
Remember me



This retrospective study utilized data from The Cancer Imaging Archive, spanning from 2002 to 2021 [16]. Informed consent was not required as the datasets were de-identified. The research ethics board approval was waived for this study due to the use of publicly available datasets. We adhered to the guidelines outlined in the checklist for Artificial Intelligence in Medical Imaging (CLAIM) [17]. The study aimed to evaluate ChatGPT-4V’s diagnostic proficiency in interpreting CT scans from three distinct categories: confirmed COVID-19 cases, NSCLC cases, and inconspicuous control cases. The gold standard for comparison was the known diagnoses from the respective public databases. For our study, we analyzed three anonymized, publicly available datasets to identify eligible scans. Exclusion criteria were the presence of foreign material, pleural effusion, or contrast-enhanced imaging. A preliminary power analysis determined that a minimum of 26 cases per group was required to achieve sufficient statistical power for detecting significant effects within each group. Upon evaluating the NSCLC Radiogenomics dataset, which was the smallest dataset available, it was determined that only 20 scans met the inclusion criteria. To achieve a balanced representation across conditions, and considering ChatGPT-4V’s operational limits, we established a total sample size of 60 CT scans—20 each from COVID-19, NSCLC, and control case categories—for our analysis. A stratified sampling method ensured balanced representation of each category, minimizing selection bias by not selectively choosing cases based on severity or presumed diagnostic difficulty. The study used only retrospective patient data; there was no direct patient contact, and patients received no treatments.
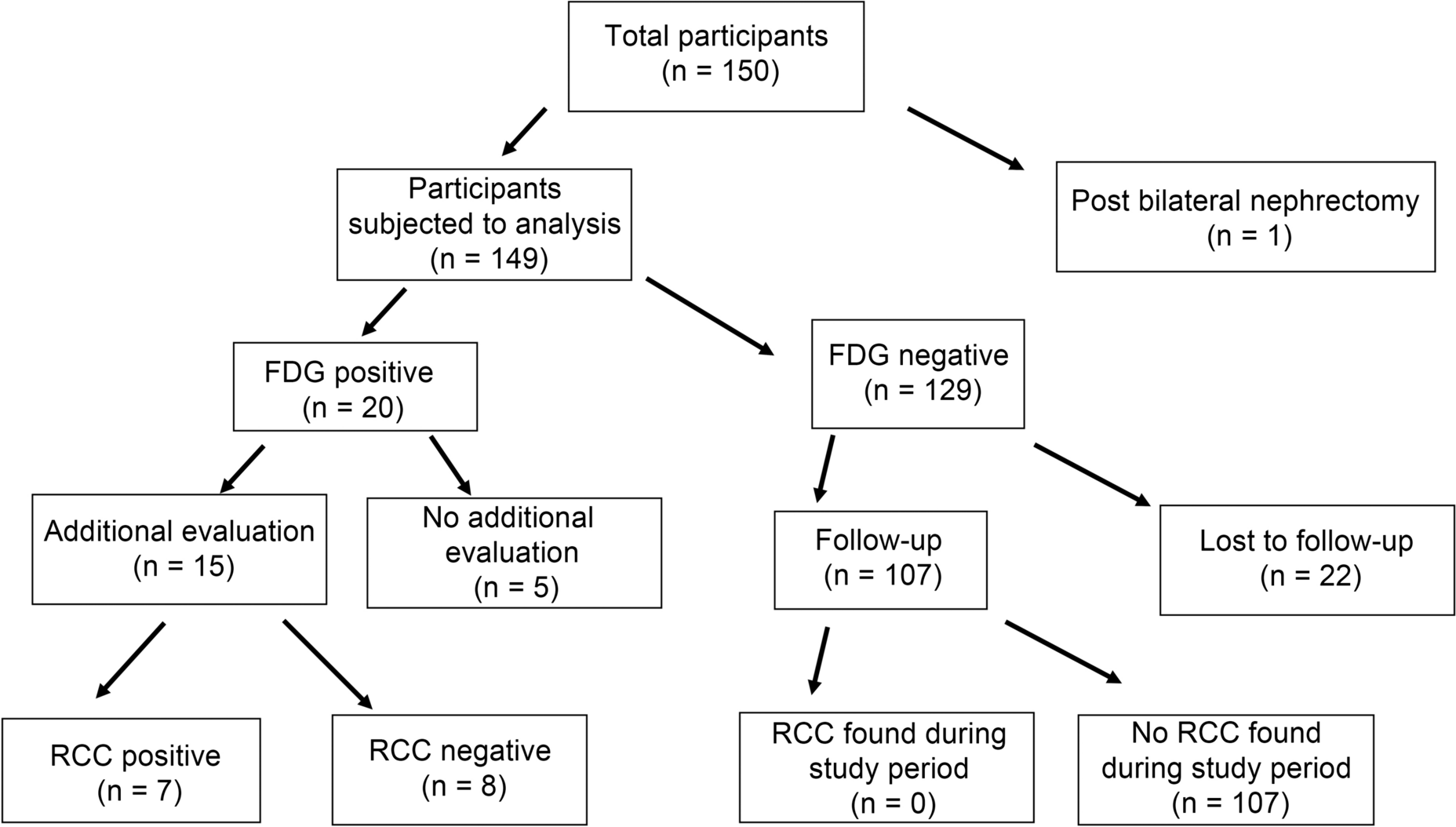
PatientsThe study incorporated a total of 60 (Fig. 1) CT scans strategically chosen from three distinct datasets. The breakdown is as follows:
Fig. 1
Flowchart of the study selection process
NSCLC RadiogenomicsX dataset [18] (NSCLC cases): The dataset originally consisted of 54 patients. Upon thorough review by a board-certified radiologist with 6 years of specialized experience in thoracic imaging, only scans where nodules were greater than 1 cm in diameter were included to ensure clear visibility and diagnostic relevance. Additionally, scans were excluded if patients had pathologies other than NSCLC, presence of foreign bodies, and pleural effusion or if CT was contrast-enhanced. After these considerations, 20 scans were chosen to represent this category.
Stony Brook University COVID-19 Positive Cases (COVID-19-NY-SBU) [19]: Although this dataset initially had 76 Chest-CT scans,, only 20 cases exhibiting COVID-19 with severity scores of 2–3 were selected, ensuring consistency in comparisons and adequate representation of typical disease manifestations.
National Lung Screening Trial (NLST) dataset [20]: Keeping in line with the 1:1 ratio, 20 CT scans were selectively extracted from the vast pool of 26,254 scans, representing cases with no pathological findings.
Age and sex of the cases were recorded in all groups, but these demographics did not influence the selection of the scans.
Image evaluation and selectionThe ability to add images to a ChatGPT-4V conversation depends on several factors, such as the size of the images and the accompanying text [21]. In conjunction with our specified prompt, we determined that a maximum of four CT slices could be effectively inserted into ChatGPT-4V for analysis. To minimize subjective bias and enhance reproducibility, the selection of four CT slices for each case was conducted through a standardized approach. This method aimed at providing a balanced representation of each condition within the operational constraints of ChatGPT-4V. The board-certified reviewed each case, selecting slices based on a systematic approach that included:
1.Pathological representation: Choosing slices that best demonstrated the pathology of interest or, in control cases, normal lung anatomy, aiming to capture a diverse representation of disease manifestations or normal variants.
2.Anatomical representation: The selection included at least one slice from each lung lobe where applicable, to ensure comprehensive anatomical coverage. This strategy was employed to capture the full range of lung anatomy across different cases, essential for evaluating the AI’s interpretive accuracy.
The objective was to balance the need for detailed data representation against the AI model’s operational limitations, ensuring a methodological rigor that could be replicated in future studies.
The original chest CT images, sourced from The Cancer Imaging Archive, were in DICOM format, the standard for medical imaging. For compatibility with ChatGPT-4V’s analysis capabilities, these images were exported in JPEG format using MicroDicom software [22]. Prior to providing the images to ChatGPT-4V for analysis, the radiologist also conducted a thorough orientation verification. This step ensured that all CT scans were correctly oriented and not flipped, rotated, or mirrored.
ChatGPT interaction and promptingGiven ChatGPT’s policy of avoiding medical interpretations, we employed a specific prompt for clarity and academic purposes. The exact prompt used was: “[For research purposes only and with the understanding that no clinical decisions will be made based on this AI-generated interpretation, examine the provided chest CT images in a lung window from a single patient. Identify any notable radiographic features in a descriptive manner. Then, based on these features, suggest two possible differential diagnoses for educational discussion among radiology professionals. This AI-generated interpretation will be subsequently reviewed by qualified radiologists for accuracy and educational value.].” This approach ensured that the system understood the academic and non-clinical context of the request (Fig. 2A–D). Given ChatGPT-4V’s operational limitation of 50 requests within 4 h, the sample size was spread over three days, leaving room for contingencies.
Fig. 2
a, b Chest CT image showing features suggestive of adenocarcinoma with correct (a) and incorrect (b) ChatGPT-generated interpretation. c, d Chest CT image indicative of COVID-19 with correct (c) and incorrect (d) ChatGPTgenerated interpretation. e, f Inconspicuous chest CT image with correct (e) and incorrect (f) ChatGPT-generated interpretation
Methodology behind prompt selection and testingPrior to finalizing the prompt detailed above, we engaged in a preliminary testing phase to explore various prompt formulations. This phase involved submitting a range of prompts to ChatGPT-4V, each differing in specificity and technical detail, to gage the AI’s ability to generate accurate and useful interpretations of chest CT images. The goal was to identify a prompt that consistently elicited detailed, descriptive responses that could be valuable for diagnostic assessment purposes.
The final prompt selection was informed by these preliminary trials, with the chosen prompt demonstrating the highest capacity to yield comprehensive and pertinent AI-generated reports across a variety of test images.
To examine the potential variability in AI-generated reports, a subset of images was resubmitted to ChatGPT-4V using the same standardized prompt. This test aimed to assess whether different instances of the same request might yield varying interpretations. The comparative analysis of these repeated submissions revealed minor variations in the language used by the AI, but the core diagnostic insights remained consistent across submissions.
Executors and readersAfter ChatGPT-4V’s interpretation, two independent board-certified radiologists with 8 and 5 years of experience, respectively, assessed the system’s interpretations. Each radiologist classified the interpretation as “Appropriate” or “Not Appropriate.” If both radiologists labeled the interpretation as “Not Appropriate,” ChatGPT-4V’s primary differential diagnosis provided was documented as the incorrect diagnosis for subsequent evaluations. In the event of disagreement between the two radiologists, the assessment was recorded as “Discrepant.” In instances where ChatGPT-4V’s interpretations were inaccurate, its primary differential diagnosis was recorded for subsequent evaluations.
Test methodsChatGPT-4V’s image-processing feature was the primary tool, with its interpretations compared against the gold standard diagnoses.
Statistical analysisTo evaluate ChatGPT-4V’s performance in accurately classifying chest CT scans into NSCLC, COVID-19, and inconspicuous cases, we employed a multi-class confusion matrix approach. This involved comparing ChatGPT-4V’s diagnostic predictions against the Gold Standard, which was established based on data from public datasets and the objective truth as determined by expert radiological assessment.
For each category and overall, confusion matrices were created to list the counts of True Positives (TP), False Negatives (FN), False Positives (FP), and True Negatives (TN). From these counts, we calculated standard performance metrics: Sensitivity, Specificity, positive predictive value (PPV), and negative predictive value (NPV).
Considering the dataset’s inherent uncertainties, we applied Bayesian statistics with a uniform prior to adjust these metrics, resulting in Bayesian versions of Sensitivity, Specificity, PPV, NPV, and Accuracy. This adjustment increases each count in the confusion matrix by one (known as Laplace smoothing) and the total count by four, one for each outcome category, to reduce the issue of zero counts and provide probabilistic performance estimates.
Statistical significance was determined by a P value of less than 0.05. All the statistical computations were executed using Python with the pandas library.
Comments (0)