
Remember me








This dataset focused on the time-location data for 357 members of the Washington State Twin Registry (WSTR). The WSTR participants shared their GLH data, which consists of longitude and latitude coordinates, timestamps, and the accuracy of these measurements derived from each participant’s GLH [15]. This feature records the locations that users visit, including the time of the visit and the location’s accuracy. In total, we had access to over 287 million records from this passive data collection method giving us an objective view of the participant movements over time. GLH data has been recognized as a viable source for acquiring individual location information, as evidenced in recent research [15] and a powerful new approach to acquiring environmental exposures and their impacts on public health.
Outlets dataOur research utilized INFOUSA/DATA AXLE, a commercial dataset containing a census of food outlets in Washington State, providing details like location coordinates and addresses [16]. This dataset was comprehensive, encompassing a wide range of business types. Specifically, we concentrated on food outlets, filtering them from the broader dataset based on their North American Industry Classification (NAICS) codes. The NAICS codes are a standard for classifying business activities, which helped us organize the food outlets for analysis. This focus on food outlets was guided by the methodology detailed in recent research [2], which utilizes NAICS codes to accurately identify and analyze the food environment. The NAICS code are listed in Appendix A.
Defining food outlet visitsOur study aimed to quantify consumer visits to food outlets using GLH data by employing a clear and interpretable methodology. GLH data includes classifications of place visits, which encompass food retailers. Although the method for generating these classifications is proprietary and lacks detailed information on accuracy and reliability, the data was still usable for our analysis. While the place visit classification does include visits to a variety of outlets, these are not annotated with NAICS codes or descriptions. Consequently, matching the place visit names to their respective NAICS codes or descriptions would require a manual and potentially error-prone process. Furthermore, approximately 20% of the GLH place visits are represented merely by addresses, without specific names of the places visited, complicating the identification and categorization process even further. Despite these challenges, we utilized the GLH place visit data for comparison with our results.
We constructed a buffer zone around each outlet, delineating a specific area where visits would be counted and analyzed. The initiation of a visit was marked by a participant’s entry into this zone, it’s conclusion by their departure, and a non-return into the buffer zone within a specified time limit. This method relied on setting specific parameters to accurately identify consumer visits. These included the precision of the location data, the dimensions of the buffer zone around each outlet, the duration of time spent to qualify as a visit, and the standardization of these visits across the study. Each parameter was critical for ensuring that the data reflected consumer behavior at these food outlets.
Food outlet visit parametersLocation precisionAccurately identifying visits hinges on the precision of the participant’s location data. Precision is quantified by the accuracy radius around the recorded location point, measured in meters. A smaller radius indicates higher precision. We evaluated the precision of all location points from the GLH data, selecting only those with a sufficiently small accuracy radius for our analysis. This process helped reduce the possibility of falsely identifying visits, ensuring that our analysis was based on reliable and precise location information. In line with these criteria, we used a location precision threshold of 50 m. This threshold was chosen as it strikes a balance between capturing a high number of genuine visits while minimizing the inclusion of erroneous data.
Outlet buffer zone dimensionsDetermining the appropriate dimensions for outlet buffer zones was crucial in our methodology to accurately identify consumer visits. A larger buffer zone might include a wider area, raising the chance of capturing incidental visits not aimed at the outlet itself. On the other hand, too small a buffer zone could miss genuine visits due to slight inaccuracies in the location data.
To address this, we tailored buffer zone sizes to the types of food outlet, acknowledging that different outlets vary in physical size and attract different patterns of consumer behavior. We established buffer zone dimensions based on the median physical dimensions of outlets in each NAICS category, considering how the size of an outlet might impact the detection of actual visits. This nuanced approach allowed us to balance the need for accuracy with the practicalities of capturing consumer behavior across a variety of food outlet types. Table 1 shows the differentiated outlet buffer sizes for the different outlet categories.
Table 1 Visit parameters and their default valuesVisit durationTo accurately detect and classify visits within the buffer zones around food outlets, we defined three essential parameters:
1.Minimum Stay Duration This criterion determines the shortest time an individual must spend in the buffer zone to count as a visit. We set this parameter to 3 min [17], helping to distinguish genuine visitors from those merely passing by the location.
2.Maximum Stay Duration This limit is set to exclude stays that are likely not indicative of typical patronage, such as employees working at the outlet or individuals using the space for extended periods unrelated to consumption. We set this parameter to 3 h, with stays exceeding this duration not considered valid visits in our analysis. Typically, families spend an average of 53 min at fast food restaurants [18], we set this higher so we could catch longer stays at the outlets.
3.Revisit Interval This parameter specifies how soon an individual can return to the buffer zone for it to be considered a continuation of the original visit or a new visit. This parameter was also set to 3 h for accurately consolidating visits, especially in scenarios where a person exists and re-enters the buffer zone within a short period.
These parameters collectively ensure that our method distinguishes between different types of visits accurately, thereby enhancing the precision of our analysis of consumer behavior at food outlets. By setting specific time frames for the Minimum Stay Duration, Maximum Stay Duration, and Revisit Interval, we further refine our approach to accurately identify and analyze consumer interactions with food outlets. Table 1 presents the five key parameters utilized for identifying visits, along with their respective default values.
Standardization of visitsTo ensure our analysis of outlet visits was both equitable and precise across participants, standardizing the visit data was crucial. This step addressed the variability in the amount of location data available for each individual. Our standardization focused on creating a uniform measure for comparison, specifically the number of active days per participant. Initially, we considered defining active days as the total number of days with recorded location data for a participant. However, this approach has drawbacks due to uneven data coverage across participants, which could skew the analysis of visit frequencies and durations.
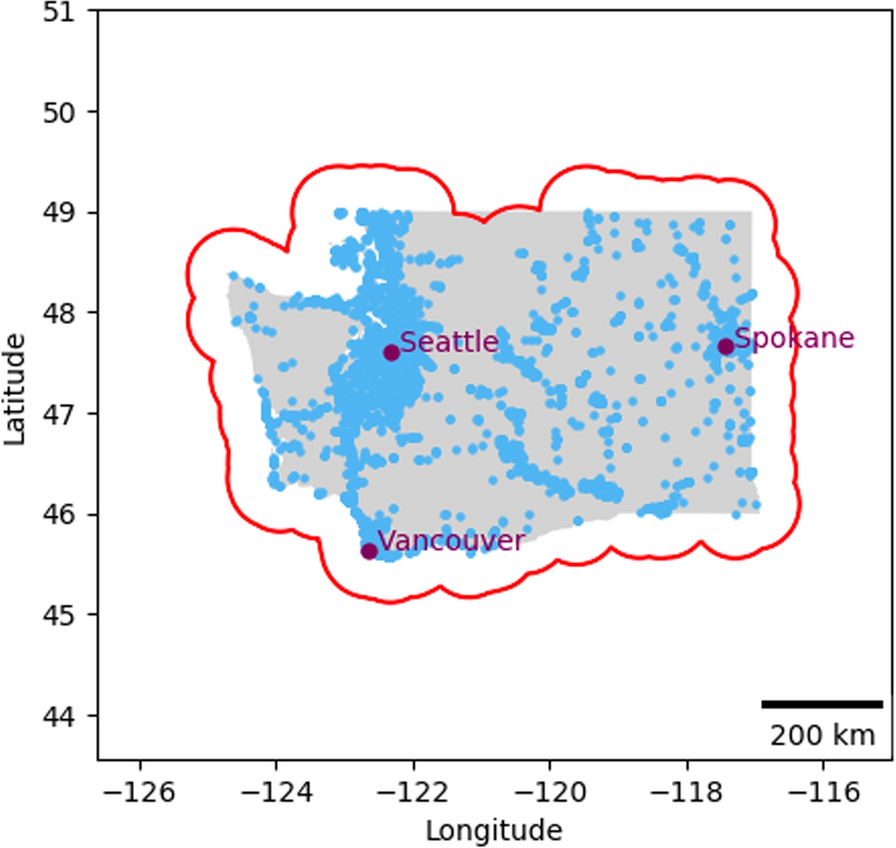
To overcome these challenges, we adopted a more sophisticated strategy. We defined a strategic active area with a 50 km radius around all listed outlets. Fig. 1 shows the delineated active area (red polygon) representing a 50 km buffer zone surrounding all outlets (marked in blue dots). A participant’s active days were then calculated based on their presence within this area. Importantly, we introduced a time-based criterion to enhance accuracy: periods spent outside the active area for more than three hours were not counted as active. This method yielded a more reliable measure of participant activity relevant to our study, ensuring a consistent basis for analyzing visit patterns.
Fig. 1
Active area polygon (red) with food outlets (blue) in Washington State (gray). The active area polygon was created using a 50km buffer zone surrounding all outlets
Data processing workflowInitial Filtration of Location Data The first step in our data processing involves refining the raw location data based on the precision of each location point.
Construction of Preliminary Visit List Once the data is filtered for precision, we proceed by isolating location points that fall within the designated buffer zones around each food outlet.
Consolidation of Visit List To refine our understanding of visit patterns, we employ the revisit interval parameter. This allows us to merge contiguous visits into a single event, reducing redundancy and providing a clearer picture of consumer behavior.
Finalization of Visit List The consolidated list of visits then undergoes a final filtration process. This stage applies the Minimum Stay Duration and Maximum Stay Duration parameters for a visit to be considered valid.
Standardization of Visits In the final step, visits are standardized based on the frequency and duration of visits on a daily, weekly, monthly, and yearly basis, considering the time participants spent within the active areas.
Fig. 2 shows the data processing workflow including the parameters used at each stage. Additionally, Fig. 3 illustrates a sample trip trajectory for one individual, showing the applied methodology’s capability to map out visit patterns.
Fig. 2 Fig. 3
Fig. 3
A sample detected visit to a food outlet by one individual participant
Sensitivity analysis of visit identification parametersTo assess the impact of individual parameters on the identification of visits to food outlets, we conducted a sensitivity analysis focusing on the five key parameters. This analysis involved systematically altering one parameter at a time-either increasing or decreasing its value-while holding the other four constant. The purpose was to understand how changes in each parameter could affect the total number of visits detected. This method allowed us to determine the relative sensitivity of our visit identification process to each parameter, providing insights into which factors most significantly influence the count of recorded visits. Table 1 shows the parameters alongside their default and alternate values for the sensitivity analysis.
GIS Comparison and proximity analysisWe derived exposure metrics based on GIS techniques to assess the association between food outlets around participants’ homes and food outlet visits derived from GLH data. Density metrics for supermarkets and limited-service restaurants were computed for distances within 1 km and 2.5 km circular buffers around each participant’s reported residential address. We focused on these two outlet types because supermarkets are primary sources of healthy foods, such as fresh produce and whole grains, which are essential for a balanced diet and have been associated with more favorable health outcomes [6, 8, 19]. Conversely, limited-service restaurants are often associated with the availability of energy-dense, nutrient-poor foods, which have been linked to unhealthy dietary patterns and increased risk of chronic diseases [20, 21]. Additionally, supermarkets are frequently targeted in public health policies aimed at improving food access in underserved communities, making them a key focus for research on the food environment [6, 22, 23]. The 1 km buffer was selected to represent a reasonable walking distance, typically covering 10–15-min walk, as supported by prior studies examining walkability and access to local amenities [5, 24]. The 2.5 km buffer was chosen to reflect a short driving distance, corresponding to a 5 to 7-min drive, aligning with research on vehicular access to food outlets [6, 25]. These considerations guided our decision to focus on these specific metrics.
We counted the number of the outlet types around participants’ homes. Correlation analysis was conducted to determine the relationship between the number of these outlets and visit frequencies. Spearman coefficients were calculated for supermarkets and limited-service restaurants within 1 km and 2.5 km distances. Additionally, we categorized the outlet counts and visit frequencies into four groups (Low, Medium, High, Very High) and computed the Cohen’s Kappa statistic to assess the agreement between outlet proximity and visitation rates.
GLH Place visits comparisonWe analyzed the place visits provided by the GLH dataset, focusing on places within Washington State with an interest in food outlets. Using fuzzy text matching techniques, we aligned GLH data with corresponding NAICS codes and descriptions from our food outlets dataset. Criteria for “location confidence” and “visit confidence” were set at a threshold of 70 or higher, along with a fuzzy text match of 85 or above. The classification results were then compared to those detected by our method to evaluate the robustness and comprehensivenes.
Comments (0)