
Remember me





We conducted an experimental proof-of-concept study to evaluate the feasibility and performance of a deep learning-based computer vision model for automated surgical tool detection and counting. The study was performed at the Department of Urology, Mayo Clinic, Rochester, Minnesota, USA, between January 2024 and May 2024.
HypothesisWe hypothesized that a deep learning-based computer vision model could accurately detect and classify surgical instruments in real-time from a standard surgical table, potentially serving as an AI safeguard against RSIs.
Primary and secondary outcomesThe primary outcome was the model’s performance in detecting and classifying surgical tools, as measured by precision, recall, and mean average precision, standard measures to benchmark the performance of computer vision models. The secondary outcome was the model’s inference speed (frames processed per second) when applied to real-time surgical video, to assess its suitability for real-world surgical applications.
DatasetFollowing Mayo Clinic Institutional review board approval, we developed a de novo dataset consisting of photos of various combinations of commonly used surgical tools, including scalpels, surgical scissors, forceps, hemostats, needle drivers, surgical retractors, surgical skin markers, beakers, syringes, surgical gauzes, and basins. Each image contained several different types of instruments to simulate a real-world surgical tray setup. Each individual tool appeared in several different photos. Each image contained up to four each of scalpels, needle drivers, handheld retractors, forceps, hemostats, and surgical scissors, up to three each of syringes and basins, and two each of beakers and surgical pens, with a maximum of 34 tools per image. We also included variation in tools within categories to recreate the variability seen in real-world surgical settings. Images were captured from various angles to simulate the different views a computer vision system might encounter during a real-world surgical procedure. These included an overtop view (90 degrees from horizontal), 70 degrees above horizontal from front and side views, and 30 degrees above horizontal from the front of the surgical tables. All images were taken on a blue surgical cloth background, and all objects were of surgical grade to ensure the dataset accurately reflected a true surgical environment.
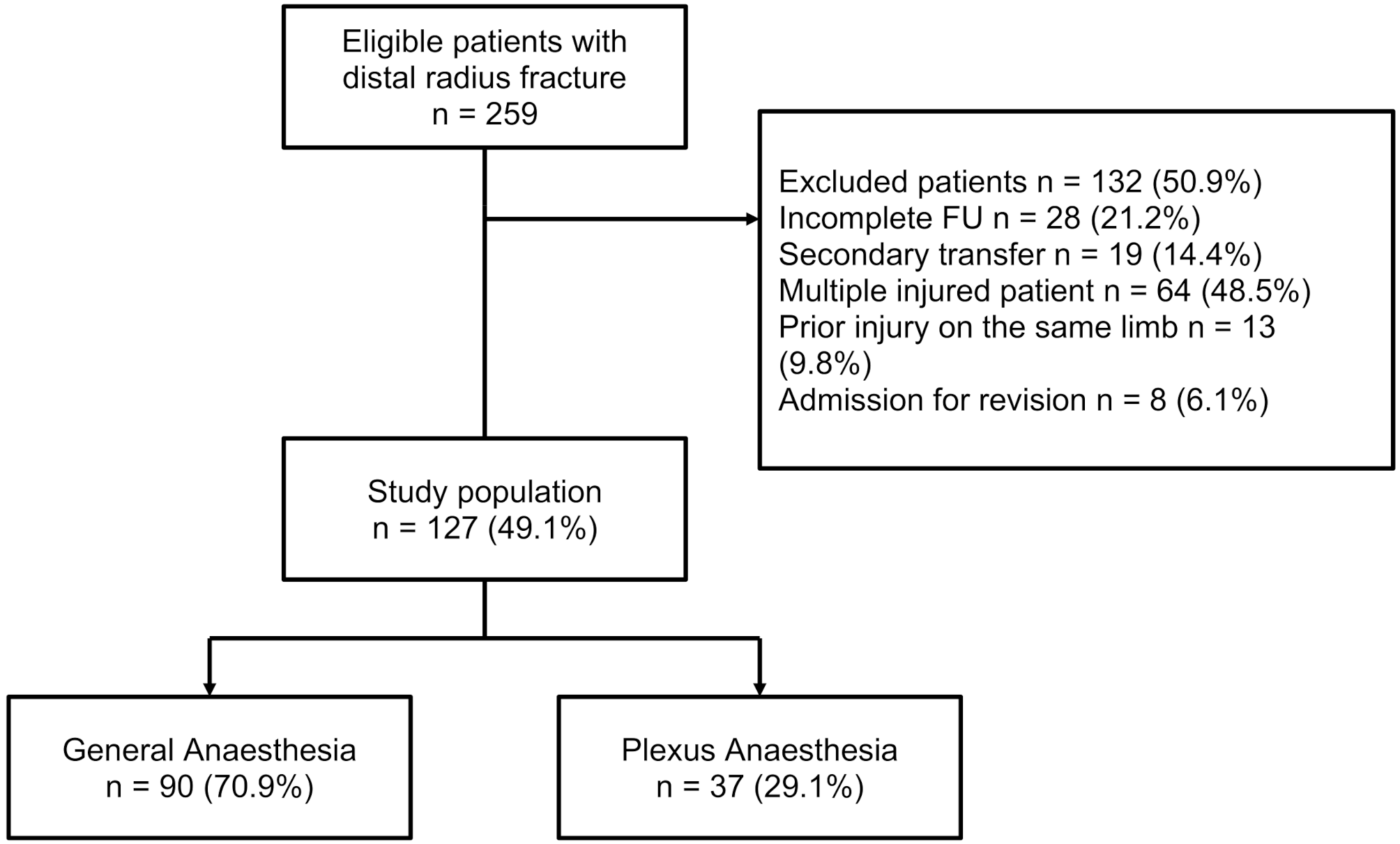
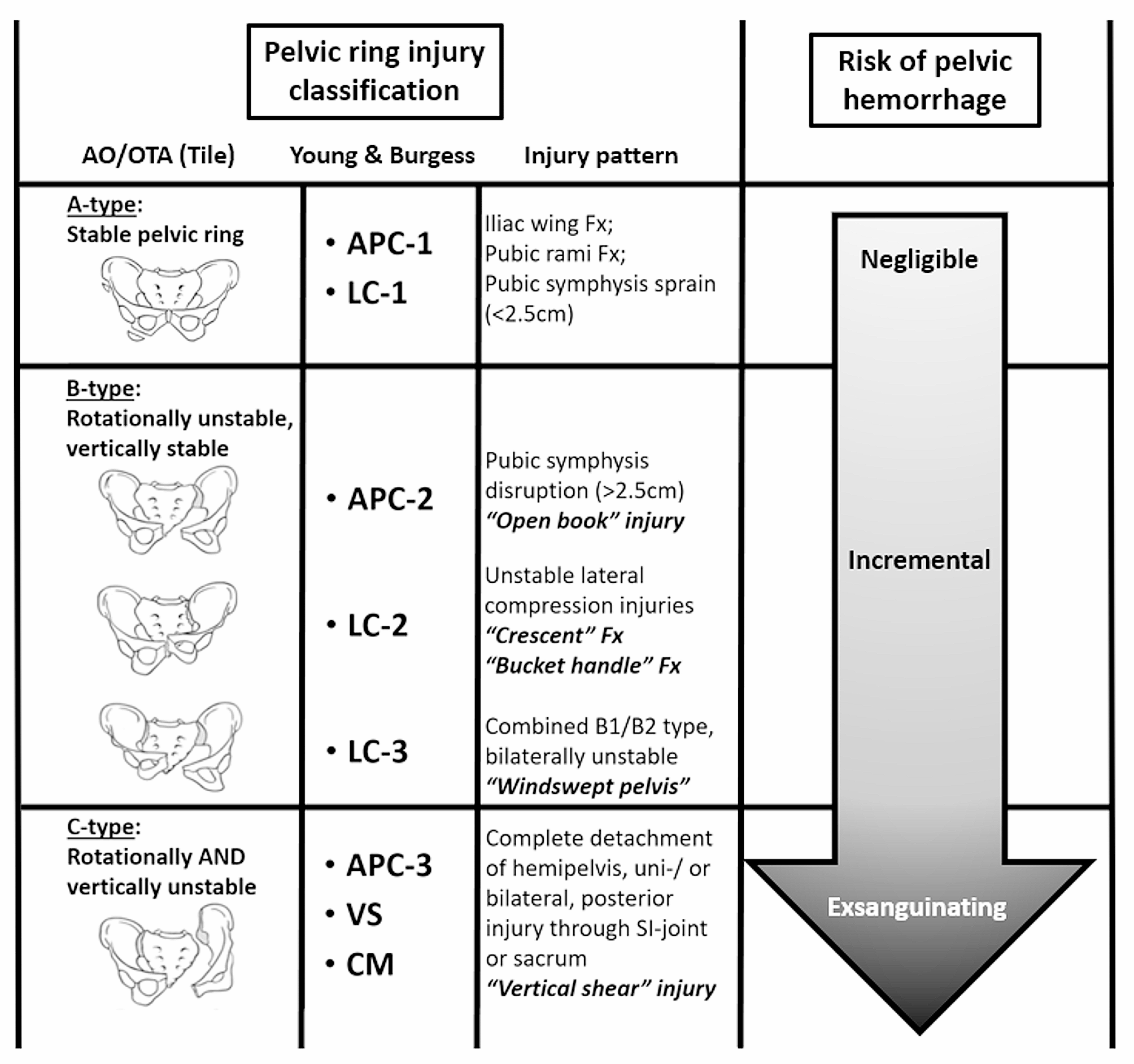
The full dataset comprised 1004 images, and a total of 13,213 surgical tool instances, including: 1234 scalpel, 814 surgical skin pen, 1304 surgical scissor, 1263 forcep, 2030 hemostat, 1,324 needle driver, 1319 retractor, 676 beaker, 1,187 syringe, 1499 surgical gauze, and 1088 basin instances. In order to evaluate model performance in realistic situations, a subset of 218 images were taken in a cluttered overlapping configuration. Figure 1 highlights examples of non-overlapping and overlapping surgical tool setups. Images were labeled with bounding boxes using the open source Computer Vision Annotation tool [20]. The data was split into training, validation, and test datasets at a 60:20:20 ratio.
Fig. 1
Examples of unlabeled images in surgical tool dataset: A – Non-overlapping tools. B – Overlapping tools
Additionally, in order to test the model’s suitability for real-time applications with dynamic instrument exchange, we recorded video footage of various instruments being exchanged in a simulated surgical environment.
Inclusion and exclusion criteriaImages were included if they contained at least one of the 11 predefined surgical tool categories and were of sufficient quality for annotation. Images were excluded if they were poor quality, did not contain any surgical tools, or contained tools not belonging to the predefined categories.
Model Architecture and trainingFor our surgical tool detection model, we utilized the open-source You Only Look Once (YOLO) v9 architecture [21]. YOLOv9 is the latest iteration of the YOLO family of object detection network released in February 2024 [21]. The model employs a Cross Stage Partial Darknet 53 backbone for feature extraction, coupled with a Path Aggregation Network neck for feature aggregation and refinement. The detection head utilizes anchor boxes and a decoupled design to independently handle object scoring, bounding box regression, and class label prediction. We trained the YOLOv9 architecture with 25.5 million parameters on our novel surgical tool dataset. The images were resized to a standard 640 × 640 resolution, and bounding box annotations were normalized to the Common Objects in Context dataset format [22]. Data augmentations such as panning, cropping, brightness adjustment, noise introduction, rotation, horizontal flipping, and cutout were randomly applied to training images to reduce overfitting and improve the model’s robustness. The training was performed on a single NVIDIA V100 graphics processing unit.
Data analysisTo evaluate the model’s performance, we utilized standard object detection metrics including precision, recall, and mean average precision. In the context of our study, precision indicates the percentage of instances where the model correctly identifies a surgical tool as being present on the table amongst all the surgical tool predictions it makes. Conversely, recall signifies the percentage of surgical tools present in the image that the model successfully identifies as being present on the table. Overall precision and recall were determined for all surgical tools collectively, as well as for each individual surgical tool type. Mean average precision was calculated using a single intersection over union threshold of 0.5 and multiple intersection over union thresholds ranging from 0.50 to 0.95 in intervals of 0.05. To assess the model’s speed and suitability for real-time use during surgery, the model’s frame-by-frame processing time was measured while analyzing a video of surgical instruments being moved in and out of the field of view. This test was used to gauge if the model could keep pace with the dynamic nature of a surgical procedure, correctly identifying tools as they are being used in real-time. All data analysis was conducted in Python using the PyTorch and Ultralytics packages [23].
Comments (0)