
Remember me

We evaluate the proposed method CS-SCL on the following public image datasets CIFAR10, CIFAR100, CUB200-2011, Stanford Dogs, and PASCAL VOC 2005. We use the standard split of datasets into training and testing as shown in Table 1. The size of the images is also given in Table 1.
Various backbone encoders are used. We use the pretrained ResNet50 [12] and ConvNeXt-T [18] as CNN encoders, and two pretrained transformers from Model Zoo library, TinyViT (5 M) and TinyViT (21 M).
The following methods were used: (1) baseline method using the backbone encoder with a classification head in a default setting; (2) SimCLR [6], an unsupervised contrastive learning method; (3) BYOL [10], supervised deep metric learning; (4) SCL [15], a supervised contrastive learning method; (5) CS-SCL, our proposed supervised contrastive learning method; and (6) CS-SCL with overlap, our proposed supervised contrastive learning method.
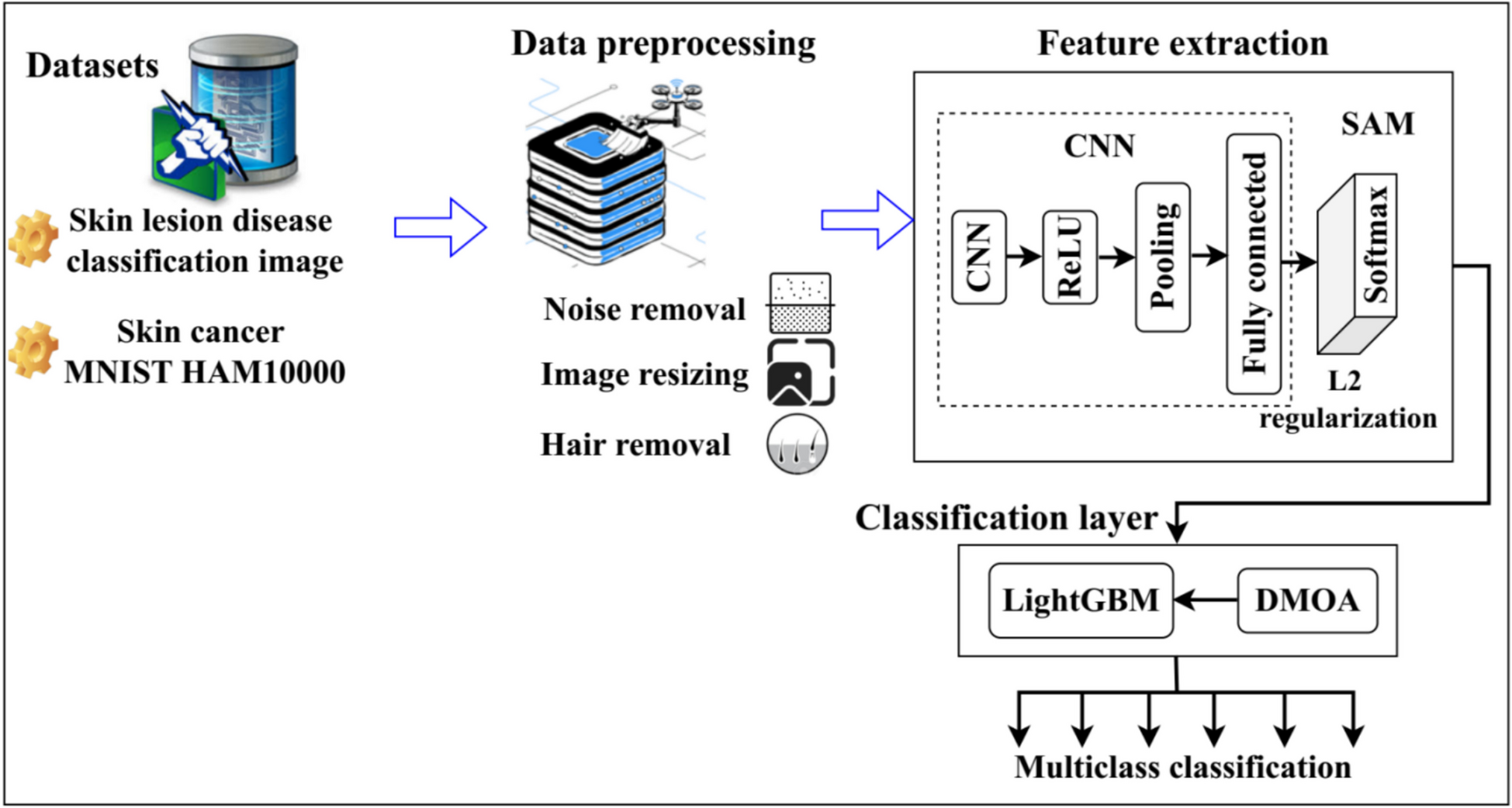
Table 2 Value of the main hyperparameters used by the proposed CS-SCL methodTable 3 Method comparison using five image datasets and three different encoders. Bold values indicate the best-performing results across different methodsImplementation DetailsThe dimensions of the common space were chosen to be higher than those of the style space. For all encoders and methods, the projection head consists of two fully connected layers that map the deep features of the backbone into a 256-D feature vector, i.e., \( D_p=256 \). The dimension of the first layer is equal to that of the deep features. For our proposed method CS-SCL, we set \( D_c \) and \( D_s \) to 192 and 64, respectively. For CS-SCL with overlap, we set the overlap size to 28, starting with the 165th entry. We emphasize that these dimensions were kept fixed for evaluating the performance of the proposed scheme across all used datasets. Our obtained results indicate that these selected dimensions led to good performance on all datasets used.
Data augmentation was used in the method training. This included scaling, cropping, and horizontal flipping. This augmentation scheme is used to get two copies of each image in the current batch.
For all datasets, the learning rate followed a cosine law as a function of the epoch number. It is used to decrease the learning rate during training. The lower bracketing value was used with a decay. We use two parameters to dynamically adjust the learning rate, the initial learning rate and the learning rate decay rate, which are 0.01 for all baselines and 0.2 for the learning rate decay rate. The temperate scale \( \tau \) was fixed to 0.07 as in [15].
Table 2 shows the main hyperparameters used by the proposed approach.
We emphasize that the batch size was kept the same for all contrastive methods to ensure a fair and consistent comparison. By standardizing the batch size across different methods, we aimed to isolate the impact of the contrastive learning strategies themselves, rather than introducing variability due to differing batch sizes. This approach allows us to more accurately assess the performance and effectiveness of each method under comparable conditions.
While the batch size remained constant, other hyperparameters, such as learning rate, were individually optimized for each contrastive method. This ensures that each method operates under its optimal settings, thereby providing a comprehensive evaluation of their capabilities.
Experimental ResultsTable 3 summarizes the accuracy rate obtained on the test parts of the five image datasets using the trained encoders. We have adopted the linear evaluation scheme for all two-stage methods. In this table, the baseline solution is compared with different contrastive methods. As can be seen, all contrastive methods outperform the baseline method except for the SimCLR method. The two proposed CS-SCL variants outperformed the other contrastive methods in almost all cases. Moreover, the CS-SCL variant with overlap provided the best performance for all datasets. The second variant performed better than the first variant. We can also note that the SCL, CS-CSL, and CS-CSL methods with overlap outperformed the BYOL method. The main reason for this is the fact that BYOL considers only positive pairs during training, while the other methods include both positive and negative examples.
Ablation Study and Sensitivity to ParametersEffect of \( \alpha \) and \( \beta \)The proposed loss function in (3) has two parameters \( \alpha \) and \( \beta \). This loss function contains two terms associated with the style field that contribute to contrastive learning. The first term works in the opposite way as the contrastive learning of the common field. The second term is a Euclidean distance. Both terms try to pull away the style features for the positive examples.
We study the effect of each term (\( \alpha = 0 \) or \( \beta = 0 \)) separately and the impact of their joint use (\( \alpha \ne 0 \) or \( \beta \ne 0 \)). Table 4 provides an overview of the ablation study performed with the different datasets. We can observe that with the addition of the second term only (\( \alpha =0 \)) or the first term (\( \beta =0 \)), the performance has been increased for all datasets. As can be seen, the inclusion of both terms in the loss function, in general, resulted in the best performance.
Table 4 Ablation study for the loss function. Bold values highlight the optimal outcomes in the effect of \( \alpha \) and \( \beta \) on performanceTable 5 Classification rate (%) of the proposed scheme on the test part of the five datasets as a function of the temperature parameter \( \tau \). Bold values correspond to the optimal temperature parameter settings for accuracy improvementFig. 4
Accuracy as a function of the two parameters \( \alpha \) and \( \beta \)
Effect of the Temperature Parameter \( \tau \)Table 5 depicts the variation of the classification rate as a function of the temperature parameter \( \tau \) for the five datasets. As can be seen, the optimal range for \( \tau \) is [0.02, 0.1].
Table 6 Method comparison with varying batch sizes and different training schemes for CS-SCL (ours) and CS-SCL w. ov. (ours)Figure 4 shows the accuracy rate of the proposed method CS-SCL as a function of different combinations of \( \alpha \) and \( \beta \). As can be seen, the combination (\( \alpha = 0.005 \) and \( \beta = 0.005 \)) can be considered a good choice for all datasets and encoders.
Effect of the Batch Size and Training SchemeTable 6 summarizes the comparison of methods with varying batch sizes and different training schemes for our two proposed schemes CS-SCL (ours) and CS-SCL w. ov. (ours) across five datasets. In this table, accuracy is obtained mainly through two scenarios: employing only the classification layer with a frozen encoder (linear evaluation) and fine-tuning the encoder with the classification layer. As observed, except for the CUB200 dataset, the classification accuracy with “Fine-tuned” is generally lower than that with “Frozen.” Additionally, except for the Cifar10 and Cifar100 datasets, all other datasets show an improvement in classification accuracy for “Frozen” as the batch size increases. CS-SCL w. ov. consistently outperforms CS-SCL across all datasets.
Table 7 Network structures and their parameter countsTable 8 Computational costs associated with the following methods: (i) deep backbone, (ii) baseline SCL (traditional contrastive learning), (iii) CS-SCL (proposed), and (iv) CS-SCL with overlap (proposed). Four different deep backbones were used for each method. The third column shows the model size (number of parameters in millions), the fourth column gives the number of Floating Point Operations (FLOPs) in billions required to process an entire batch of 96 images, the fifth column lists the training time per epoch in seconds (training time), the fifth column reports the inference speed in frames per second (FPS), and the sixth column shows the accuracy achieved. These results were obtained using the CUB200-2011 dataset with the dimension of the projection head set to 256. The measurements were performed with an NVIDIA GeForce RTX 4090. Upwards arrow symbol (\( \uparrow \)) indicates that a larger value is better, while downwards arrow symbol (\( \downarrow \)) indicates that a smaller value is betterComputational ComplexityTable 7 illustrates the model size of the network used in the first training stage, i.e., the network that is obtained by cascading the backbone model with the projection head. The projection head has two fully connected layers that project the deep features of the backbone into a space of 256. This configuration is critical for the initial phase of training, where the combined architecture’s capacity and complexity are key factors in its performance.
Table 7 illustrates the model size of the network used in the first training stage, i.e., the network obtained by cascading the backbone model with the projection head. The projection head has two fully connected layers that project the deep features of the backbone into a space of 256. This configuration is crucial for the initial phase of training, where the capacity and complexity of the combined architecture are critical to its performance.
Table 8 illustrates the computational costs associated with the following methods: (i) baseline deep backbone, (ii) baseline SCL (traditional contrastive learning), (iii) CS-SCL (proposed), and (iv) CS-SCL with overlap (proposed). Four different deep backbones were used for each method. The third column shows the model size (number of parameters in millions), the fourth column gives the number of Floating Point Operations (FLOPs) in billions required to process an entire batch of 96 images, the fifth column lists the training time per epoch in seconds (training time), the sixth column reports the inference speed in frames per second (FPS), and the seventh column shows the accuracy achieved. The computational costs of the three SCL methods are higher than those of the baseline backbone due to the additional projection head. However, for the two proposed SCL methods, the computational costs are almost identical to those of classical SCL.
These results were obtained with the CUB200-2011 dataset, with the dimension of the projection head set to 256. As can be seen, the cost of the training computations of our proposed methods is almost the same as that of the baseline SCL. This shows that our methods are computationally efficient while providing improved performance.
Comments (0)