
Remember me
A total of 302 adolescents between the ages of 13 and 17 years (mean age = 15.47, SD = 1.47 years; 57% male), from 101 treatment centers in the United States, South America, Europe, Asia, South Africa, and the Caribbean were randomized into the 6 week double-blind trial. Baseline data analyses used N = 302, and supplemental psychometric analyses of later data either used all available visits or last observation carried forward (LOCF).
Confirmatory factor analysesTable 1 reports fit indices for both one- and five-factor models with 10, 20, or 30 items. The five factors (Withdrawal/Apathy, Thought Disturbance, Aggression, Internalizing, and Delusions/Odd Content) were specified a priori based on prior results [1, 5, 6] with the specified loadings indicated in supplemental Tables 1a–c, available online. Analyses based on different item sets are not statistically “nested,” precluding direct comparisons of model fit. CFA model parameterization was identical to that in Findling et al. [2] and Youngstrom et al. [5].
Table 1 Comparison of fit indices for confirmatory factor analyses of one and five factor models based on 30, 20, and 10 items (N = 302)In all three item sets (Table 1), the performance of the five-factor models surpassed that of the single-factor models. In the 30-item set, the five-factor model exhibited inadequate fit according to all indices, and three items demonstrated only modest loadings (< 0.33) on their respective factors (G12 Lack of judgment and insight loaded at 0.17, G1 Somatic concern at 0.25, and N7 Stereotyped thinking at 0.325). Conversely, the 10 and 20 item five-factor models displayed satisfactory fit (supplemental Table 1), with all items showing significant loadings on the appropriate factors.
Reliability and precisionTable 2 shows the reliability and precision estimates for the composite scores. The average inter-item correlation was 0.15 for the 10 items and the 30 items, and 0.16 for the 20 items. OmegaTotal ranged from 0.84 (PANSS10) to 0.90 (PANSS30). OmegaTotal is conceptually the most appropriate reliability estimate for a total score on the PANSS, as the total is creating a composite sum across five different and only modestly correlated factors [10].
Table 2 Reliability, correlation with full-length scale, and length reduction for composite scores (scaled as item averages, ranging from 1 to 7) using baseline data from acute phase (N = 302)It also is possible to estimate how accurate the total score is as an overall measure of the items being assessed (OmegaHierarchical), as well as how much the total score conveys reliable information about the five underlying specific factors (Withdrawal/Apathy, Thought Disturbance, Aggression, Internalizing, and Delusions/Odd Content) (OmegaSpecific). Table 2 includes these estimates as well. The OmegaHierarchical estimates ranged from 0.69 to 0.73, suggesting that the total score is a mediocre measure of overall severity.
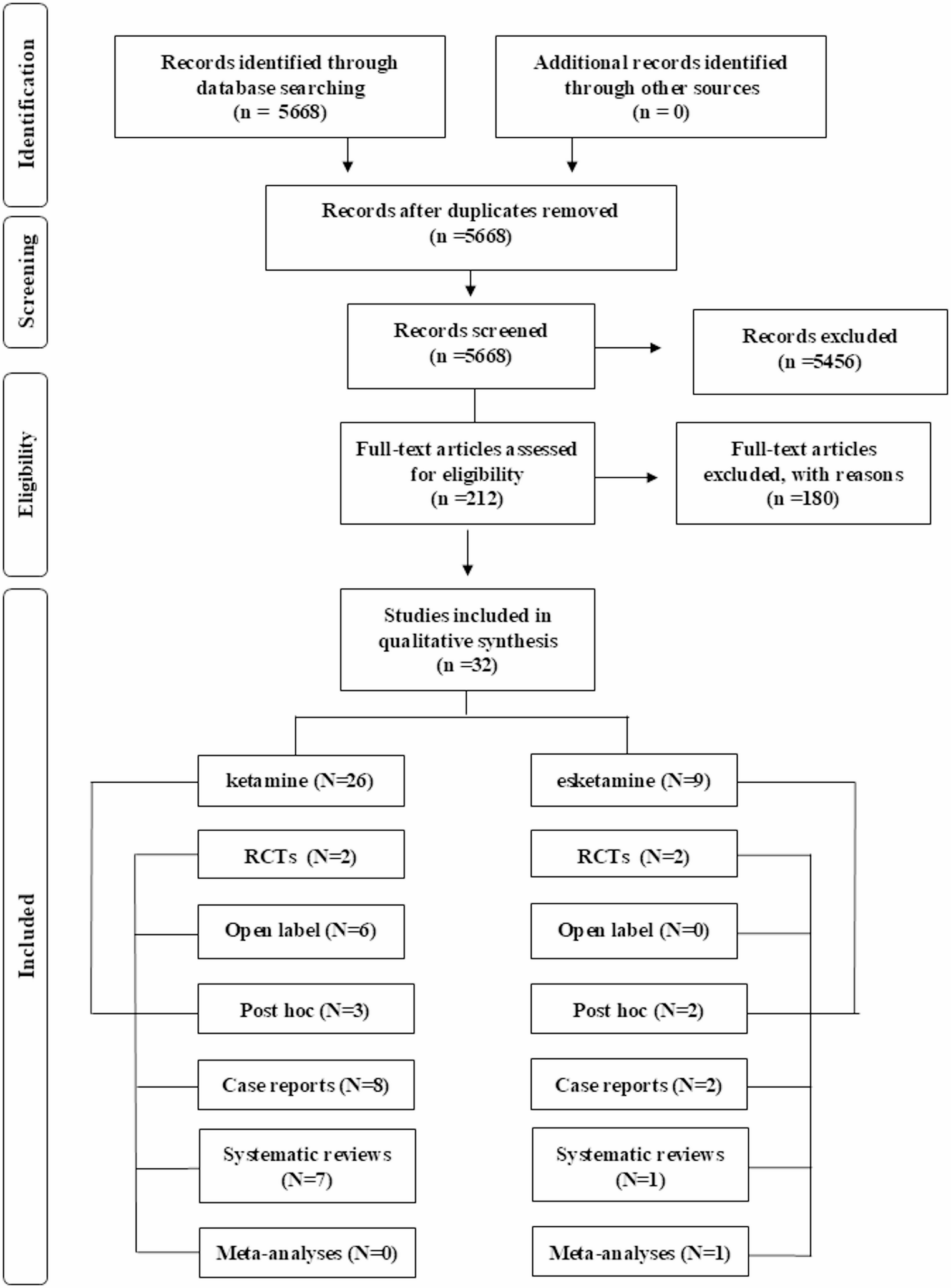
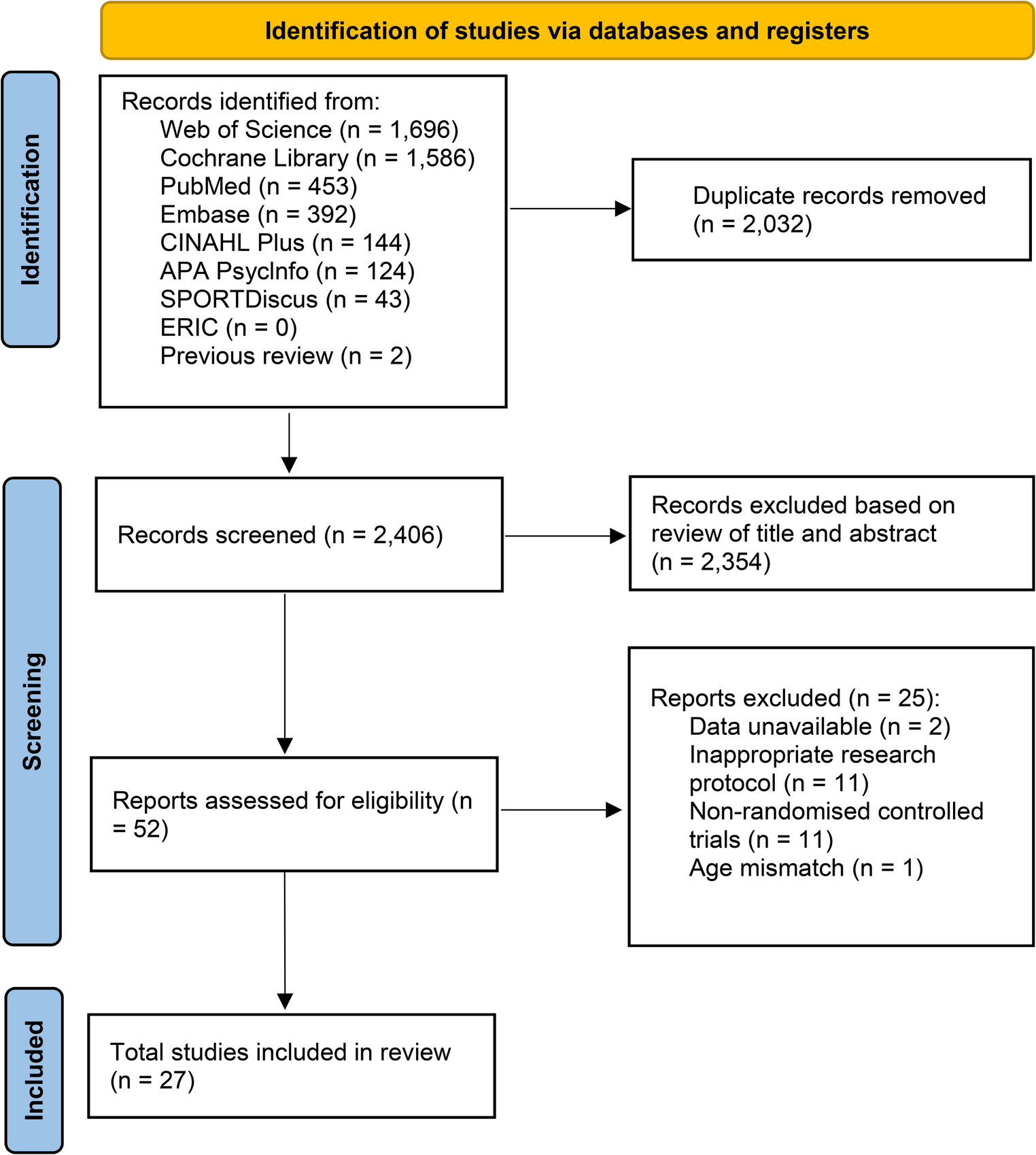
Item response theory analyses showed that the PANSS10 composite had reliability > 0.80 between theta levels of – 2.0 to + 4.4 standard deviations above the average trait level (see Fig. 1). The 2-item subscales also showed reliability > 0.80 across a broad severity range (see Fig. 2), even better than found in the original TEOSS sample where we built the 10 and 20 item scales [2]. The PANSS20 form had reliability > 0.80 over an even wider severity range, spanning from – 2.7 to + 5.4. For both the 10- and 20-item analyses, option characteristic curves appeared very good for the subscales. Detailed item option characteristics are available as supplemental tables.
Fig. 1
Reliability coverage of composite scores based on graded response model (N = 302)
Fig. 2
Item Response Theory (IRT) information and reliability estimates for short forms (N = 302). From https://en.wikiversity.org/wiki/Evidence_based_assessment/Instruments/PANSS, CC-BY 4.0
In contrast, IRT analyses of the PANSS30 items found many items with flat information curves (e.g., G1, G3, G6, P4, P5, G10) and implausible parameter estimates. All of these patterns are with the poor loadings in the one-factor CFA model, and also consistent with prior results from both our group [2, 5] and others [14]. Further, reliability for the PANSS30 total was > 0.80 from theta – 3.2 to 6.0. The zone of reliable scores is essentially identical to that offered with the short versions, and in clinical practice, the furthest extremes are unlikely to be encountered. Supplemental materials contain the supporting results and figures.
Table 2 provides the standard errors of measurement (SEM) and the difference score (SEdiff) for two administrations of the same form, as well as critical values for 90% and 95% confidence differences. These values help determine if a patient's score at two different time points indicates a "reliable change." Furthermore, the table includes a benchmark for the "minimally important difference (MID)," which has been posited to estimate the smallest change that is likely to be considered clinically meaningful [15].
Supplemental analyses checked the reliability coefficients in all available observations, in addition to the baseline scores. The reliability estimates all increased considerably over time, consistent with both theory and prior observations [5] (see supplemental materials). Treatment often increases the variability between patients, both because they have varying treatment response, in addition to enrollment criteria often restricting the range of scores at study entry [16, 17].
Content coverage, accuracy, and assessment of biasContent coverage was excellent, r = 0.87 for the PANSS10 and 0.97 for the PANSS20 with the full-length scale using the baseline scores, and r = 0.94 for the PANSS10 and 0.97 for the PANSS20 with the full-length scale based on all observations across all waves (all p < 0.00005). All were larger than the projected correlations estimates based on the internal consistency and reduced scale length, rhat = 0.76 for a PANSS10 version and 0.84 for the 20 items.
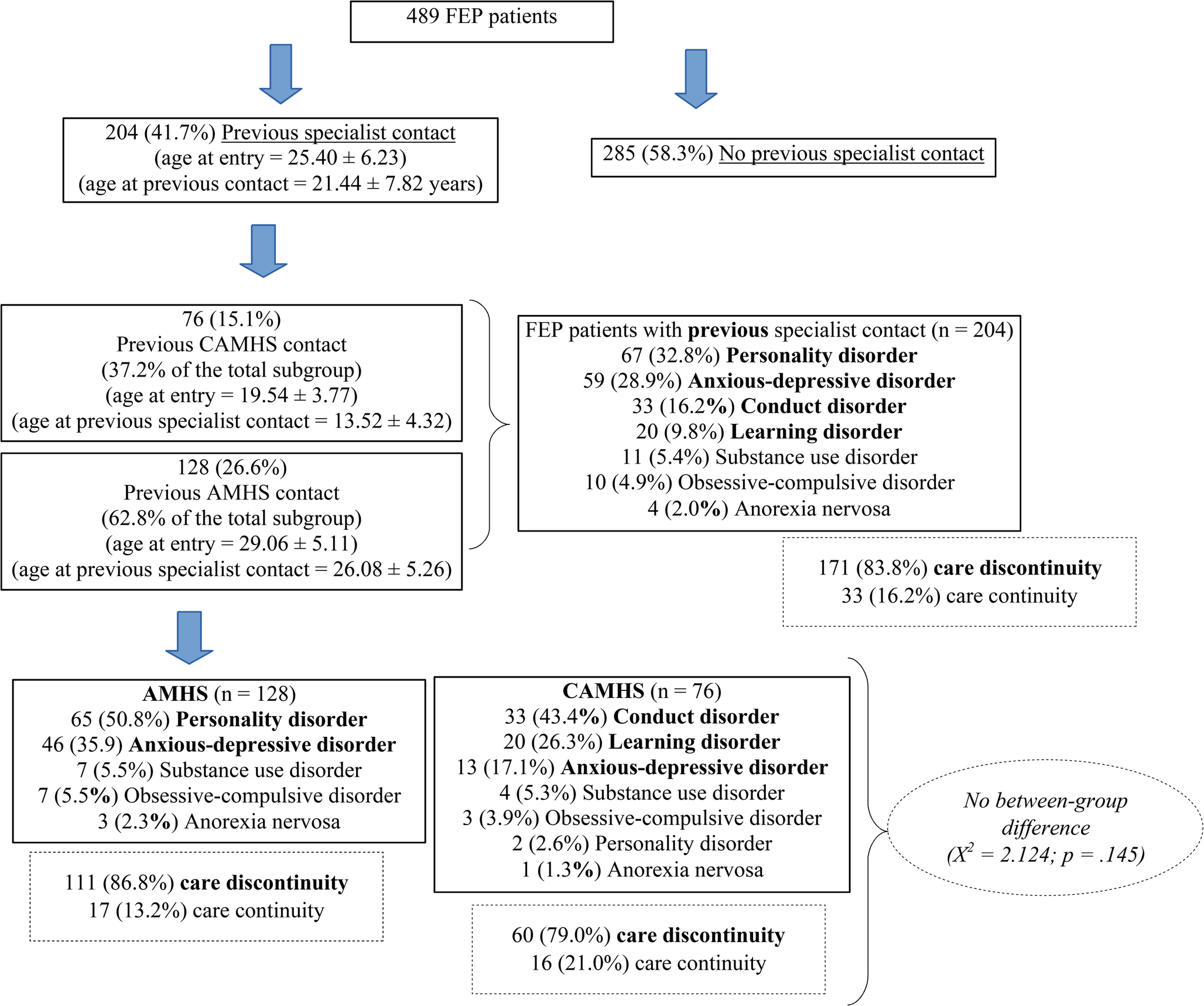
We used regression analyses and Bland–Altman plots to check reproducibility and potential miscalibration or bias comparing the short forms to the full length. Results indicated a slight tendency for short form scores to trend higher than the full length as scores increased; however, the average discrepancy was negligible (i.e., < 0.1 points on average), and only statistically detectable at moderate to high score levels (e.g., item score averages of 3 or higher). Of note, the average discrepancies were smallest in the score range used as an enrollment criterion for the trial (e.g., average discrepancy of zero at observed scores around an item average of 2.0, or a PANSS30 total sum score of 60). Figure 3 shows these results for the PANSS10 (for the PANSS20, see Supplemental Fig. 1). These findings also closely replicate what we found in prior analyses in the earlier referenced paliperidone sample. [5].
Fig. 3
Bland–Altman Plots comparing accuracy of PANSS10 to the PANSS30 scores, N = 302. Scores are scaled as item averages, ranging from 1 to 7. Dashed line indicates average bias; blue line is regression
Convergent correlations with CGI-S ratingsTable 3 reports correlations for the three PANSS version totals and the CGI-S, which was the other primary outcome measure in the clinical trial. The PANSS10 and PANSS20 both correlated 0.55 with the CGI-S at baseline, versus the PANSS30 showing a 0.59 correlation. Because of the very high correlations the short forms showed with the full-length PANSS (0.87 and 0.97), the Steiger test of the difference between paired correlations was statistically significant, t = 3.60, p = 0.0004 for the PANSS20, albeit being too small to be of practical concern. The PANSS10 did not differ significantly in CGI-S correlation versus the 30-item, t = 1.61, p = 0.109.
Table 3 Criterion correlations for full-length, PANSS10 and 20-item pediatric PANSS short forms (N = 302, N = 1914 observations for change from baseline eta-squared)Sensitivity to change during treatmentThe PANSS10, PANSS20, and PANSS30 totals produced essentially identical estimates of treatment effects based on several analyses. Pre-post effect sizes using last observation carried forward (LOCF) yielded eta-squared values for time from 0.22 to 0.23, all p < 0.00005, showing large and essentially identical improvement estimates. The main effects for treatment and time-by-treatment were all eta-squared < 0.015 (with all reaching nominal p < 0.05 except for time*treatment using the PANSS10, which was p = 0.066, before any post hoc correction versions.
Comments (0)