. These findings advocate the routine inclusion of nutritional assessments and immune profiling prior to initiating chemotherapy in patients with breast cancer.
Strengths and limitations
A major strength of this study is the comprehensive comparison of the three different predictive algorithms using a real-world clinical dataset. Furthermore, the incorporation of both hematological and nutritional variables enhanced the clinical relevance of the model. We adopted fivefold cross-validation repeated 50 times as the primary evaluation strategy instead of splitting the small dataset into independent training and testing sets, which helps to mitigate the instability in performance metrics caused by a small sample size to a certain extent.
This study has several limitations. First, as this was a single-center retrospective study with a small sample size (n = 119), it is challenging to develop and validate robust machine learning models. Specifically, splitting the dataset into training (80%) and testing (20%) sets would result in only 24 test samples, which increases the risk of overfitting and limits the reliability of performance metrics (e.g., AUC, sensitivity). Without strict sample size calculation, the statistical test power may be limited, potentially failing to identify associations with small effect sizes. This small sample size hinders capturing population characteristics and model learning of potential patterns, reducing robustness. It also fails to cover clinical scenario diversity, restricting generalizability to other populations or settings. Meanwhile, the limited number of samples cannot fully cover the diversity of clinical scenarios, which may restrict the generalizability of the model when applied to other populations or clinical settings. Thus, the generalizability and robustness of the machine learning models may be limited, warranting external validation with larger multicenter datasets. Second, despite five-fold cross-validation and repeated training (50 times), overfitting cannot be ruled out, particularly with ensemble models that may underperform in real-world settings [35,36,37]. Third, bone marrow suppression was graded using the WHO criteria, which may lack the granularity of newer toxicity scales. Fourth, retrospective data are prone to selection bias due to different collection standards, and unrecorded factors or confounding variables may interfere with the results. Finally, although the models show clinical potential, they have not yet been integrated into user-friendly platforms such as web-based tools or electronic medical records. Future studies should prioritize conducting external validation using large-sample prospective cohorts, utilize multi-center datasets, and at the same time focus on application in clinical workflows.


Comments (0)