
Remember me




Task-evoked functional magnetic resonance imaging (fMRI) studies, such as the Human Connectome Project (HCP), are a powerful tool for exploring how brain activity is influenced by cognitive tasks such as memory retention, decision-making, and language processing. In the HCP, a core set of tasks was devised aiming to delineate the functionally unique nodes within the human brain to establish connections between tasks and activation signatures in critical network nodes (Barch et al., 2013). These data have motivated the work presented here.
Brain imaging data are often represented in the form of a multi-dimensional array, called a tensor. These arrays can be seen as functions of space and/or time. In multi-subject studies, it is of interest to relate these functional response data to a set of scalar predictors through a function-on-scalar model. Due to the high-dimensionality of the functional response, most models in the literature will employ a form of regularization. Regularization involves borrowing strength across observations within a function. Although regularization can be achieved through various methods such as penalized regression methods or/and sparse-inducing priors, one very important approach is by the use of basis functions. Each basis function defines a linear combination among the locations within the function, establishing a framework for borrowing strength between observations. Commonly used basis functions are splines, Fourier series, wavelets, and principal components (PCs; Morris, 2015). Some specific basis functions tailored to fMRI data are also available in Miranda and Morris (2021) and in Haxby et al. (2020). The former is based on a composite-hybrid basis obtained from a principal component analysis and the latter is based on the generalized Procrustes analysis.
Some efforts have been devoted to analyzing neuroimaging as tensor data. In one line of research, the CP decomposition is used as a descriptive tool to represent multisubject and multisession fMRI data. The resulting spatial patterns or modes of the tensor representation are, in turn, validated by visual inspection. The extracted components in each spatial, temporal, runs, among other dimensions, can be further inspected to describe variability in each of these directions (Andersen and Rayens, 2004). Although this descriptive decomposition is useful, it is often of interest to relate the tensor neuroimaging data with other variables such as age, gender, and sex, disease status, through a regression analysis framework.
Previous research that tackles tensor regression are models in which the response is a scalar and the predictor is a tensor (Zhou et al., 2013; Guhaniyogi et al., 2017; Li et al., 2018; Miranda et al., 2018). Commonly in these approaches, the goal is to understand the changes of the response outcome as the tensor variable changes. Often, a tensor decomposition is implemented as tool for dimensionality reduction of tensor covariates. For example, the authors in Miranda et al. (2018) use this approach to predict Alzheimer's Disease status as a function of magnetic resonance imaging data through a CP decomposition of the imaging covariate.
Meanwhile, tensor response regression aims to study the change of the image as the predictors such as the disease status and age vary. Research in this direction often propose a low-rank tensor decomposition of the coefficients associated with covariates (Rabusseau and Kadri, 2016; Spencer et al., 2020). In a different application context, Lock and Li (2018) propose a likelihood-based latent variable tensor response regression, where the tensor data corresponds to latent variables informed by additional covariates. The authors apply their model to a 2D facial image database with facial descriptor.
Although aiming to address the same type of problem, our proposal is methodologically distinct from these previous approaches. Here, we use the CP tensor decomposition to construct a tensor basis function that not only determines the mechanisms for borrowing information across voxels but also effectively reduces the dimensionality of the brain data, which is projected onto the basis space. The projected data are in turn modeled as functions of covariates of interest using a Bayesian MCMC algorithm. This approach is inspired by the wavelet functional mixed models proposed in Morris and Carroll (2006) and further developed in Morris et al. (2011), Zhu et al. (2011, 2018), and Zhang et al. (2016). The novelty of the methodology here is that the CP decomposition captures the 3D spatial brain intricacies across different subjects and concatenation of the spatial directions does not happen as in wavelet basis or principal components. We apply this approach to a second-level analyzes (as explained in Section 2) of fMRI data from the one hundred unrelated subjects of the HCP data. The method, however, extends to a vast range of imaging modalities such as structural MRI images, and electroencephalography data.
The rest of the paper is organized as follows. In Section 2 we introduce the CP decomposition and estimation method, including a brief review of tensor concepts and properties (Section 2.1) and a review of the method used to obtain subject-level brain maps for fMRI task data (Section 2.2, and the design the CP tensor basis functions with the Bayesian modeling approach (Section 2.3). In Section 3 we apply the proposed approach to the Working Memory data from HCP to find population-level maps of a particular Working Memory contrast. In Section 4 we provide some concluding remarks and directions for future work.
2 MethodsThe proposed approach involves a two-stage procedure. In the first stage, the 4D data for each subject are modeled through the Bayesian composite-hybrid basis model proposed in Miranda and Morris (2021) and described in Section 2.2. In the second stage, posterior means of contrast brain maps are modeled by the CP tensor basis model. This modeling strategy is flexible, as subject-level maps can be estimated by any known single-subject estimation technique and combined into coefficients maps for any contrasts of interest. Furthermore, these maps are assembled into a 4D tensor (3D volume and subjects) to be associated with population-level covariates, e.g., age and sex.
2.1 BackgroundWe review a few important concepts and operations necessary for the comprehension of this manuscript. For an exhaustive review on tensor decomposition and applications (see Kolda and Bader, 2009).
2.1.1 Working with tensorsA tensor is a multidimensional array with order given by the number of its dimensions, also known as modes. For example, a matrix is a tensor of order 2. A tensor X∈ℝI1×I2…×IK of order K is said to be a rank-one tensor if it can be written as an outer product of K vectors, i.e.,
X=a(1)∘a(2)∘…∘a(K),where ° is the outer product of vectors. This is equivalent to writing each element of xi1i2…iK=ai1(1)ai2(2)…aiK(K), for 1 ≤ ik ≤ iK.
Matricization or unfolding of a tensor is the process of reordering the tensor into a matrix. We will denote the mode-n matricization of the tensor X above as X(n) and arrange the mode-n dimension to be the columns of X(n). Please see Kolda and Bader (2009) for how the observations are arranged for a general tensor order. As an example, consider the matricization of a tensor X∈ℝ2×3×4. The mode-3 matricization X(3) is a matrix of size 6 × 4 where, for a fixed column k in the matrix, we have elements x11k, x21k, x12k, x22k, x13k, x23k in the kth row.
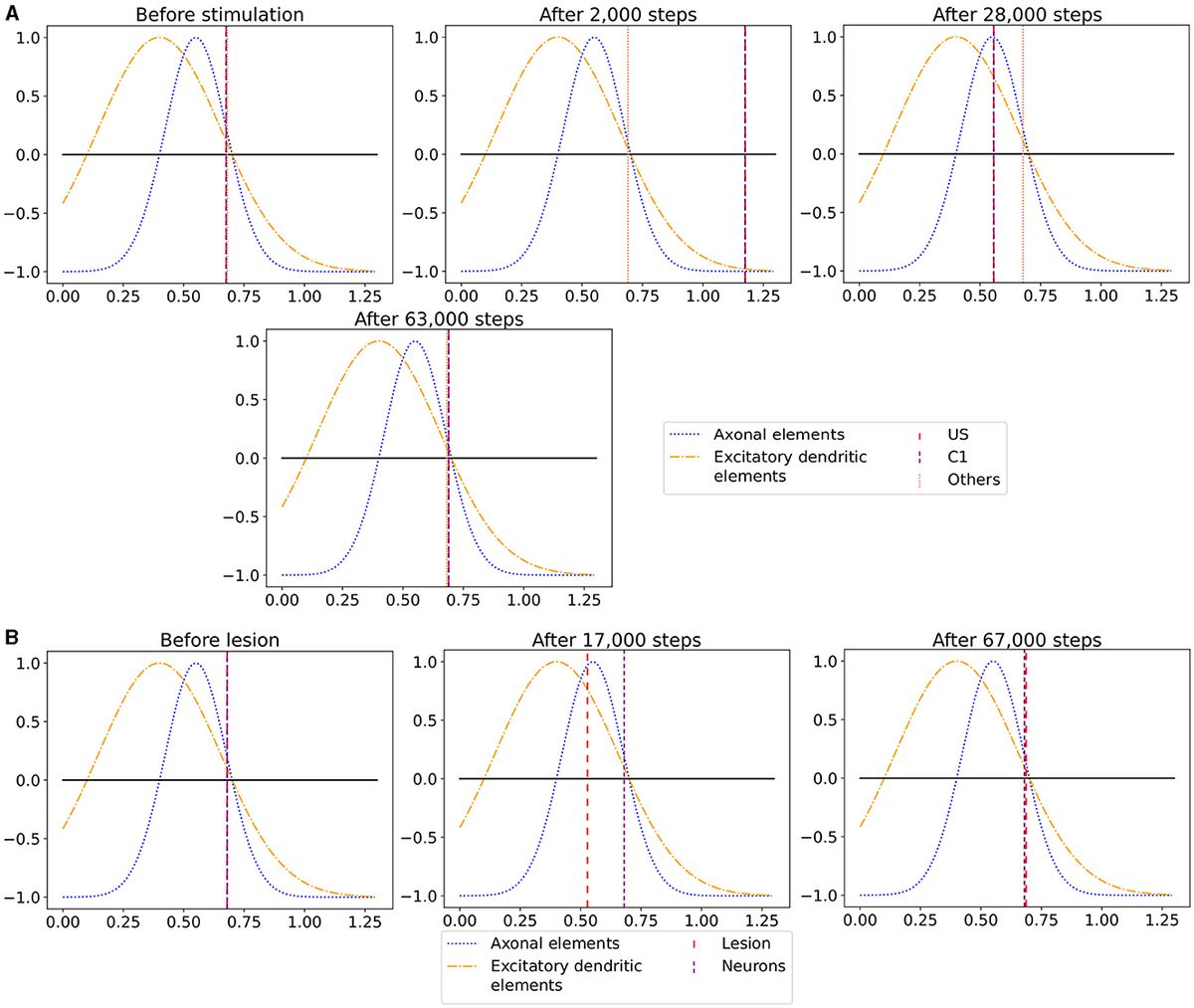
Tensor decompositions are higher-order generalizations of the singular value decomposition and principal component analysis. Although there are various tensor decomposition methods, we focus here on the Canonical Polyadic (CP). The CP decomposition factorizes a tensor as a sum of rank-one tensors, as illustrated in Figure 1 for a tensor of order four.
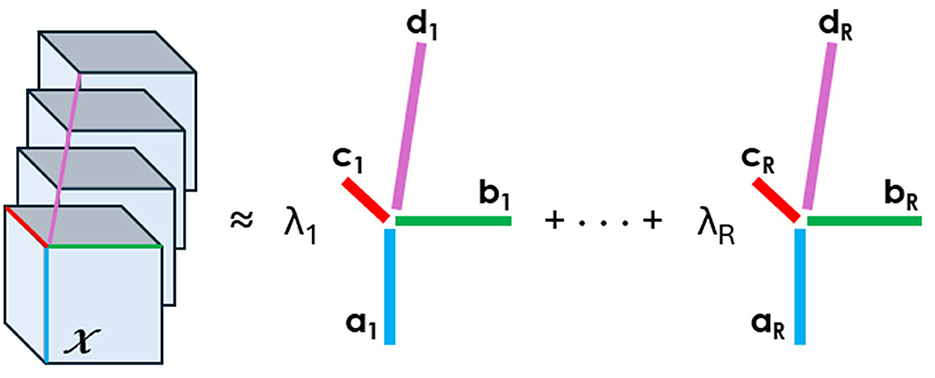
Figure 1. CP decomposition of a 4D array into the sum of rank-one tensors. An element of the tensor on the left can be written as the sum of the products of the elements in vectors a,b,c, and d, e.g., xj1j2j3j4=∑r=1Rλrarj1brj2crj3drj4.
Mathematically, we write the CP decomposition above as
X≈ 〚λ; A,B,C,D〛≡∑r=1Rλr ar∘br∘cr∘drThe factorization means that every element of the four-dimensional array X∈ℝJ1×J2×J3×J4 can be written as xj1j2j3j4=∑r=1Rλraj1rbj2rcj3rdj4r, where the vectors ar∈ℝJ1, br∈ℝJ2, cr∈ℝJ3, and dr∈ℝJ4 form the columns of the factor matrices A,B,C, and D.
The factor matrices refer to the combination of the vectors from the rank-one components, i.e., A = [a1a2…aR] and likewise for B, C, and D. We assume that the columns of A, B, C, and D are normalized to length one, with the weights absorbed into the vector λ∈ℝR. The approximation refers to the estimation of the factor matrices that minimize the Frobenius norm of the difference between X and ⟦λ;A,B,C,D⟧ (Carroll and Chang, 1970).
2.2 Subject-level modelingFor each voxel v = 1, …, Nv in a volumetric image, the task fMRI response function is a time series of T time points based on the Blood Oxygen Level Dependent (BOLD) contrast (Ogawa et al., 1990). These measurements are an indirect and non-invasive measure of brain activity and can be modeled as a function of the external stimuli:
yt(v)=∑j=1pbj(v)xj(t)+et(v), (1)where xj(t) is the covariate for stimulus j, representing the indicator function of stimulus j at time t convolved with the hemodynamic response of a neural event at time t (Lindquist, 2008), and et(v) is a measurement error. The coefficients bj(v) characterize the relationship of brain activity during stimulus j. The primary goal of activation studies is to identify which voxels are differentially activated by specified stimuli.
There are many ways to estimate the coefficient maps bj(v), including the popular general linear model available through the software SPM (Friston et al., 2006). The model in Equation 1 can be written in matrix form as:
To estimate the brain maps B∈ℝp×Nv, we will use the Bayesian approach proposed in Miranda and Morris (2021), which consists of fitting a basis-space model:
This can be written in vectorized form as:
vec(Y*)=(IS⊗X*)(IS⊗B*)+vec(E*),with vec(?*) = (ΨTΦT ⊗ W)vec(?) and vec(?*) = (ΨTΦT⊗W)vec(?). In summary, the authors' tensor basis approach consists of choosing the set of bases to account for global and local spatial correlations and long-memory temporal correlations. A Bayesian MCMC is proposed and samples from the coefficient maps are obtained in the basis space, and the inverse transform is applied to obtain the MCMC samples in the voxel space. For more details, refer to Miranda and Morris (2021).
2.3 Multi-subject modelingLet Y be the 4D tensor representing each coefficient map or contrast map for all N subjects. Then Y∈ℝp1×p2×p3×N. We can model Y as a function of p subject-level covariates Z∈ℝp as follows:
where Y is a N × Nv matrix representing the mode four unfolding of the tensor Y with Nv = p1 × p2 × p3 being the number of voxels; Z is a N×p design matrix of p subject-level covariates; γ is a p × Nv matrix of coefficients; and E is a N×Nv matrix of random errors.
Properly modeling the data as in Equation 2 is challenging due to its very large number of voxels, typically around a million, and the spatial dependency inherited from the brain volume data. Most Bayesian models rely on either downsampling the volume data to reduce the number of voxels or rely on simplified assumptions on the prior of γ and/or E. The solution proposed here involves projecting the data into a basis space through a tensor basis obtained from the CP decomposition of the tensor Y. This decomposition is low rank and effectively extracts brain volume features that are common to all subjects. By extracting the common features, the remaining information is subject-specific and can be then related to the covariates of interest.
The CP decomposition of Y is given by:
Y≈∑r=1Rλrar(1)◦ar(2)◦ar(3)◦gr≡⟦λ;A(1),A(2),A(3),G⟧, (3)where the vectors ar(1)∈ℝp1, ar(2)∈ℝp2, ar(3)∈ℝp3, and gr∈ℝN. The matrices A(1), A(2), A(3), and G are called factor matrices and their columns are associated with these vectors. From Kolda and Bader (2009), we can write Y from model (Equation 2) as:
Y=GΛ(A(3)⊙A(2)⊙A(1))T+ϵ,where G, A(1), A(2), and A(3) are estimated to minimize the Frobenius norm of ϵ (Kolda and Bader, 2009). Let L=Λ(A(3)⊙A(2)⊙A(1))T∈ℝNv×R, then P =L†, the Moore-Penrose pseudoinverse of L, provides a projection matrix formed by spatial basis that can be used to effectively reduce data from Nv to R spatial locations.
Based on the projection matrix, we multiply both sides of Equation 2 by P to obtain the basis space model:
where γ* =γP is the p × R matrix of coefficients in the basis space, and E* =EP is a N × R matrix of random errors.
2.3.1 Basis-space Bayesian modelingThe columns of G are correlated due to the nature of the CP decomposition, and model assumptions should reflect that. For each row of E*, we assume Ei*~NR(0,Σϵ) and priors:
p(γ*,Σϵ)=p(Σϵ)p(γ*|Σϵ),with γ*~MN(g0,L0-1,Σϵ) and Σϵ~W-1(V0,ν0), where MN indicates the matrix normal distribution and W−1 indicates the Inverse Wishart distribution. The joint posterior distribution of γ*,Σϵ|G,Z factorizes as a product of an Inverse Wishart and a Matrix Normal distributions as follows:
Σϵ|G,Z~W-1(Vn,νn),γ*|G,Z,Σϵ~MN(gn,Ln-1,Σϵ),with:
Vn=V0+(Y-Zgn)T(Y-Zgn)+(gn-g0)TL0(gn-g0),νn=ν0+N,gn=(ZTZ+L0)-1(ZTG+L0g0),Ln=ZTZ+L0.Sampling from these distributions is straightforward and done through Gibbs sampling.
2.3.2 Rank selectionTo choose the appropriate rank for the CP decomposition, we propose a 10-fold cross-validation procedure with the following steps for each of the training/test set combination:
1. Obtain the factor matrices of the CP decomposition for the training data,
2. Proceed to estimate γ* from model Equation 4 following the MCMC algorithm detailed in Section 2.3.1,
3. Using γ*^ from the previous step and ZTest, estimate GTest=ZTestγ*^,
4. Obtain Y^Test=⟦λ;A(1),A(2),A(3),GTest⟧ as in Equation 3,
5. Choose the rank that minimizes the Frobenius norm of the average of the YTest-Y^Test, obtained across the training/test sets.
2.3.3 Inference on the brain spaceFor every MCMC sample of γ*, we obtain γ =γ*L in the original voxel space. To control for the experimentwise error rate in the voxel space, joint credible bands as in Ruppert et al. (2003) can be calculated. For each voxel v, a joint 100(1−α)% credible interval for any group-level contrast C is given by
Iα(v)=Ĉ(v)±q(1-α)[std^(Ĉ(v))],where the quantile q(1−α) is obtained from z(1), …, z(M) with z(m)=maxv∈V|C(m)(v)-Ĉ(v)std^(Ĉ(v))|, for m = 1, …, M and M is the total number of MCMC samples after burn-in and thinning (Miranda and Morris, 2021).
These joint credible bands account for multiple testing across the voxel space and can be inverted to flag activation signatures based on voxels for which the 100(1−α)% joint credible bands exclude zero (Meyer et al., 2015; Miranda and Morris, 2021). Denote by PSimBaS the minimum α at which each interval excludes zero (PSimBaS = min). PSimBaS can be directly computed by
PSimBaS(v)=1M∑m=1M1. (5)These are probabilities of the simultaneous band scores. For an specific value of α, we can identify v for which PSimBaS(v) < α as significant. This is equivalent to checking if the joint credible intervals, Iα(v), cover zero at a specific α-level (Meyer et al., 2015).
3 Application to the HCP dataThe proposed model is applied to the 100 unrelated subjects data from the Working Memory task of the Human Connectome Project. The volumes considered were collected from the right-left phase. The experiment consists of a total of eight blocks, half corresponding to the 2-back task and the other half the 0-back task. In each block, the participants were shown a series of 10 images. Images corresponding to 4 stimuli (tools, places, body parts, and faces) were embedded within the memory task. Each image was shown for 2.5 s, followed by a 15 s inter-block interval. fMRI volumes were obtained every 720 ms (TR). Each volume consisted of images of size 91 × 109 × 91 for a total of 405 time frames.
3.1 Subject-level analysisWe follow the analysis described in Section 2.2. To obtain the local spatial basis, we partitioned the brain into ROIs using a digitalized version of the original Talairach structural labeling that was registered into the MNI152 space. The atlas can be obtained from the FSL atlas library with information found at: https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/Atlases (Jenkinson et al., 2012). We considered ROIs that had at least 125 voxels and obtained a total of 298 regions. Within each region, the local basis Φ was formed by the eigenvectors of the SVD decomposition for the matrix data in each ROI as described in Miranda and Morris (2021). Next, the global spatial basis Ψ was obtained by first projecting the brain data using the local basis and then calculating the SVD decomposition of the projected data, exactly as in Miranda and Morris (2021). The temporal basis W was chosen to be the Haar wavelet. The estimation was performed at the cluster Cedar managed by the Digital Research Alliance of Canada (former Compute Canada). The jobs were submitted in parallel for the 100 subjects and results took an hour to finish.
For each subject, after estimation, we constructed a contrast map of the 2 vs. 0 back working memory task. The maps were obtained from the posterior means of the coefficients, and assembled into a 4D array Y∈ℝ91×109×91×405.
3.2 Multi-subject analysisWe take the tensor Y containing the posterior means of the contrast 2 vs. 0 back for the maps obtained in the single-level analysis. Next, we follow the method proposed in Section 2.3 to estimate the coefficients maps γ for the mean of 2 vs. 0 back and the covariate Sex. We are interested in finding common activation maps for all subjects and aim to investigate if there are differences in working memory task based on sex. Next, we obtain the CP decomposition of the tensor Y, taking R = 30 selected based on the cross-validation procedure described in Section 2.3.2. Figure 2 shows the Frobenius norm as a function of the rank, for rank values R = 10, 15, 20, 25, …, 80. Following the decomposition, we aim to identify significant locations in the brain for the Working Memory task 2 vs. 0 back, we proceed as follows.
(i) Obtain MCMC samples for γ*, as detailed in Section 2.3.1.
(ii) Use the inverse transform of P, L=Λ(A
Comments (0)