
Remember me
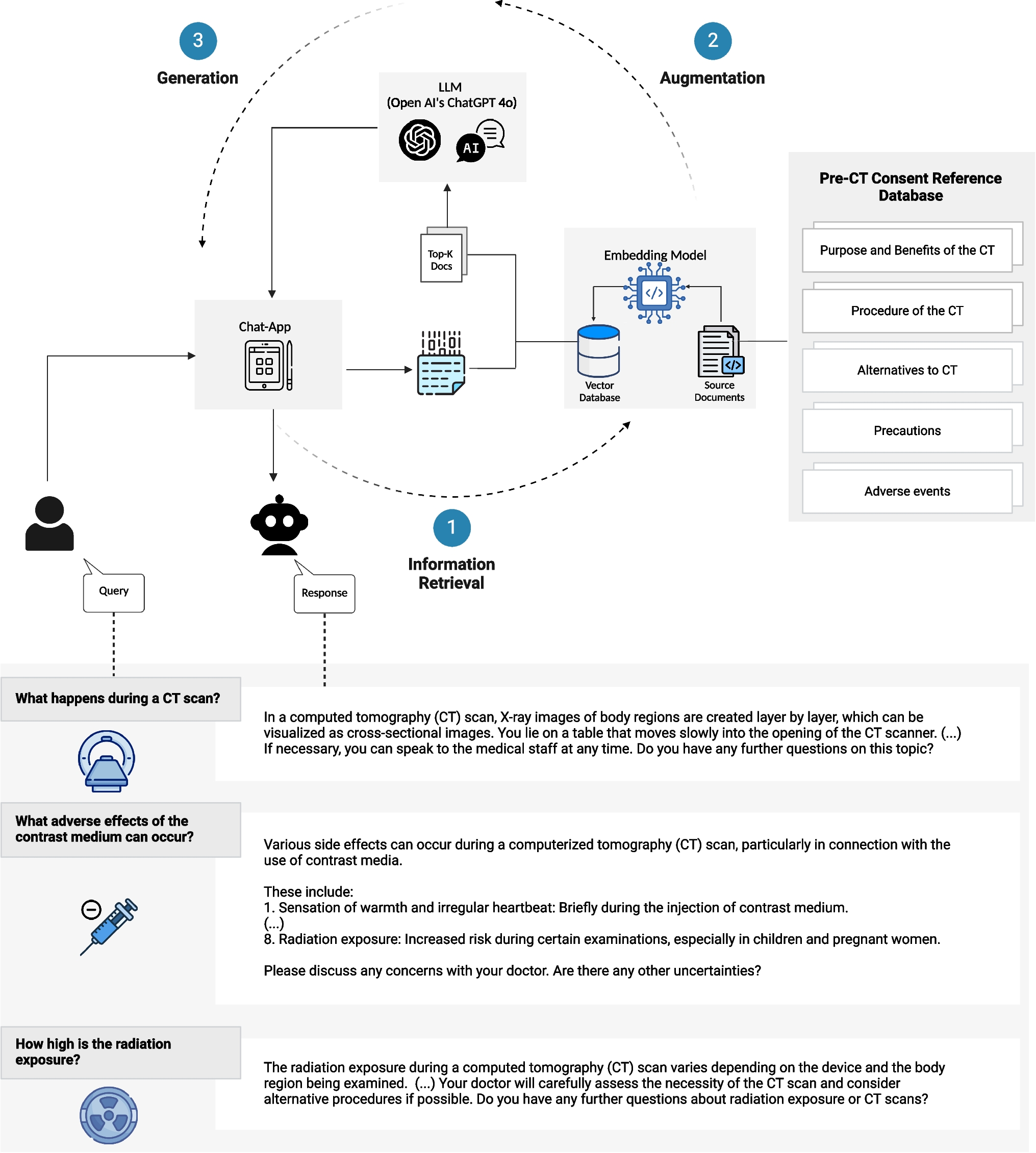
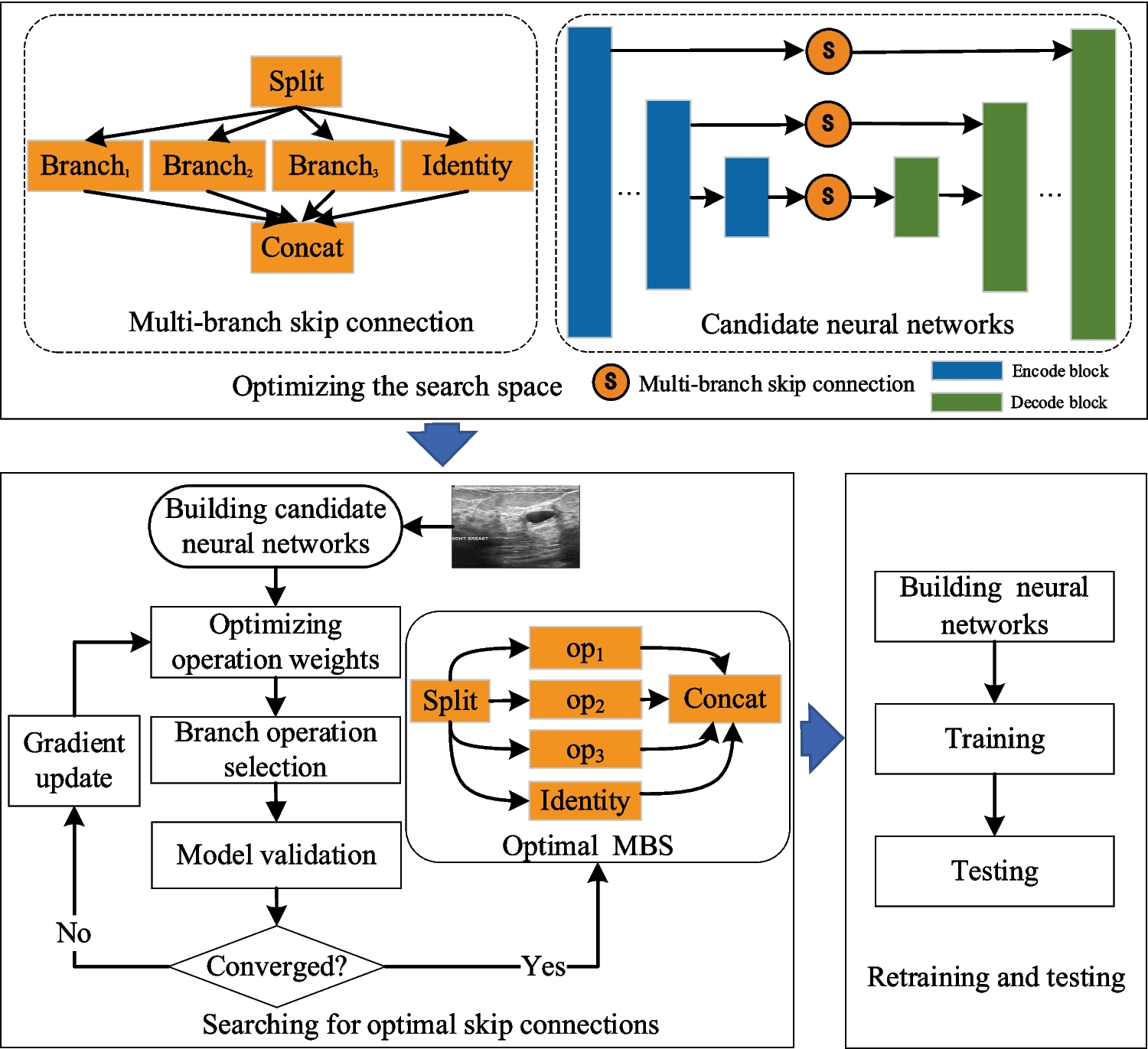
NAS focuses on optimizing the topology of an architecture, usually portrayed through a directed acyclic graph (DAG), where neural network operations label the nodes or edges. NAS methods are typically categorized according to three dimensions: 1. The Search Space A refers to all possible architectures that can be used for a given task; 2. The Search Strategy, which explores the search space by selecting a single architecture α (∈ A); and 3. The Performance Estimation Strategy, that evaluates the model’s predictive performance on unseen data and can be done, for example, using the classic training and validation approach on the data. Figure 1 gives a synthetic description of the NAS workflow followed in this work.
Fig. 1
The Neural Architecture Search workflow
Search SpaceA search space is the set of all architectures that the NAS algorithm is allowed to select. Common NAS search spaces range in size from a few thousand to over a billion architectures. Let us consider a NN as a function that, by applying operations to input variables x, produces output variables y. We can formalize it as a DAG with a set of nodes = Z. Let O be a set of operations, each node z(k), except for the first one that is considered the input node, is a tensor evaluated as follows:
with I(k) inputs form the sets of parent nodes and o(k) (∈ O) operation applied to nodes. The main operations, as per [11], are convolutions, pooling, activation functions, concatenation, addition, etc. Once all the possible operations are defined, the search space can be considered either as a whole or not, giving, respectively: 1. Global search space or 2. cell-based search space. A chain and a hierarchical structure are also possible but not of interest for this work. In a global search space approach, NAS algorithms find all the components required for the entire neural network; consequently, the search space is large because the graph represents the entire network down to the single operation. Instead, in a cell-based search space approach (the one used in this work), the network is subdivided into several cells [12] with different hyperparameters (e.g., the number of filters in the first cell can be different from the number of filters in the second one). This second approach was proposed because many handcrafted architectures consist of repetitions of fixed structures called cells or blocks, which can be represented by a DAG. In this case, the network macro-architecture is manually defined [5], while the NAS approach is reserved for the micro-architecture inside each cell. Usually, two kinds of cells are stacked together repetitively: the normal cell that preserves the dimensions of the input; the reduction cell that reduces the spatial dimensions of the input.
Search StrategyA search strategy is an optimization technique used to find a high-performing architecture in the search space. Once the search space has been defined, it is important to explore it using suitable approaches. There are generally two main categories of search strategies: the black box optimization–based techniques (including multi-fidelity techniques) [13, 14], and the one-shot techniques [15]. However, there are some NAS methods for which both or neither category applies. Once the search space has been defined, it is important to explore it using suitable approaches. The NAS problem can be defined as follows [11]: Let D be the space of all datasets, M the space of all deep learning models, and A the architecture search space, then a general deep learning algorithm Λ is defined as follows:
In this setting, an architecture α \(\in\) A defines the network’s topology, parameters, hyperparameters, and regularization. Let d \(\in\) D be a dataset, which is split into a training and a validation set (dtrain, dvalidation), the algorithm estimates the model mα,θ \(\in\) Mα by minimizing a loss function L with a regularization term R:
$$\wedge \left(\alpha , d\right)=\begin\text\;min\\ _\in _\end\mathcal\left(_, _\right)+R(\theta )$$
NAS has the task of finding α∗ which maximizes an objective function \(f(\alpha )\) of the validation partition dvalidation. For example, considering the classification task, \(f(\alpha )\) is usually the validation accuracy:
$$^= \begin\text\;max\\ \alpha \in A\end f(\alpha )$$
Here, the function f is considered only dependent on \(\alpha\) as all the other settings are considered fixed during the NAS procedure. Several approaches exist in literature to explore the search space, such as random search, reinforcement learning [6, 16], gradient-based optimization differentiable ARchiTecture search (DARTS) [17], and evolutionary algorithms [7]. Evolutionary algorithms use the essential components of a genetic optimizer to find the best neural network [7, 18, 19]. The approach described in [19] and used in the present work requires the definition of a set of primary operations and mutation rules; the overall macro-architecture is also predetermined. Each architecture consists of a sequence of normal cells (in a stack of N cells) and reduction cells. For each stack of normal cells, the number of convolutional filters is equal to F; this number is then doubled after each reduction cell. The goal of this algorithm is to find the best reduction and normal cells (micro-architecture). Then, the search strategy works as follows: after an initial selection of P architectures, each consisting of a repetition of normal and reduction cells, the validation accuracy is evaluated by training each model from scratch. After, the evolution algorithm is applied. With C as the number of generations (number of steps of the evolutionary algorithm), a sample of S models is randomly selected with replacement. The model with the highest accuracy among the S selected samples is then picked as the parent and mutated. The following three mutation rules are chosen according to [19]:
1.Operation mutation: once a cell and a pair of hidden states are selected, one of the two operations is changed (probability: 0.475).
2.Hidden state mutation: once a cell and a pair of hidden states are selected, one of the two hidden states is changed (probability: 0.475).
3.Identity mutation (in which nothing changes) is also possible but with a lower probability (0.05).
At each step, a mutation is randomly selected and then applied to a specific cell (normal or reduction) (Fig. 2). The offspring is then trained, and its validation accuracy is evaluated. The oldest model is then removed from the population to keep the size P constant.
Fig. 2
Visual representation of hidden state and operation mutations inside a cell. Hidden state mutation (top): hidden state 2 connection to operations is changed; Operation mutation (bottom): the convolutional dilatation operation (OP DIL) is changed into a convolutional separable operation (OP SEP), the average pooling (OP AVG) is left unchanged
To speed up the search, the different architectures are trained for a smaller number of epochs. Then, only a subset, consisting of the best models, is selected, eventually augmented (by increasing N and/or F), and trained for a higher number of epochs.
Performance Estimation StrategyA performance estimation strategy is any method used to quickly predict the performance of neural architectures to avoid fully training the architecture. For example, while we can run a discrete search strategy by fully training and evaluating architectures chosen throughout the search, using a performance estimation strategy such as learning curve extrapolation can greatly increase the speed of the search. During the search process, it is necessary to evaluate the performance of the candidate architecture. The easiest approach that can be used is training a neural network from scratch and evaluating its performance on the validation set. Since this approach is computationally heavy and requires a lot of GPU time, different approaches are proposed in the literature to speed up the performance estimation [5]. One of the most used methods that we used in the present work is the lower fidelity estimates, consisting of estimating the performance of the network from the learning curve trained for fewer epochs and from the relevant hyperparameters [20, 21].
Image DataCardiac Amyloidosis DiagnosisCA is a cardiomyopathy associated with the deposition of protein fibrils in the extracellular space of the heart [22]. Several types of amyloidosis can usually be distinguished. The most relevant in cardiac amyloidosis are immunoglobulin light-chain amyloidosis (AL) and transthyretin-related amyloidosis (ATTR). The main problem of this disease is that the early clinical symptoms can be confused with other conditions such as hypertensive heart disease or heart hypertrophy secondary to aortic valve stenosis. Moreover, these two subtypes of amyloidosis require different therapies: AL patients are usually treated with chemotherapy or stem cell transplantation, while ATTR patients are subjected to small RNA-silencing molecules or stabilizers [23, 24]. Therefore, it is very important not only to diagnose the presence of amyloidosis as soon as possible but also to be able to characterize which subtype it is. Nowadays, the diagnosis of ATTR in the absence of a monoclonal disease can be obtained by scintigraphy with bone-seeking agent labelled with 99mTc. Instead, when a monoclonal component in serum and/or urine is present or for the diagnosis of AL, a histologic approach, often by endocardiac biopsy is required [25, 26]. The major drawback of cardiac biopsy is the risk associated with the invasiveness of the technique. Therefore, researchers are trying to use non-invasive methods such as medical imaging to obtain the information needed for early diagnosis [26, 27]. In PET imaging, characterization of the CA can be performed by the evaluation of specific quantitative indexes such as standardized uptake value (SUV) SUVmax, SUVmean and molecular volume obtained with [18F]-Florbetaben by acquiring early and late static 3D images of the thorax after the injection of the radiopharmaceutical [28,29,30]. Alternatively, a dynamic approach can also be taken to evaluate indexes that allow CA diagnosis [31]. Being able to make an accurate differential diagnosis from a single static PET images acquired in an early phase, i.e., after a few minutes from the injection of the tracer, should have the double advantage of reducing the waiting time for the examination to be performed (for the patient) and obtaining a better organization for the nuclear medicine laboratory. Accordingly, in the present work, a set of cardiac amyloidosis images, consisting of 3D static PET acquired 15 min after the injection of the [18F]-Florbetaben, was used to test the goodness of the proposed approach.
Subjects and Cardiac PET Data AcquisitionA total of 47 subjects are included in this retrospective study, including 28 patients with systemic amyloidosis and heart involvement (13 patients with AL and 15 patients with ATTR cardiac amyloidosis, respectively) and 19 control patients with the clinical suspicion of CA, that received an alternative diagnosis, such as left-ventricle hypertrophy secondary to aortic-valve stenosis, primary hypertrophic cardiomyopathy, or hypertensive cardiac hypertrophy. Patients with ischemic heart disease, chronic liver disease, or severe renal failure were not included in the study. Diagnosis of CA was based on clinical examination, biomarkers positivity, electrocardiogram, echocardiography, bone-scintigraphy, cardiac magnetic resonance (CMR), and histological evidence of amyloid deposition according to the most recent cardiological evidence and guidelines [32, 33]. Further details on patients’ characteristics are described in [10]. The study was approved by the institutional ethics committee and the AIFA (Agenzia Italiana del Farmaco) committee; all subjects signed an informed consent form. The study complied with the Declaration of Helsinki. Each subject underwent PET/CT examination. A Discovery RX VCT 64-slice tomography (GE Healthcare, Milwaukee, WI, USA) was used for image acquisition. Firstly, a low-dose-computed tomography (CT) (tube current 30 mA, tube voltage 120 kV, effective dose of 1 mSv), covering the heart, was performed for attenuation correction. Then, 40 min of PET data were acquired, starting at the time of injection of an intravenous bolus of [18F]-Florbetaben (300 Mbq/1 ml) followed by a saline flush of 10 ml (1 ml/s). The raw PET list mode data file was histogrammed between 15 and 20 min of post-injection, to create a single static sinogram. Then, 3D static PET images were reconstructed using the ordered subset expectation maximization (OSEM) iterative algorithm with three iterations and 21 subsets. Each 3D volume consisted of 47 axial slices with a 128 × 128 pixels matrix.
Image Pre-processingFrom the reconstructed axial slices of each volume, only those covering the heart were taken into consideration in the study; accordingly, for each patient, the number of images considered varied from a minimum of eight to a maximum of 19 slices. In addition, image cropping was performed. The final dimensions of the images are of 77 × 104 pixels. A total of 592 2D images (193 from controls, 240 from AL-subtype patients, and 159 from ATTR-subtype) have been considered in the study. In Fig. 3, examples of reconstructed and cropped images from AL, ATTR, and CTRL subjects are shown. To achieve better performance during training and avoid overfitting, data augmentation has been implemented. Following, an affine transformation was used [10], being recognized in literature as the most suitable methodology for the augmentation of data sets in medical imaging [34]. Specifically, each image was randomly translated in both row and column directions of a maximum of 10 pixels and randomly rotated of maximum ± 10°. The affine transformation was applied ten times for each input image. The data augmentation is performed as a one-time preprocessing step and only on the training set. To avoid data leakage when evaluating the results, data splitting was performed at the patient’s level, avoiding the presence of slices from the same subjects both in the training/validation and the test set. After data augmentation, the overall dimensions of the sets are the following:
The training set consists of 384 images augmented to 3840 (10 × data augmentation; 1550 AL, 1010 ATTR, 1280 CTRL).
The validation set consists of 96 images (40 AL; 30 ATTR; 26 CTRL).
The test set consists of 112 images (45 AL; 33 ATTR; 34 CTRL).
Fig. 3
Example of images from the different classes: values are in SUV
Hardware and Software SpecsThe overall algorithm is run on a PC, with Ubuntu Operative System 22.04.3 LTS, equipped with a Core i7 4790k 4-core CPU, 32GB of Ram and an Nvidia Titan Xp GPU with 12 GB of VRAM. The algorithm is implemented in Python 3.9.13 using the Anaconda environment 22.9.0 with the respective libraries. Pytorch 1.13.1 with CUDA 11.7 and CuDNN 8.5 was used for the core DL development.
Implementation of the Algorithm and Methods DetailThe approach used to classify the datasets is based on the method described in “Theory”.
Choice of the Primitive OperationsThe primitive operations that can be used to build a normal or a reduction cell have been selected based on [9] and [19]. To avoid redundancy, convolutions, max pooling, and mean pooling were restricted to 3 × 3; indeed, [9] shows that larger kernel sizes like 5 × 5 and 7 × 7 can be substituted by stacking appropriate 3 × 3 convolutions. In this way, each operation possesses distinct properties that cannot be substituted by others. The chosen operations are defined through a dictionary. Following [12], 1 × 1 convolutions are inserted to ensure equal dimensions of the two hidden input states. Each convolution consists of a sequence of Conv-ReLU-batch normalization. Batch normalization is a popular technique used in neural networks to improve performance and stability. This is achieved by normalizing the output of a layer to have a mean of zero and a standard deviation of one [35]. This allows the network to learn more efficiently and prevents overfitting.
Implementation of the Evolutionary AlgorithmTo determine the best model for the provided datasets, some parameters were set.
The number of filters of the first cell (F) (this number is doubled before each reduction cell) was initially set equal to 4.
The number of operations for each cell. For example, n operations correspond to n-1 hidden states: 2 as inputs, one as output, and the remaining n-4 are generated by applying the selected operations to the previously selected hidden states. The number of operations was set to 6.
The number of classes for the classification task: equal to 3 corresponding to CTRL class (i.e., control subjects), AL and ATTR classes.
The number of input channels is equal to one since the PET images are grayscale.
The number of layers of the architecture is 4, as shown in Fig. 4.
The number of starting architectures P is 100, with 900 evolutionary steps C (in each step 1 sample was mutated (S)).
Fig. 4
Structure of the architecture we are looking for
An example for the first convolutional operation in the normal cell could be:
x = Conv2D(input_tensor, F = 4, kernel_size = (3, 3), strides = (1, 1), padding = ‘same’)
x = ReLU(x)
x = BatchNormalization(x)
The NAS algorithm was run five times (Fig. 5). For each run, a first training step using 25 epochs was performed on a population of 100 evolving individuals, maximizing the overall classification accuracy. In the second step, the best five architectures underwent a further 175 epochs training. Hence, 5 × (P + C) = 5000 individuals were generated in the first step and 25 (5 × 5) were more deeply analyzed in the second step. In the final step, the best individual (i.e., the one with the higher overall accuracy) was identified. Once the best model is selected, a stochastic k-fold validation of the best model is performed using five random splits of the training/validation dataset. All the training was done using the Adam optimizer, with a learning rate of 1e-3, cross-entropy loss, and a batch size of 32. Detailed values of the hyperparameters used for the architecture search algorithm are shown in Table 1.
Fig. 5
Overall performance estimation strategy and model selection
Table 1 Hyperparameters for the architecture search algorithmPseudocode for the implemented algorithm is provided below. From top to bottom: initialization, initial model population creation, evolution process, final training of the best architectures and output.
 CAclassNET as Handcrafted Neural Network for Comparison
CAclassNET as Handcrafted Neural Network for ComparisonTo evaluate the goodness of the net obtained by the NAS methodology, a comparison was made with the CNN, named CAclassNET, previously proposed by the authors in [10]. In the present work, the CAclassNET was newly implemented by using Python and Pytorch facilities (in [10], it was implemented in Matlab), for a better comparison between the two networks, and trained with the optimized hyperparameters described in [10]. The training was then repeated five times to statistically evaluate the performance of the classifier on the provided dataset.
Comments (0)