
Remember me


We assume that the attractors of the frontal network have been associated one-to-one with those of the posterior network, via Hebbian plasticity, during a learning phase, which we do not model. When there is no external stimulus, e.g. when modelling creative thinking and future imaging, the network can sustain latching dynamics, i.e. it can hop from state to state, as in Fig. 1, provided its activity is appropriately regulated by suitable thresholds, as we have reported elsewhere (Treves 2005). Such spontaneous dynamics of the entire network might be led to a different extent by its frontal and posterior halves, depending on their characteristic parameters.
In order to quantify the relative influence of the two sub-networks on the latching sequences produced by the hybrid Potts model, we look at whether the actual occurrence of each possible transition depends on the correlations, computed separately in the frontal and posterior parts, between the two patterns before and after the transition.
For the randomly correlated patterns used here, the correlations are relatively minor, but they can be anyway quantified by two quantities, \(C_\) and \(C_\) (Russo and Treves 2012; Boboeva et al. 2018), that is, the fraction of active units in one pattern that are co-active in the other and in the same, \(C_\), or in a different state, \(C_\). In terms of these quantities, two memory patterns are highly correlated if \(C_\) is larger than average and \(C_\) is smaller than average, and we can take the difference \(C_-C_\) as a simple compact indicator (actually, a proxy) of the “distance” between the two patterns.
How strongly are transitions in a latching sequence driven by pattern correlations in each subnetwork? To measure this, we take the weighted average of \(C_\) and \(C_\) with the weights given by latching sequences; that is, we compute
$$\begin \langle C_ \rangle _T \equiv \sum _t_C_^, \end$$
(3)
(and analogously for \(\langle C_ \rangle _T\)) where the sum \(\sum _\) runs over all possible pairs of memories and \(t_\) is the normalized frequency of latching transitions for the pair \(\mu\), \(\nu\): \(\sum _t_=1\). This average is compared with the “baseline” average, e.g.,
$$\begin \langle C_ \rangle _B \equiv \frac\sum _C_^, \end$$
(4)
independent of the transitions, where p is the number of stored memories in the network. The comparison between the two averages, \(\langle C_\rangle _T\) and \(\langle C_\rangle _B\), is one index of how strongly latching sequences are related to correlations between patterns in one of the two sub-networks.
Second, based on the hypothesis that the frequency of transitions tends to decrease exponentially with the distance between the two patterns, as defined above, we look for the linear regression between the logarithm of the normalized transition frequency, \(\log (t)\), and the proxy of the distance, \(C_-C_\).
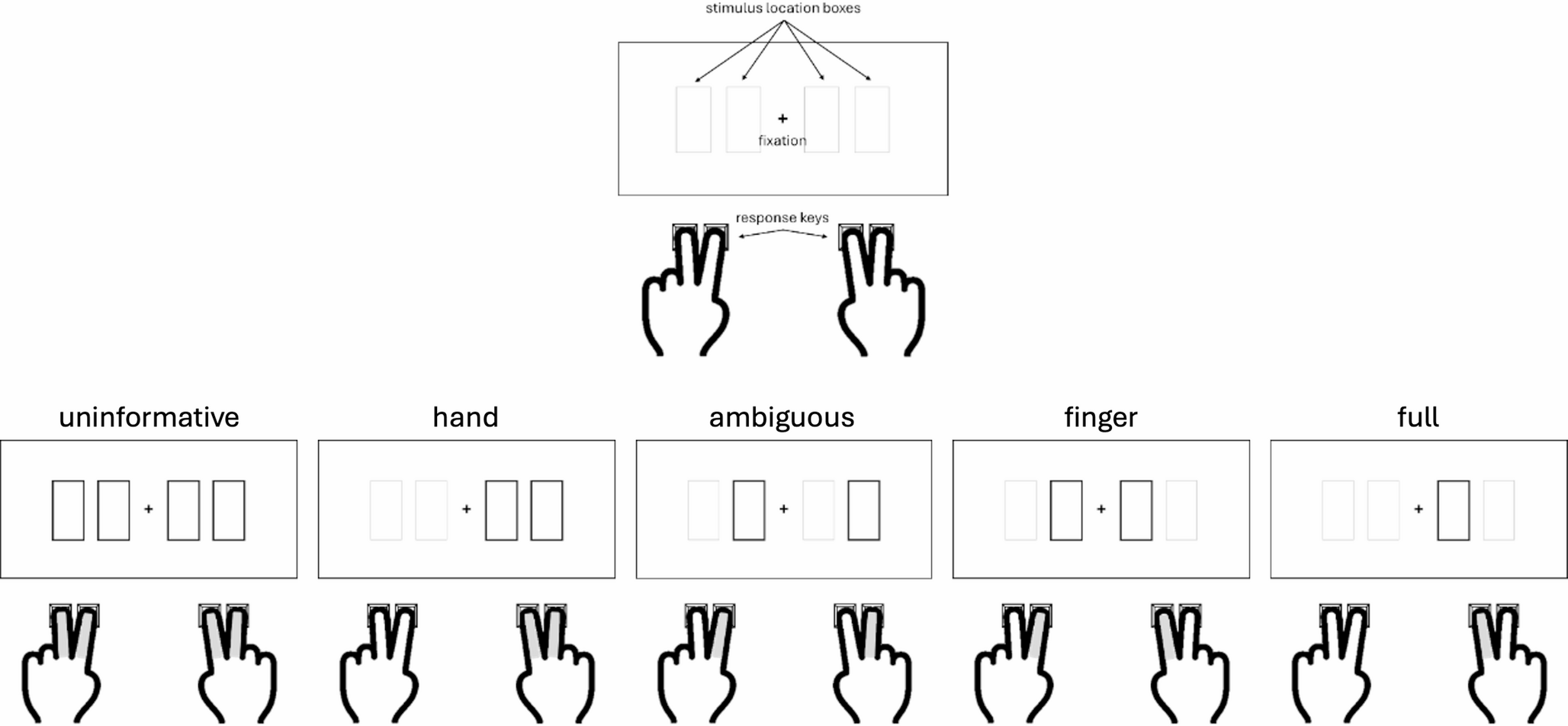
We first consider a case when all the macroscopic parameters are equal between the two sub-networks, while the connection parameter is set as \(\lambda =0.5\). In this case, the intra-connections (within each sub-network) are 3 times, on average, as strong as the inter-connections (between the two sub-networks), but the two halves are fully equivalent, or Not Differentiated (ND). With the appropriate parameters, in particular the feedback w, we find that the network as a whole shows robust latching and that latching sequences in each sub-network are well synchronized with each other: the two sub-networks essentially latch as one. Comparing latching dynamics in two sub-networks, we find that latching is largely driven by correlations between patterns, in either half or in both, as found previously (Russo and Treves 2012). This can be seen, leftmost bars of Fig. 2a and b, by the higher value of \(\langle C_\rangle _T\) relative to \(\langle C_\rangle _B\), and vice versa for \(C_\), in the ND case. Correlations in the two sub-networks appear to contribute equally to determine latching sequences, as expected. This is confirmed by the similar negative slopes in the two scatterplots of Fig. 2c.
Fig. 2
A latching frontal network leads a non-latching posterior network. Red indicates the frontal and blue the posterior network in this and other figures. a and b The transition-weighted averages of \(C_\) and \(C_\) are compared to their baseline values for three cases: no difference between the two networks (ND, leftmost bars), a difference in S (\(\Delta S\), middle bars) and a difference in w (\(\Delta w\), rightmost bars). The gray horizontal line and shaded area indicate the baseline average and its standard deviation. c–e Scatterplots of (log) transition frequencies between individual patterns pairs versus their “distance”, for the three conditions. The darkness of color indicates the number of pairs at each combination of abscissa and ordinate. For the ND condition, parameters are set as \(w_p=w_f=1.1\), \(S_p=S_f=7\). For the other conditions, the parameters of the frontal network are kept the same as in the ND condition, while the parameters of the posterior sub-network are set as \(S_p=3\) and \(w_p=0.6\), respectively, in (d) and (e). Note the negative values on the x-axis, particularly in panel (d) upper, due to using just a proxy of a proper distance measure, a proxy which reaches in the negative range when \(S=3\)
Different S. We now examine a case in which the two networks share the same values of all but one parameter: the number of Potts states, S. When the posterior network has fewer states (\(S=3\) instead of the reference value, 7), the baselines for both \(C_\) and \(C_\) are shifted, above and below, respectively, but their transition-weighted values are similarly positioned, above and below the respective baselines, as in the frontal network. Also in terms of the second indicator, the scatterplot of Fig. 2d shows rather similar slopes, with only a modest quantitative “advantage” for the frontal network (in red), which can be said to lead the latching sequence somewhat more than the posterior one. One should note that, with these parameters, both sub-networks would latch if isolated.
Different w. In contrast to the two cases above, ND and \(\Delta S\), we see a major difference between the two sub-networks if it is the w parameter which is lower for the posterior network (the rightmost bars of Figs. 2a, b). In this case, it is obviously the correlation structure of the frontal patterns, not of the posterior ones, that dominates in determining latching sequences. This is also evident from the very different slopes, k, in the scatterplot of Fig. 2e. With the lower value \(w=0.6\) chosen for the posterior sub-network, this time it would not latch, if isolated. Note that to preserve its latching, and for it to be a clear single sequence, we would have to set w at almost the same value as for the frontal sub-network, unlike the case with the S parameter.
And/or different \(\tau _2\). We now allow the adaptation timescale, \(\tau _2\), to differ between the two sub-networks. We first note that latching sequences between the sub-networks are remarkably well synchronized despite their different adaptation timescales (Fig. 1c). If isolated, the two sub-networks would each latch at a pace set by its own \(\tau _2\). Their synchronization thus shows that, even with this relativity weaker connectivity coupling (inter-connections 1/3 of the average strength of the intra-connections) the two halves are willing to compromise, and latch at some intermediate pace, close to the one they sustained when \(\tau _2\) was not differentiated.
Furthermore, latching sequences are affected predominantly by frontal correlations rather than posterior ones. In Fig. 3, we show two cases: the two sub-networks have two different adaptation timescales; and in the second case also different w. We see a moderate effect if \(\tau _2\) is the only parameter that differs between the two. Note that in this case the posterior sub-network, if isolated, would latch.
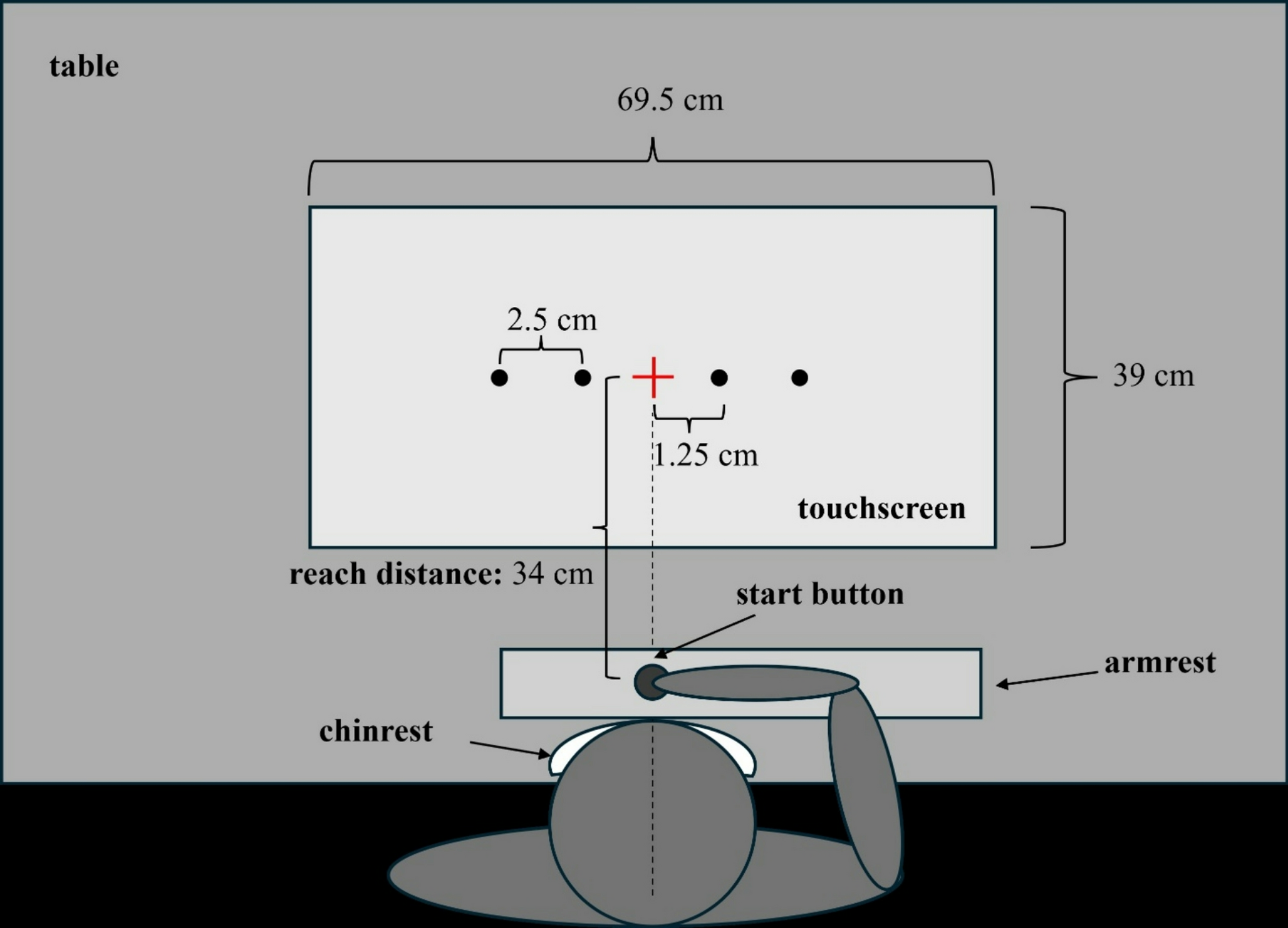
Fig. 3
The frontal sub-network is even more dominant with slower adaptation. Color code and meaning are the same as in Fig. 2. a and b Transition-weighted averages of \(C_\) and \(C_\) versus their baselines are shown for two conditions: only \(\tau _2\) is different and both w and \(\tau _2\) are different. In both conditions, \(\tau _2\) is 100 for the posterior network and 400 for the frontal network. In the \(\Delta w\) condition, w is 0.6 for the posterior network and 1.1 for the frontal network. c and d Log-transformed transition frequencies between individual patterns pairs versus their distance
The effect is most pronounced if w is also lowered to \(w=0.6\) for the posterior sub-network, as is evident from the weak positive slope k it shows, see Fig. 3d. In this case it would not latch if isolated.
We have also inverted the \(\tau _2\) difference, making the posterior sub-network, still with a lower w, slower in terms of firing rate adaptation. In this case (not shown) latching is virtually abolished, showing that the parameter manipulations do not simply add up linearly.
Lesioning the networkTo model lesions in either sub-network, we define a procedure that still allows us to compare quantities based on the same number of inputs per unit, etc. The procedure acts only on the relative weights of the connections (through \(\lambda\)), which are modulated while keeping their average for each receiving unit always to 1/2. Other parameters of the network are set in such a way that the frontal sub-network leads the latching sequences and that lesions do not push the network into a no-latching phase: the self-reinforcement parameter is set as \(w=0.7\) for the posterior sub-network and \(w=1.2\) for the frontal one, while S and \(\tau _2\) are set as specified in Table 1 and thus take the same value for both sub-networks. For “healthy” networks, we use \(\lambda =0.5\) in Eq. (2), meaning the intra-connections (within the frontal and within the posterior half) are 3 times, on average, as strong as the inter-connections (between frontal and posterior halves). For lesioned networks, we use smaller values of \(\lambda\) than 0.5 for their input connections: the smaller the value is, the stronger the lesion is. So, for example, a frontal lesion with \(\lambda =0.2\) implies that its recurrent weights are weighted by a factor 0.6 (instead of 0.75) and the weights from the posterior sub-network by a factor 0.4 (rather than 0.25), i.e. the internal weights are only 1.5 times those of the interconnections. The posterior sub-network in this case has the same weights as the control case.
We then quantify the effect of the lesions with the slopes in the scatterplots as before, but also with an entropy measure. The entropy at position z in a latching sequence measures the variability of transitions encountered at that position, across all sequences with the same starting point. It is computed as
$$\begin S(z) = \big \langle -\sum _P_\gamma ^(z)\log _2P_\gamma ^(z)\big \rangle _\gamma , \end$$
(5)
where \(P_\gamma ^(z)\) is the joint probability of having two patterns \(\mu\) and \(\nu\) at two consecutive positions z and \(z+1\) relative to the cued pattern \(\gamma\) in a latching sequence, and \(\langle \cdot \rangle _\gamma\) means that we average the entropy across all the p patterns that are used as a cue. Note that if all transitions were incurred equally, asymptotically for large z, the entropy would reach its maximum value \(S_=\log _2 [p(p-1)]\) (with p patterns stored in memory and available for latching). Therefore \(\exp \]\ln (2)\}\) is an effective measure of the fraction of all possible transitions that the network has explored at position z, on average.
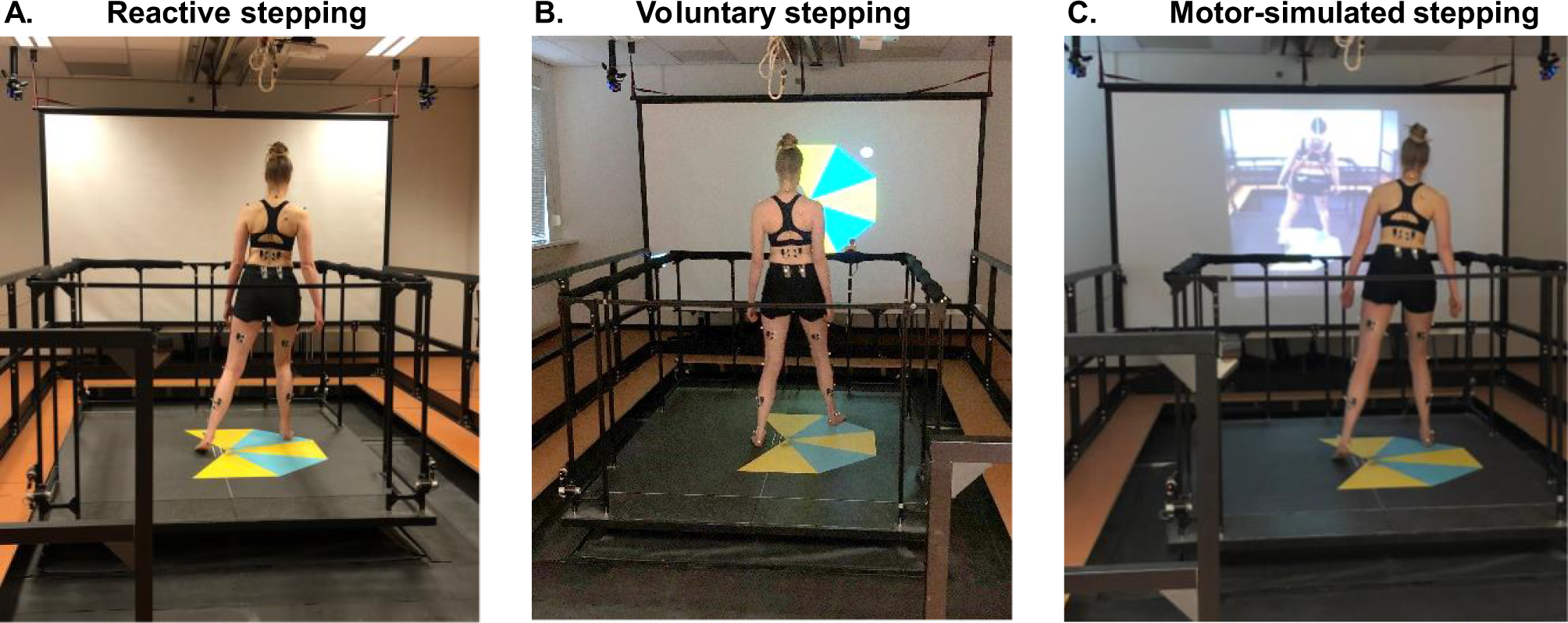
In terms of the slopes in the scatterplots, we see that posterior lesions do not have a major effect, while frontal lesions reduce the relation between the probability of individual transitions and the correlation between the two patterns, particularly in the frontal sub-network where it was strong in the “healthy” case (Fig. 4).
Fig. 4
Correlations between transition frequency and pattern distance are shown for a network with frontal lesions (a), for a healthy network (b) and for a network with posterior lesions (c). Lesions are modelled by setting \(\lambda =0.2\) (see main text). The self-reinforcement parameter is set as \(w=1.2\) for the frontal sub-network and \(w=0.7\) for the posterior one
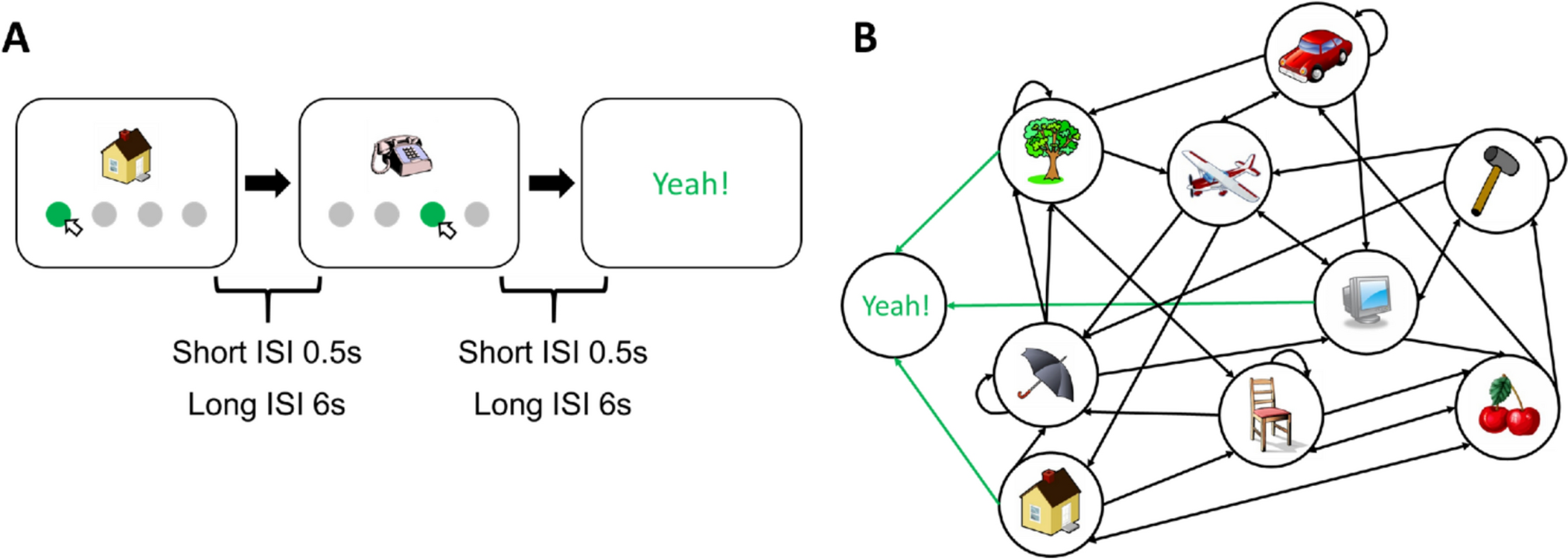
In terms of entropy, we see that lesions in the posterior sub-network do not affect the entropy curve, relative to that for the healthy network (Fig. 5). Lesions in the frontal sub-network, however, tend to restrict the sequences to a limited set of transitions, leading to a marked reduction in the fraction of possibilities explored by the lesioned network.
Fig. 5
a The entropy S(z) and its standard error of the mean are shown for healthy (black), frontal-lesioned (blue) and posterior-lesioned (red) networks. Lesions are implemented by setting \(\lambda =0.2\) for solid curves, whereas the dashed blue curve is for a milder lesion in the frontal network (\(\lambda =0.3\)). The black horizontal line indicates the asymptotic entropy value for a completely random sequence generated from a set of \(p=50\) patterns. The self-reinforcement parameter is set as \(w=1.2\) for the frontal network and \(w=0.7\) for the posterior network. b A schematic view of the diversity of transitions expressed by latching sequences. Circles are centered around an arbitrary position, while their areas extend over a fraction \(2^}\) of the area of the square (which would correspond to an even exploration of all possible transitions, asymptotically). The large orange circle is obtained by setting \(\lambda =0.7\), thus modelling a sort of cognitive frontal enhancement, perhaps obtained with psychoactive substances
Simulated frontal lesions, therefore, produce in our model two effects that, while not opposite, are not fully congruent either. The first, manifested in the reduced slope of Fig. 4a, is suggestive of a loss of coherence in individual transitions between brain states; the second, seen in the limited entropy of Fig. 5, indicates a restriction in the space spanned by the trajectories of spontaneous thought. To reconcile the two outcomes, we have to conclude that while less dependent on the similarity between the two patterns, or states, individual transitions are not really random, and some become in the lesioned network much more frequent than others, gradually veering from creative towards obsessive (or perseverative) thought.
Comments (0)