
Remember me
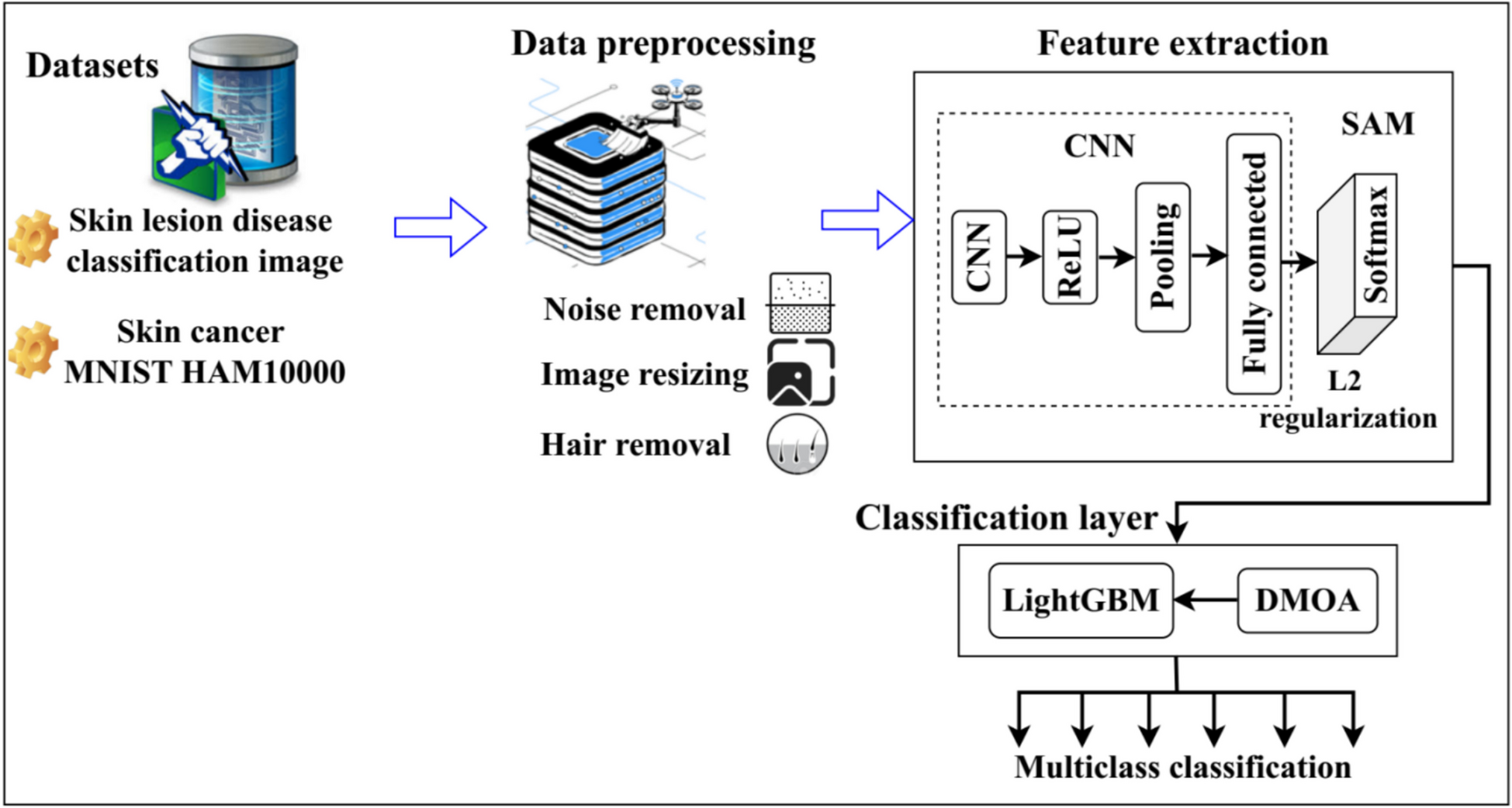

The extensive adoption of AI systems in the healthcare field depends not only on the achievement of adequate levels of accuracy, but also on how much they are perceived to be trustable. In particular, the ability to explain how the outcomes have been produced by the models is more and more required and represents the main driver of XAI. This section discusses the aspect of transparency of AI systems, focusing on how it is defined for the two Fed-XAI approaches analyzed in this paper. First, we analyze the explainability of the MLP-NN model, in which SHAP is used as post-hoc method. Then, we discuss the interpretability by-design of the TSK-FRBS. We consider models built in a federated fashion according to the IID data partitioning scheme: the discussion of the outcomes is limited to such case, but the pipeline for explainability analysis can be easily replicated for any data distribution scenario. Furthermore, we recall that all the input variables and the output variable are normalized in the unit interval \([0,1]\): the considerations in this section refer to the predicted values before inverse transformation.
Post-hoc Explainability of MLP-NNIn this section, we discuss the explainability of the MLP-NN after the application of the agnostic post-hoc method SHAP. We recall that, given an input instance, the Shapley value associated with each feature represents the contribution given by such feature to the predicted value. In this sense, for each prediction, SHAP explains why the model produces a particular output.
We adopt the Federated SHAP approach proposed in [21] and introduced in Section 3.2.2. KernelSHAP is employed in each hospital to estimate the Shapley values considering the full local training set as background dataset.
It is worth underlining a first crucial aspect concerning the explainability of MLP-NN: unlike interpretable-by-design Fed-XAI approaches, the post-hoc method affects the overall efficiency of the systems, both from a computation and a communication point of view. As for the former aspect, the estimation of the Shapley values with KernelShap is time consuming and the runtime increases with the number of features and the size of the adopted background dataset [70]. As for the latter aspect, Federated SHAP introduces a communication overhead, as Shapley values need to be transmitted by the participants for central aggregation. Conversely, the interpretable-by-design TSK-FRBS has no computation and communication overhead for generating the explanations.
MLP-NN: Global InsightsGlobally, an MLP-NN is generally considered “opaque,” due to the presence of several layers of non-linear information processing. In our case, the structure consists of two hidden layers with 128 neurons, resulting in 17,281 trainable parameters. The high number of parameters and the relations among these parameters make very hard to provide a global explanation of the model. Thus, indirect methods based, for instance, on feature importance are typically used to provide global explainability information [3].
As Shapley values represent additive feature importance scores for each particular prediction, the overall feature importance can be assessed by computing the average of the absolute Shapely values across the data [70]. Of course, the larger the average absolute value of the contribution given by a feature, the greater the importance of that feature. The assessment of the feature importance of a model is typically independent of the test data. In the case of the MLP-NN, it can be estimated as follows. First, each hospital \(hIi\) on its training data:
$$\begin I_^ = \dfrac\cdot \sum _^ |\phi _j^| \quad \forall \; j \in \. \end$$
(9)
where \(\phi _j^ jih,\,N_hh\). Then, each client can transmit locally computed features importance to the server, and the overall features importance for the federated model can be computed by the server as follows:
$$\begin I_^ = \sum _^ \dfrac\cdot I_^ \quad \forall \; j \in \. \end$$
(10)
where \(HN = \sum _^N_h\).
Figure 8 shows the global feature importance scores for the MLP-NN, as per (10): in the IID setting, the most relevant feature is age, while test_time seems to be less relevant than vocal features, namely DFA and HNR, which in turn are of similar relevance.
Fig. 8
Feature importance scores for the MLP-NN
MLP-NN: Local InsightsFigure 9 reports the SHAP values for two instances of the test set; they correspond to two cases where both models (MLP-NN and TSK-FRBS) obtain high and low errors, respectively. The absolute error (AE) made by the MLP-NN is around 0.55 for instance #2496 and around 0 for instance #2323.
Fig. 9
MLP-NN local explainability: Shapley values for two instances in the test set. The absolute error for each instance is reported along with the baseline value
The Shapley values reveal, a-posteriori, the relevance of the corresponding features in the prediction performed by the model: as expected, they are different when considering different instances. In the former case (Fig. 9a), age has little negative influence, while the other features have a large and positive impact on the output value. In the latter case (Fig. 9b), the most influential feature is test_time, which has a negative impact on the output. Notably, the SHAP values for individual features are evaluated, for both instances, with respect to the same baseline value \(\phi _0 = 0.46\).
Interpretability By-design of TSK-FRBSTSK-FRBSs are often considered as “light gray box” models [81]: their operation is highly interpretable, since they consist of a collection of linguistic, fuzzy, if-then rules. However, in the first-order TSK-FRBSs used in this paper, the adoption of a linear model in the consequent part, which certainly improves the accuracy with respect to the zero-order TSK-FRBS, makes the interpretation of a single rule less intuitive than the zero-order counterpart.
A substantial difference with respect to the MLP-NN model analyzed in Section 6.1 is that interpretability information is given without additional overhead in terms of computation and communication (as it is the case for the calculation of Shapley values on the MLP-NN model).
The following analysis aims to characterize both global and local interpretability of TSK-FRBS learnt in a federated fashion.
TSK-FRBS: Global InsightsThe global interpretability of TSK-FRBSs can be quantitatively assessed by measuring the complexity of the system in terms of the number of rules and/or parameters. Less complex models, i.e., those with fewer rules, can be generally considered more interpretable [66]. Figure 7 reports the number of rules for each learning setting and each data partitioning scenario. As underlined in Section 5 for the IID case, the number of rules in the FL setting is rather limited (i.e., 397) and just double that in the LL case (despite the presence of 10 participants).
The model is therefore comprehensively described by the rule base, which can be represented in the intelligible form reported in the following.

The number of parameters of a rule in a TSK-FRBS can be estimated as follows, considering the presence of four input variables: it is given by the sum of four parameters for the antecedent part (one for each input variable, to identify a fuzzy set of the a-priori partitioning) and five parameters for the linear model of the consequent part. Ultimately, the considered TSK-FRBS has 3573 parameters overall.
In the case of TSK-FRBS, a measure of feature importance can be obtained by averaging the absolute values of the coefficients of the linear models in the rule base. Formally, the importance \(Ij\) is evaluated as follows:
$$\begin I_j^ = \dfrac\cdot \sum _^ |\gamma _| \quad \forall \; j \in \. \end$$
(11)
where \(\gamma _ jr\).
Fig. 10
Feature importance scores for the TSK-FRBS
Figure 10 suggests that feature importance computed for the TSK-FRBS model is consistent with the one computed for the MLP-NN by the SHAP method in the IID setting. Age and test_time are identified as the most and the least relevant features, respectively. Furthermore, the importance of HNR and DFA is similar, consistently with what is observed for the MLP-NN.
A direct comparison of the importance values between Fig. 8 (MLP-NN) and 10 (TSK-FRBS) is not meaningful. Indeed, in the case of MLP-NN, Fig. 8 shows the average absolute contribution for each feature with respect to the baseline value. In case of TSK-FRBS, Fig. 10 represents the average absolute value of the coefficients of the linear models used in the case of TSK-FRBS.
It is worth underlining that model-agnostic nature of SHAP can be exploited to compute post-hoc explanations also on the TSK-FRBS model. Thus, we can directly compare the feature importance obtained by averaging the absolute values of the coefficients of the linear models in the rule base and reported in Fig. 10, with that obtained by averaging the absolute Shapely values across the data for TSK-FRBS (9) and (10). The latter approach results in the scores reported in Fig. 11.
Fig. 11
Feature importance scores for the TSK-FRBS evaluated in terms of Shapley values
It is interesting to note that age and test_time are still identified as the most and least important features, indicating a summary agreement among the results obtained with different important attribution methods in the IID scenario. There is a discrepancy, on the other hand, between the relative values of DFA and HNR, possibly because the two approaches estimate importance values with different criteria. Furthermore, it is worth noting that feature importance scores computed for TSK-FRBS using SHAP are consistent with those computed for MLP-NN and shown in Fig. 8, also in terms of range of values.
The identification of age as the most important feature regardless of the model and the attribution method adopted is not surprising. First, in the IID scenario, each hospital can have data for all age ranges and therefore the feature entails a high variability. Second, such evidence is reflected in the specialized literature, which indicates that age is the best predictor of the progression of Parkinson’s disease and the most important risk factor for the development of the disease [82].
TSK-FRBS: Local InsightsThe interpretability of the TSK-FRBS derives from its structure and the type of inference strategy we use. Indeed, for any given input instance, the predicted output depends on a single rule: the antecedent part isolates a region (a hypercube) of the input space, where its consequent part defines a local linear model. The coefficients of this model indicate how the input features contribute to form the TSK-FRBS output in that region: a positive (negative) coefficient for a given feature indicates that the output increases (decreases) with that feature. Notably, all instances belonging to that region will refer to the same linear model.
Given an instance \(\textbf_ r,\,\textbf_ \), the actual contribution of each feature to the prediction \(\hat} \gamma _\cdot x_ \). In other words, contributions are obtained as the element-wise product between the coefficients of the linear model and the feature values of an instance. Figure 12 reports both the feature contributions and the coefficients of the linear model of the TSK-FRBS for the same two instances of the test set analyzed in the case of the MLP-NN (instances #2496 and #2323).
Fig. 12
TSK-FRBS local explainability: coefficients of the linear model and actual feature contributions for two instances in the test set. The absolute error for each instance is reported above the relevant plot along with the ID of the rule considered for the prediction and the term \(\gamma _0\) of the linear model
The two instances activate different rules: as a consequence, the contributions are significantly different. Furthermore, in general, the contributions are reduced compared to the coefficients, since each feature is normalized in the unit interval.
Fig. 13
Shapley values calculated for the MLP-NN model on the instances in the test set that activate rule \(R_ \) of the TSK-FRBS. The absolute error (AE) for each instance and for each model is reported above the relevant plot
Local Explanations: Comparison Between TSK-FRBS and MLP-NNA relevant outcome can be drawn by comparing the barplots of Figs. 9 and 12: although the absolute errors are similar (we have verified that the predicted values are similar as well), the two models “reason” differently and assign different—sometimes diametrically opposed—contributions to the features, also because the term \(\gamma _0\) is different from the baseline value of SHAP.
To better examine this aspect, we focus on a set of instances and analyze the explanations provided by the two models. Specifically, we consider the instance resulting in a high AE for both models (ID #2496) and all the instances of the test set that activate the same rule (namely, \(R_ \)) of the TSK-FRBS. In this way, we isolate four instances (ID #827, ID #2266, ID #2496, ID #5146) which are inevitably close to each other in the input space.
The local interpretability of the TSK-FRBS is straightforward: predictions are obtained by applying the following rule:

In the case of MLP-NN, the prediction is explained through the Shapley values: Fig. 13 shows the contributions for the MLP-NN considering the four instances of the test set that activate rule \(R_ \) of the TSK-FRBS system.
It is evident that the Shapley values for the MLP-NN vary greatly even though the instances are fairly close in the input space: as an example, age has a negative contribution for ID #827 and a positive one for ID #5146. For this reason, it is equally evident that a correspondence cannot be found between the explanations offered by SHAP for the MLP-NN and the interpretation of the linear model of the TSK-FRBS. For example, SHAP always assigns a positive contribution to DFA, while the relevant coefficient is negative for TSK-FRBS.
As noted above, the divergence in explanations between TSK-FRBS and MLP-NN in the IID scenario does not correspond to a divergence in output values. We have verified that the predicted outputs are similar (and indeed the reported AE values are similar): different models, which achieve similar results, lead to different explanations from a local point of view. This is not to be considered odd: our analysis entails different feature importance methods (inherent and post-hoc) and different models (TSK-FRBS and MLP-NN, respectively). Actually, it has been empirically shown that the feature importance score may suffer from numerical instability (when model, instance and attribution method are the same), solution diversity (if different models are considered, but on the same instance with the same attribution methods), or disagreement problem (if different attribution methods are considered, but on the same instance and the same model) [83]. These scenarios are due to the so-called Rashomon effect [84], whereby for a given dataset there may exist many models with equally good performance but with different solution strategies.
Consistency of ExplanationsAs mentioned in Section 2.3, the property of consistency in the FL setting, introduced in [60], is met if different participants receive the same explanation of an output obtained with the federated model given the same data instance.
Evidently, for all the different operative scenarios discussed in this paper, the explanations for the federated TSK-FRBS are consistent: any local explanation obtained in a given hospital depends only on the input instance and on the activated rule of the federated model.
Conversely, the approach proposed in [21] and adopted in this work as post-hoc technique for the MLP-NN explainability does ensure the consistency of the explanations only in the situation where the test instances are shareable to all the clients. The local explanation obtained in a given hospital, in fact, depends not only on the input instance and the federated MLP-NN, but also on the background dataset used for estimating the Shapley values. Since each hospital has its own private dataset, the Shapley values for the same input instance may differ, in general, from one hospital to another. The Federated SHAP approach allows obtaining an explanation for each test instance by averaging the local explanations from different hospitals. On one hand, this ensures that a unique and unambiguous explanation is obtained. On the other hand, this requires that any test instance is shared with other hospitals at inference time, which may be problematic due to privacy and/or latency issues.
Fig. 14
Shapley values for the MLP-NN for instance ID #2496 for each hospital. IID Scenario
Fig. 15
Shapley values for the MLP-NN for instance ID #2496 for each hospital. NIID-FQ scenario
In the following, we quantitatively assess the misalignment of client-side explanations obtained with SHAP for the MLP-NN, before applying the averaging operation that characterizes Federated SHAP. We consider an input test instance (ID# 2496, discussed also in the previous examples) and suppose that it is available at every hospital. Specifically, we evaluate how the prediction for such instance would be explained on different clients, in case that sharing Shapley values for averaging is precluded for privacy reason.
Figure 14 reports the Shapley values for each hospital and each feature in the IID scenario.
The barplot suggests that the explanations are consistent in the IID scenario, albeit showing some slight variability, which is reasonable since the background datasets are identically distributed. Indeed, explanations are in line with the average pattern reported in Fig. 14c.
The variability among client-side explanations turns out to be substantial in non-i.i.d. scenarios. Figure 15 shows the Shapley values for the same instance for each hospital and each feature when considering the NIID-FQ scenario. We recall that such scenario entails both a quantity skew and a feature skew on the age feature. Furthermore, it is worth mentioning that the feature selection process is part of the FL pipeline. As a consequence, the set of selected features depends on the data distribution scenario: this explains the presence of different features compared to the IID case, with Jitter(Abs) replacing HNR.
Figure 15 suggests that the misalignment of explanations is severe, especially for the contribution assigned to the age feature by different hospitals. The relevant Shapley value goes from negative in hospitals with younger patients to positive in hospitals with older patients. Probing the global model with data from heterogeneous distributions results in a difference also in the importance assigned to the DFA feature. In summary, the same instance, analyzed with the same model, is explained in very different ways on different hospitals. Thus, the property of consistency among explanations is not achieved.
The consistency of SHAP explanations in the FL setting can be achieved by avoiding the use of private training data as background: Chen et al. [63], for example, propose to use synthetic background datasets generated sampling from a Gaussian distribution whose parameters are estimated on the server side based on the contributions of all participants. However, such explanations may be different from those obtained using actual training data. Ensuring both consistency and accuracy of explanations, intended as agreement with the centralized case, is one of the interesting future developments of this work.
Comments (0)