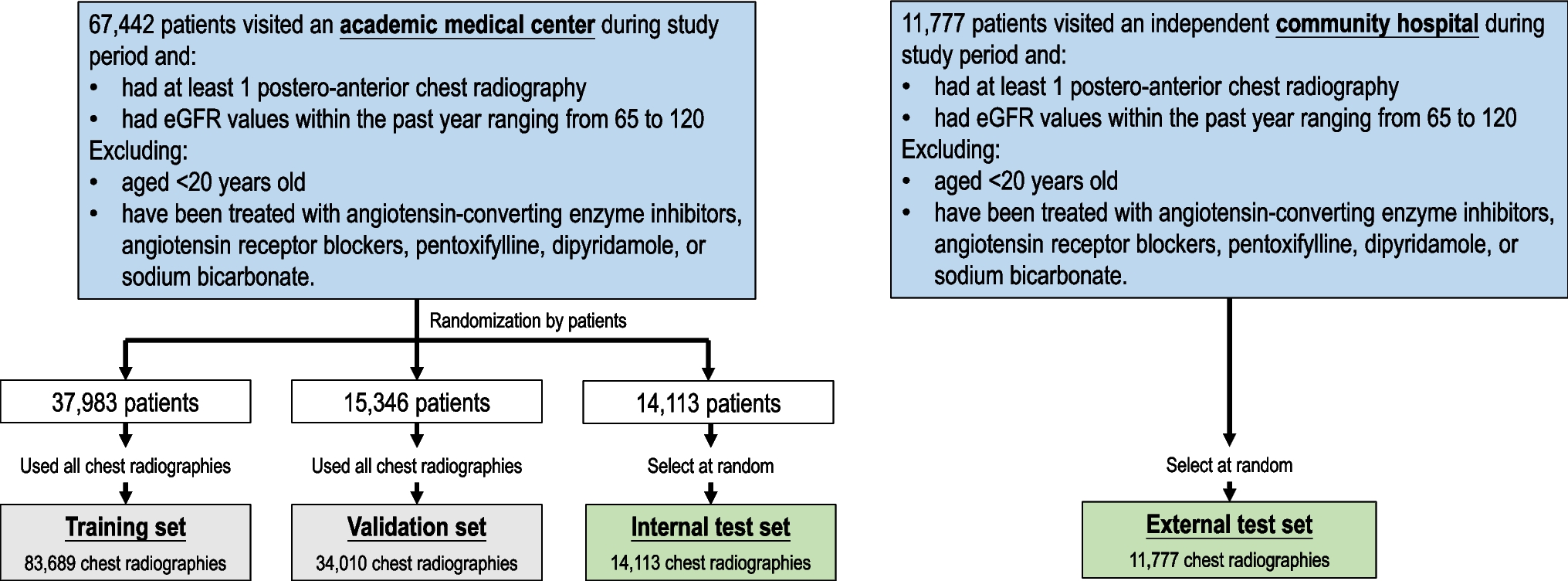
Datasets
MIMIC-CXR
is an open dataset consisting of 377,110 chest X-rays associated with 227,827 imaging studies from 65,379 patients. MIMIC-CXR is collected from the inpatient setting of Beth Israel Deaconess, a Boston hospital (refer Table 1). The test split of this dataset (Test Split MIMIC-CXR), which consists of 5159 studies with 293 patients, served as the hold-out set analysis [8].
VA-CXR
is a private dataset of 259,361 chest X-rays associated with 91,020 imaging studies from 35,771 patients. VA-CXR is collected in the outpatient setting of the Boston Veterans Healthcare Administration station (refer to Table 1). The ground truth labels were extracted from the VA’s corporate data warehouse (CDW) and joined with images using patient information from DICOM headers as published in Knight et al. [23].
Ground Truth Label Extraction
We used the CheXbert labelers [9] to expertly assign labels to 14 specific labels (atelectasis, cardiomegaly, consolidation, edema, enlarged cardiomediastinum, fracture, lung lesion, lung opacity, no finding, pleural effusion, pleural other, pneumonia, pneumothorax, support devices) associated with different chest conditions from radiology reports. CheXbert is a BERT-based approach that automates the detection of these observations, effectively streamlining the process of annotating medical images and reports. The NLP label extraction outputs scores for four classes: positive, negative, blank, and uncertain, associated with each of the 14 labels. As the class names indicate, for example, for pneumonia, positive class: radiology report indicates that the patient has pneumonia; negative class: radiology report indicates that the patient does not have pneumonia; uncertain class: radiology report mentions pneumonia, but the NLP tool is unable to determine if it is positive or negative; blank class: radiology report does not mention pneumonia.
Label Validation
Because ground truth assignment ultimately determines the accuracy of the imaging classifiers, we developed an image evaluation procedure in two steps. First, we evaluated the agreement between the NLP label extraction tool, CheXbert, and its precursor, CheXpert [10], a rule-based tool. We focused on positive class agreements for our evaluation, using only positive classes for classification, and have combined uncertain/negative class agreements. The disagreement between NLP label extraction tools indicates ambiguity/less confidence on the labels, ultimately creating an unreliable ground truth. The agreement is measured for both MIMIC-CXR and VA-CXR datasets. Of note that neither of the datasets was used to train the NLP extraction tools.
Relation to Diagnoses Codes
To validate the ground extracted from CheXpert-labeler, we analyzed the relationship of specific ground truth labels to ICD codes in the patient’s electronic health record (EHR) extracted from the VA’s Corporate Data Warehouse (CDW). The assignment of ICD-9 and ICD-10 diagnosis codes associated with each condition was exploratory and not extensively optimized.
Starting concepts were retrieved from the CheXpert-labeler github repository, where phrases they used to search notes can be found at https://github.com/stanfordmlgroup. These phrases, along with our own expertise, were used to identify diagnosis codes and cross-reference radiology reports with diagnoses. For example, pneumonia was identified by CheXpert-labeler as indicated by pneumonia, infection, infected process, and infectious; edema was indicated by terms edema, heart failure, chf, vascular congestion, pulmonary congestion, indistinctness, and vascular prominence; fracture was indicated solely by the word fracture; and pneumothorax was identified by either pneumothorax or pneumothoraces.
This method enabled us to validate the ground truth labels by correlating them with the relevant ICD codes in the patients’ EHRs, ensuring accurate cross-referencing of radiology reports with diagnoses.
For instance, the ICD-9 codes we used to indicate a pneumonia diagnosis in the outpatient diagnosis tables ranged from 480 to 486 and included 487.0. These codes encompass viral, bacterial, and other types of pneumonia, as well as pneumonia caused by unspecified pathogens. A similar approach was applied to ICD-10 codes for pneumonia and other conditions. The specific ICD codes used for each condition are detailed in Appendix Table 6.
Multi-Label Image Classification
Using the 14 labels extracted from the corresponding radiology reports with CheXbert, we created a multi-label image classification model from X-ray images (as shown in Fig. 1). We used a pre-trained DenseNet model [11] as the core framework, removed the top classification layer, and integrated a custom classification layer for multi-label output. Previous work shows the effectiveness of different resolutions of DenseNet121-based multi-label classification chest X-ray model on MIMIC-CXR dataset [12]. This work uses the MIMIC-CXR trained DenseNet-121 model on chest X-ray pre-processed into 256x256 JPG images [8, 13]. We also compare the MIMIC-CXR trained DenseNet-121 model with category-wise fine-tuning (CFT) [14]. CFT model is trained based on CheXpert dataset [10], and it was listed as the best performing model on CheXpert as of Jan ’24 [15].
Metrics
We evaluated our models using the area under the curve (AUC). The AUC score was calculated separately for each of the 14 labels, indicating the separability measure for a given chest X-ray label. We also analyzed the difference in AUC scores between MIMIC-CXR and VA-CXR, and the prevalence for each label was calculated as the number of studies with positive results for a given label divided by the total number of labels, indicating the label’s presence in the given cohort.
Table 2 Groundtruth analysis: agreement and disagreement rates between CheXpert and CheXbert across 14 classification labelsDomain Shift Analysis
We compared our source and target datasets along different dimensions: (1) Demographic details: age at time of imaging study, sex; (2) imaging study details: study year, view point (lateral view (Lat), erect anteroposterior (AP), posteroanterior (PA)); (3) ground truth labels: 14 labels. All the factors were analyzed against the accuracy of multi-label image classification. The impact can be estimated by comparing the prevalence of the above-listed factors across source and target domains with the performance of the multi-label classification. The subgroup analysis is performed on unseen datasets: Test Split MIMIC-CXR and VA-CXR.
Study Year Analysis
We obtain the study year from VA-CXR studies date reported in DICOM headers. The MIMIC-CXR dataset is unidentified; study years are replaced by anchor years. The comparison of performance across study years between the datasets is not possible, so we do not present a study year analysis on the MIMIC-CXR dataset.
Performance Analysis Based on Sex
We obtain the sex of the patients in VA-CXR from the VA’s corporate data warehouse (CDW) and the patients in MIMIC-CXR from the metadata. Sex is only classified into binary classes of male and female. We analyze the label-wise performance for each sex across both datasets.
View Position Analysis
We obtain the view position of the images from the DICOM metadata. We use four main viewpoints for analysis: lateral view (Lat), erect anteroposterior (AP), posteroanterior (PA)) and left lateral view (LL). We compare the label-wise performance across both datasets
Age Group Analysis
We define the age of the patient as the age when the imaging study was performed. For VA-CXR, this age was calculated from the date of birth obtained from VA CDW and the date of imaging study from DICOM metadata. For MIMIC-CXR, we calculated age using the anchored date of birth and anchored imaging study date. The anchored dates were amended in a manner that the difference in years is constant, so we were able to approximate the age of the patient. The label-wise performance for both datasets was compared across six age groups: (0–50], (50–60], (60,70], (70,80], (80,90], and (90,100].

Comments (0)