
Remember me

A neutral expression corresponds to a static face image. On the other hand, a facial expression is generated elastically by the movement of face muscles. In poor illumination or low image resolution, the dynamic information due to movement is more useful in classifying a face image. This is because movement captures a three-dimensional view of the face. There appear to be two independent cortical areas in the human brain for remembering the static identity features and dynamic social features of a face [33]. The homogenous nature of a face image also requires a model that has high sensitivity in low-contrast vision.
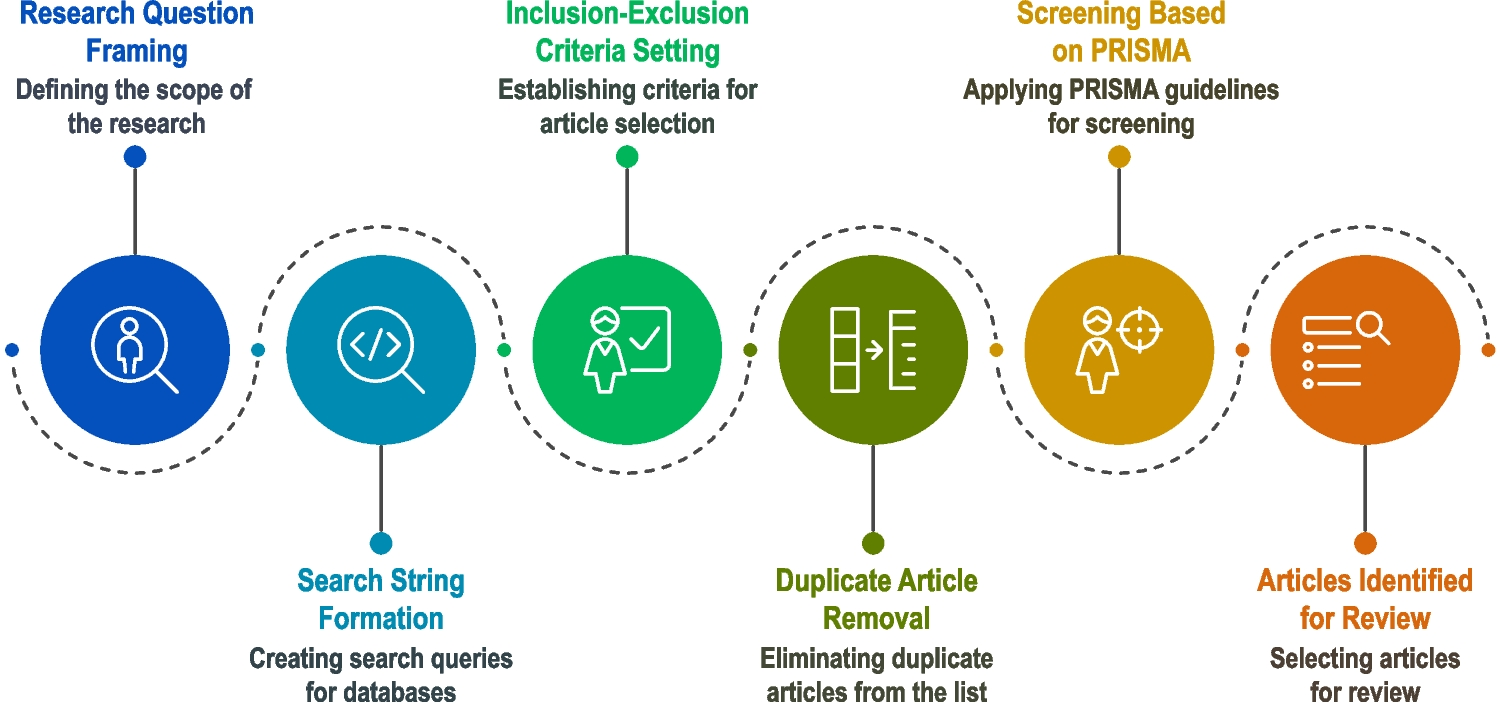
Validation of the proposed MES (available on GitHubFootnote 1) is done on three real-world datasets: (1) salt water diffusion prediction, (2) talking head generation from a piece of audio, (3) classifying facial expressions for children. The first dataset was synthetically generated using an FEM software. The other two datasets have been collected from human subjects.
ParametersTo model the elasticity of the medium, we apply ICA with a barrier function as described in ‘Barrier Function’. We consider ten spatial and temporal components for the ICA. Following previous authors [31], we set the gain \(\mu \) to 0.1 and the maximum movement intensity c to 5, the rate of change of the medium \(\lambda \) is set to 100, and the elasticity of the medium \(\gamma \) is set to 1. It is difficult to define fuzzy rules for a large number of input features; hence, we perform a dimensionality reduction using a NN. The NN is trained to predict the emotions from the landmarks and has a layer of five hidden neurons. The activations at these five neurons are used as training features for the fuzzy logic classifier. We first constructed a decision tree to determine eight starting rules for the fuzzy classifier as explained in ‘Fuzzy Rules for Modelling Prior’. We also allow the fuzzy classifier to learn up to 40 rules using genetic algorithm-based optimization with a crossover rate of 0.2. A low crossover rate will ensure that the model does not get stuck in a local minimum. We had to use the parallel computing toolbox in MATLAB to increase the speed of computation.
Salt Water DiffusionWe consider a coastal landscape where 23 barrier wells are installed very close to the sea lines and 23 production wells were installed close to fresh water. Using FEMWATER, we can define the landscape in a coastal region and place the production and pumping wells at desired locations. Next, we specify the pumping rates of the 46 wells using random Latin Hypercube sampling. The experiment was repeated 1000 times for a single configuration. We repeat this process several times for different locations of wells and conductivity ranging from 40 to 240 moles/day.
Table 1 compares the F-measure of the proposed algorithm with baselines for the binary task of predicting ‘fresh’ or ‘salty’ water at the monitoring well. We first train the model on 70% of ‘Batch1’ collected from a single FEM simulation. We then test it on the remaining 30% of ‘Batch1’. We can see that the simple neural network (NN) has the F-measure of 91%. The proposed model given by FuzzyB also has a very similar F-measure. However, if we do not use the barrier constraint, then the model denoted by fuzzy has a 30% lower F-measure of 59%.
Next, we tested the trained model on ‘Batch2’ data collected from a separate FEM simulation with different starting parameters. Here, the proposed method FuzzyB has a slightly higher F-measure of 71% compared to neural networks (NN). The improvement is 6% on the ‘salty’ class. The F-measure is over 15% higher than the baseline tree classifier that was trained on ‘Batch1’. Hence, we can conclude that the proposed approach has lesser overfitting and can show better accuracy on new datasets.
Lastly, we include the constraints that we wish to maximise the pumping of fresh water wells near agricultural land and minimise the pumping of barrier wells in coastal areas. In order to model the fuzzy classifier as an objective, we mimise the predicted label from FuzzyB. This is because we have set ‘fresh’ to 1 and ‘salty’ to 2 in the training data. Table 2 compares the F-measure of multi-objective (MO) and the proposed MES on salt water diffusion. We can see that MES has a higher F-measure than MO when considering the constraints. MO has a higher objective value for maximising the pumping of fresh water wells given by 2.98; however, MES has a lower objective value of 0.19 for minimising the pumping of barrier wells.
Table 1 Comparison of F-measure of baseline classifiers on salt water intrusionTable 2 Comparison of F-measure of multi-objective (MO) and the proposed MES on salt water diffusion and talking head datasetFig. 6
Mel spectrum for speech and the corresponding facial landmark. The top row is a sample for happy emotion. The bottom row is a sample from angry emotion in LRS2 dataset. The angry emotion has lower values of Mel coefficients. The oral cavity will change shape and hence the barrier to sound depending on the emotion
Talking Head: Face Audio and VideoNext, we apply the proposed approach to the prediction of facial landmarks from speech. This is a necessary component of models that can generate a talking video from a piece of text. To train the model, we used the Interactive Emotional Dyadic Motion Capture (IEMOCAP) which contains video recordings of conversations between two speakers [6]. There are a total of five female and five male actors and 12 h of audio-visual data. Each video is segmented into utterances that has an emotional label such as happy or angry. The database was designed to capture the relationship between gestures and speech hence most of the faces are captured sideways. Theatre scripts were selected with the requirement that the play conveys target emotions. Subjects were asked to memorise and rehearse the scripts. Here, we only consider a subset of 502 utterances that have been labelled as happy or angry. We extracted 128 Mel coefficients for each frame in a video and used a window size of four frames resulting in an input vector of 512 features. We used pre-trained weights for speech-to-landmark prediction to initialise the LSTM [34].
We test the model on an additional Lip Reading Sentences (LRS2) dataset consisting of thousands of spoken sentences from BBC television recorded between 2010 and 2016 [1]. Video shot boundaries were determined by comparing colour histograms across consecutive frames. Forced alignment was done between the video, audio, and subtitles for each shot. Lastly, sentences were determined using punctuations such as full stops and question marks in the subtitles. Each sentence is restricted to 100 characters in length. Figure 6 shows the Mel spectrum for speech and the corresponding facial landmark. The top row is a sample for happy emotion. The bottom row is a sample from angry emotion in LRS2 dataset. The angry emotion has lower values of Mel coefficients. The oral cavity will change shape and hence the barrier to sound depending on the emotion.
Here, we first predict the facial landmarks from speech audio using LSTM, and then we predict the emotion label of the predicted face as ‘angry’ or ‘happy’. Table 3 compares the F-measure of the proposed algorithm with baselines. We transform the speech input using the barrier function and train the model denoted by LstmB. We can see it has a much higher F-measure of 51% compared to the baseline Lstm of 40%. Next, we train the fuzzy classifier with the landmarks predicted by LstmB denoted as LstmB-Fuzzy. We can see that when tested on a new dataset LSR2, the F-measure on ‘angry’ class is much higher than baselines. This confirms that the fuzzy model is better suited to real-world datasets.
Lastly, we introduce some constraints using facial action units. We find that ‘anger’ emotion results in ‘lip puller’ and ‘open eyes.’ On the other hand, ‘happy’ emotion has the action units ‘lip stretcher’ and ‘closed eyes’. The third objective is to mimise the label of the FuzzyB model so that it is either ‘anger’ or ‘happy’ based on the constraints. Table 2 shows the F-measure of MES is higher than MO on both emotions. It also achieves a lower minimisation and higher maximisation on the constraints specified.
Table 3 Comparison of F-measure of baseline speech-to-landmark sentiment classifiersChild Facial ExpressionsLastly, we evaluate the model of facial landmarks for different emotions in children [35, 36]. For each emotion, such as ‘happy’ or ‘surprise’, we train a binary classifier with respect to the neutral expression. The Child Affective Facial Expression (CAFE) dataset has 90 female and 64 male children. Photographs are captured from children in the age group of 2 to 8 years. Unsuccessful poses were removed from the dataset. The FaceMeshFootnote 2 by MediaPipe model detects 468 key face landmarks in real time. For each image, we extract 468 landmark points using FaceMesh. These landmarks define the location of the eyes, nose, mouth, and cheeks. We refer to FACSFootnote 3 (Facial Action Coding System) to determine the action units in different emotions. For example, when a person is happy, then the mouth area will be maximised. We use the FACS to determine multiple objectives for each emotion.
Table 4 Comparison of F-measure of baseline sentiment classifiers on facial landmarksHere, we consider the subset of 420 images for ‘happy’ (215) and ‘angry’ emotions (205). Each landmark is defined by the X, Y, and Z coordinate, resulting in 1434 input features. Table 4 compares the F-measure of the proposed algorithm with baselines for the binary task of predicting ‘angry’ or ‘happy’ expressions from face landmarks. We first train the model on 70% of CAFE data images and test on the remaining 30%. We can see that the NN has a F-measure of 82%. The proposed model given by FuzzyB also has a very similar F-measure. However, compared to a decision tree classifier, the improvement is over 10%.
Next, we tested the trained model on IEMOCAP dataset described in the previous section. This balanced dataset contains 502 images of ‘Happy’ and ‘Angry’ face images of speakers. Here the proposed method, FuzzyB has the best result in the Happy class with a 55% F-measure. We can see that the baselines such as NN and tree are unable to classify a new dataset, suggesting that they are overfit to the training data. Hence, we can conclude that fuzzy rules can adapt to new datasets. It is currently difficult to map the 468 3D landmarks to 2D facial actions; hence, we did not report multi-objective results on this dataset.
Comments (0)