
Remember me
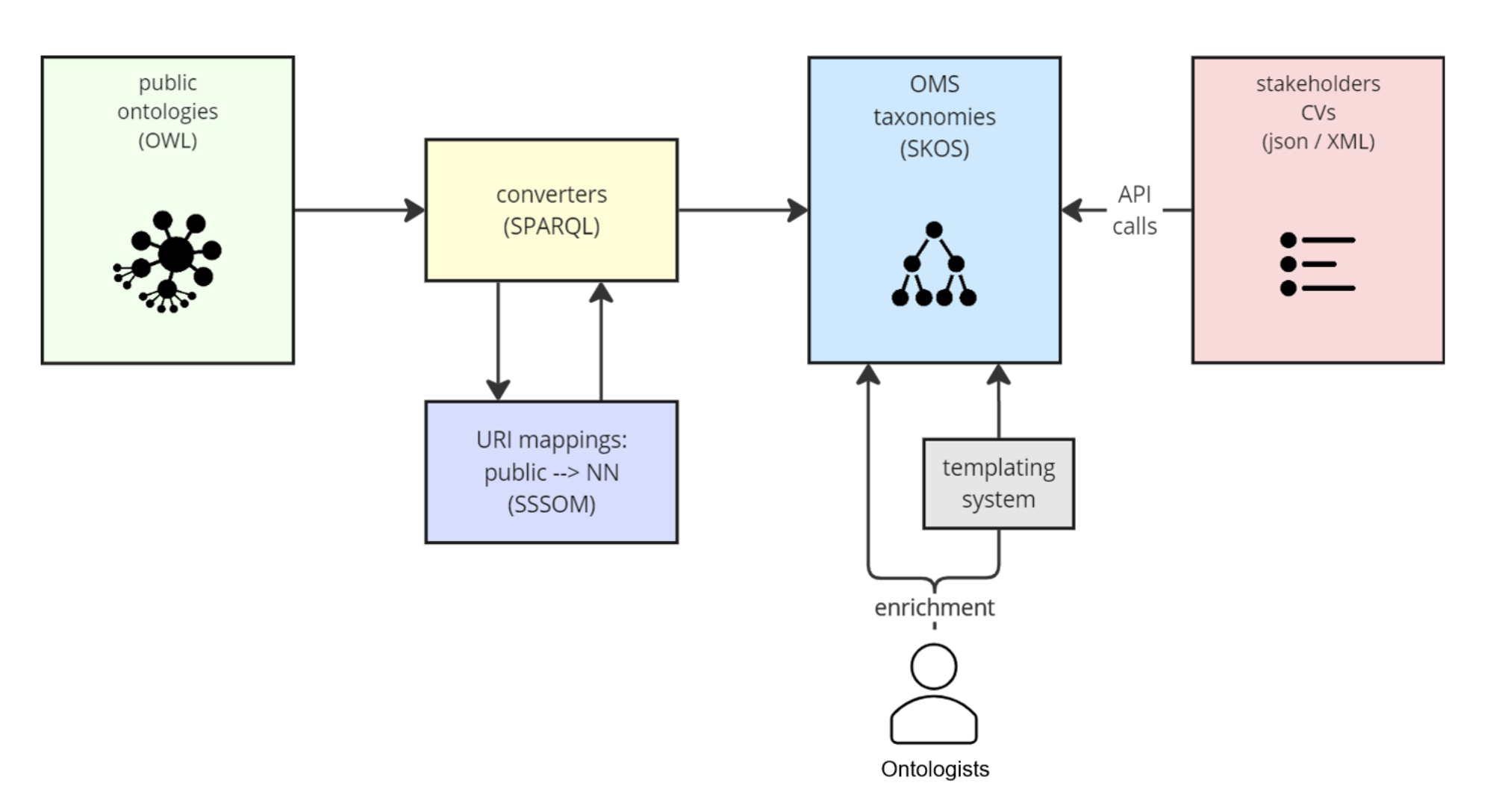
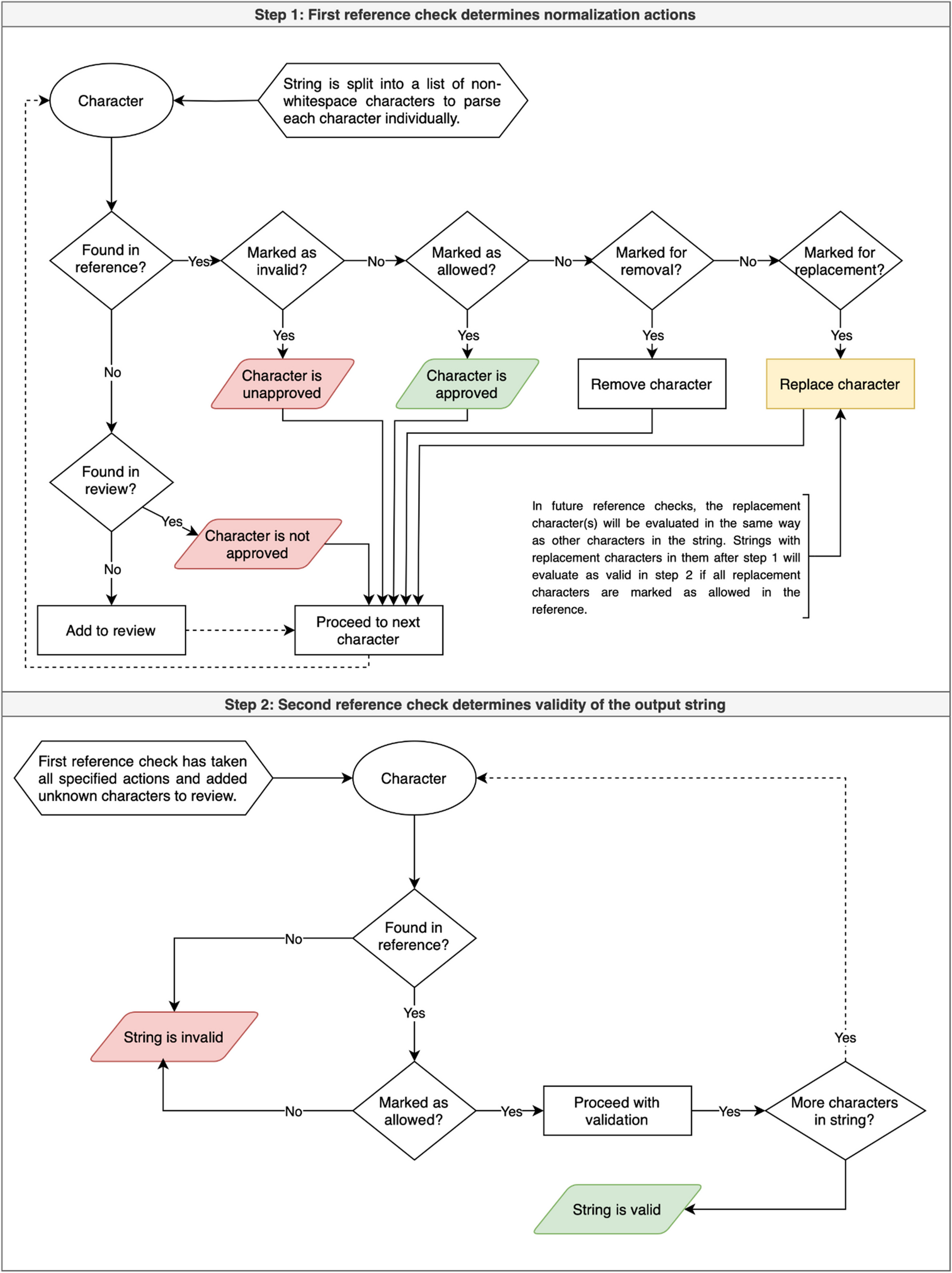
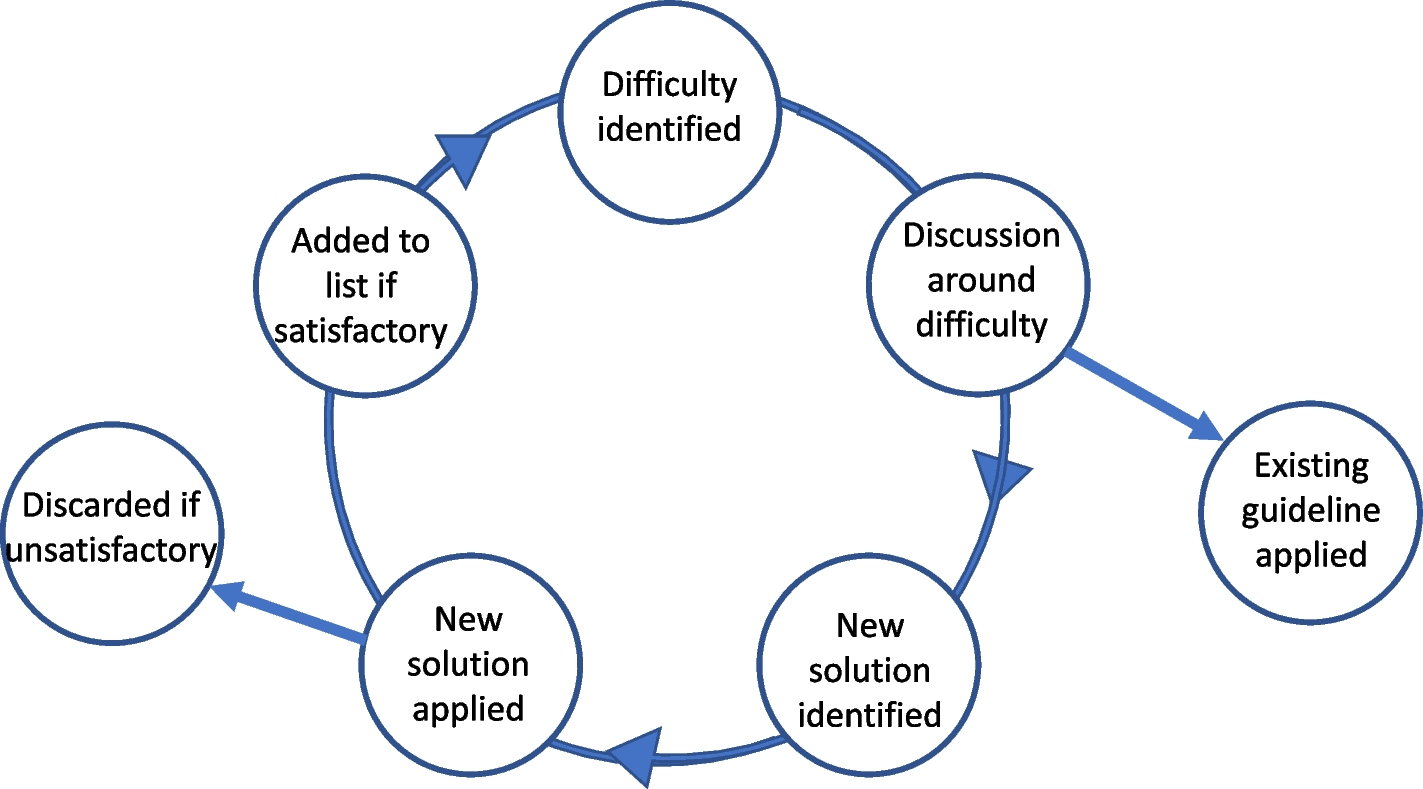

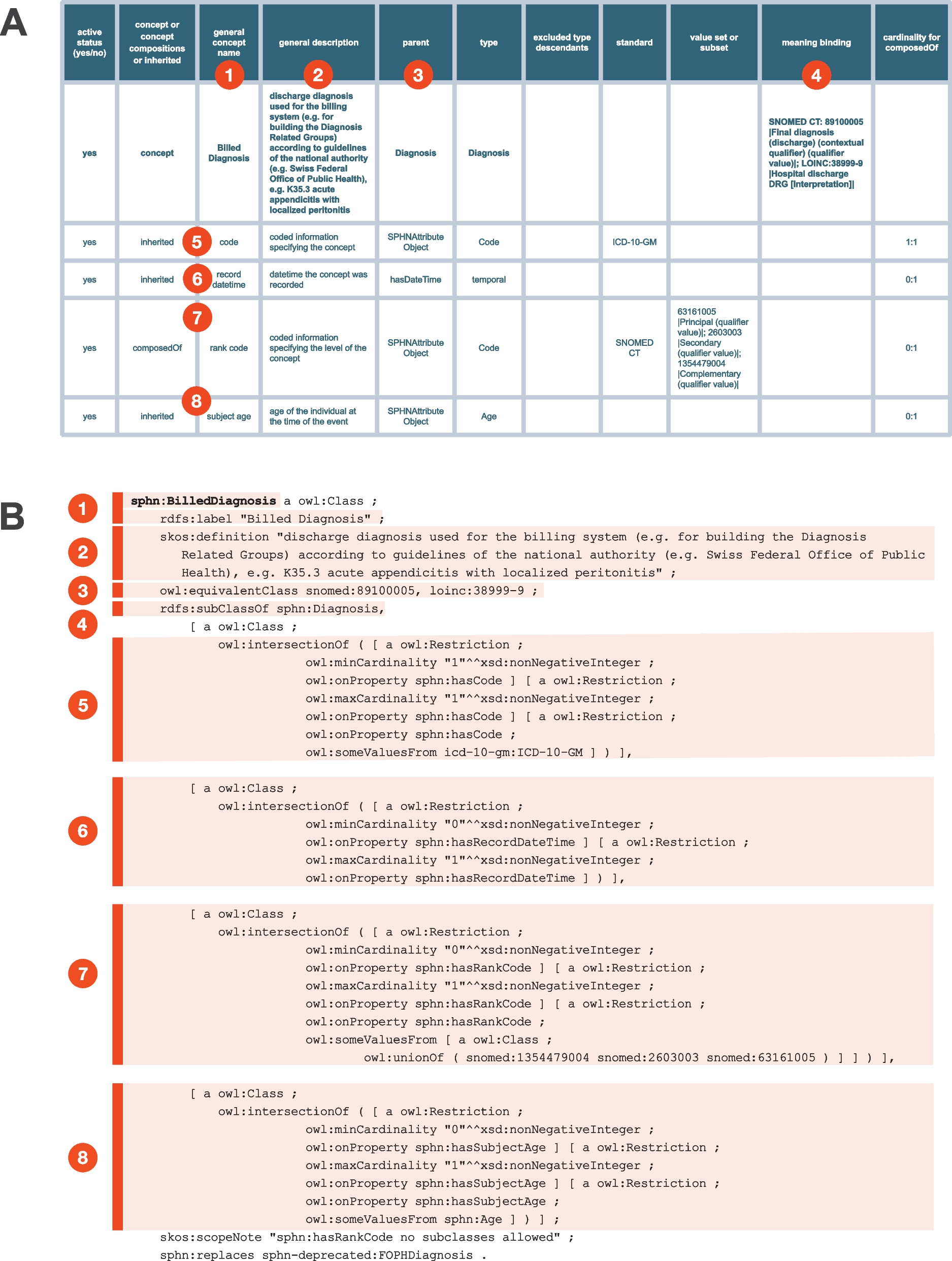




Subsection “Formal definitions” presents the formal definitions useful to this investigation. Subsection “Methodology” describes the conducted methodology by defining the studies and open research questions investigated in this work.
Formal definitionsOntology. An ontology \(\mathcal \) specifies a conceptualization of a domain in terms of concepts, attributes and relationships [21]. Formally, an ontology \(\mathcal = (\mathcal _\mathcal , \mathcal _\mathcal , \mathcal _\mathcal )\) consists of a set of concepts \(\mathcal _\mathcal \) interrelated by directed relationships \(\mathcal _\mathcal \). Each concept \(c \in \mathcal _}\) has a unique identifier and is associated with a set of attributes \(\mathcal _\mathcal (c)=\\). Consider attributes as string terms characterizing the meaning of concepts. Each relationship \(r(c_1, c_2) \in \mathcal _\mathcal \) is typically a triple \((c_1, c_2, t)\) where t is the relationship (e.g., is_a, part_of, adviced_by, etc.) interrelating \(c_1\) and \(c_2\).
Context of a concept. We define the context of a particular concept \(c_i \in \mathcal _\mathcal \) as a set of super concepts, sub concepts and sibling concepts of \(c_i\), as following:
$$\begin CT(c_i, \lambda ) = sup(c_i, \lambda ) \cup sub(c_i, \lambda ) \cup sib(c_i, \lambda ) \end$$
(1)
where
$$\begin sup(c_i, \lambda )= & \_\mathcal , r(c_i, c_j)=``\sqsubset " \wedge length(c_i, c_j) \le \lambda \wedge c_i \ne c_j \} \nonumber \\ sub(c_i, \lambda )= & \_\mathcal , r(c_j, c_i)=``\sqsubset " \wedge length(c_i, c_j) \le \lambda \wedge c_i \ne c_j \} \nonumber \\ sib(c_i, \lambda )= & \_\mathcal , ( (sup (c_j) \cap sup (c_i)) \vee (sub (c_j) \cap sub (c_i)) ) \nonumber \\ & \wedge length(c_i, c_j) \le \lambda \wedge c_i \ne c_j \} \end$$
(2)
where \(\lambda\) is the level of the context. It represents the maximum value for the length between two concepts (in terms of their shortest relationship distance in the hierarchy of concepts) and the “\(\sqsubset\)” symbol indicates that “\(c_i\) is a sub concept of \(c_j\)”. This definition of \(CT(c_i, \lambda )\) is specially designed as the relevant concepts to be taken into account in the settings of this investigation on mapping refinement.
Similarity between concepts. Given two particular concepts \(c_i\) and \(c_j\), the similarity between them is defined as the maximum similarity between each couple of attributes from \(c_i\) and \(c_j\). Formally:
$$\begin sim(c_i, c_j) = \arg \max ~sim(a_, a_) \end$$
(3)
where \(sim(a_, a_)\) is the similarity between two attributes \(a_\) and \(a_\) denoting concepts \(c_i\) and \(c_j\), respectively.
Mapping. Given two concepts \(c_s\) and \(c_t\) from two different ontologies, a mapping \(m_\) can be defined as:
$$\begin m_ = (c_s, c_t, semType, conf) \end$$
(4)
where semType is the semantic relation connecting \(c_s\) and \(c_t\). In this article, we differentiate relation from relationship, where the former belongs to a mapping and the latter to an ontology. The following types of semantic relation are considered: unmappable [\(\bot\)], equivalent [\(\equiv\)], narrow-to-broad [\(\le\)], broad-to-narrow [\(\ge\)] and overlapped [\(\approx\)]. For example, concepts can be equivalent (e.g., head\(\equiv\)head), one concept can be less or more general than the other (e.g., diabetes type I\(\le\)diabetes) or concepts can be somehow semantically related (\(\approx\)). The conf is the similarity between \(c_s\) and \(c_t\) indicating the confidence of their relation [22]. We define \(\mathcal _\) as a set of mappings \(m_\) between ontologies \(\mathcal _S\) and \(\mathcal _T\).
Versions of ontology and mappings. At a given time \(j \in N\), we assume the version of an ontology release \(\mathcal _S^j\). For instance, ontology \(\mathcal _S^0\) is version 0 whereas \(\mathcal _S^1\) is version 1 of the same ontology. In another sense, \(\mathcal _S^\) is the new version of the \(\mathcal _S^\). Similarly, we consider \(\mathcal ^_\) a release of a set of mappings between two ontologies, such that, \(\mathcal ^_\) is the new version of the mappings produced.
Ontology change operations (OCO). An ontology change operation (OCO) is defined to represent a change in an attribute, in a set of one or more concepts, or in a relationship between concepts. OCOs are classified into two main categories: atomic and complex changes. Each OCO in the former cannot be divided into smaller operations while each one of the latter is composed of more than one atomic operation. In this work, we pay further attention to the operations of concept addition.
MethodologyThis work conducts two studies investigating ontology refinement phenomena under different perspectives. Ontologies used in both studies have multiple versions available. This is a sine qua non condition to apply the techniques described in this work.
Analysing new ontology version to refine mappings. (cf. Section “Analysing new ontology version to refine mappings”). Consider two versions of the same source ontology \(\mathcal _S^j\) at time j and \(\mathcal _S^\) at time \(\), a target ontology \(\mathcal _T^j\), and an initial set of mappings \(\mathcal ^j_\) between \(\mathcal _S^j\) and \(\mathcal _T^j\) at time j. Suppose that the frequency of new releases of \(\mathcal _S\) and \(\mathcal _T\) is different and at time \(j+1\) only \(\mathcal _S\) evolves. It is necessary to refine \(\mathcal ^j_\) to guarantee the quality and completeness of \(\mathcal ^_\) according to the new concepts of the ontology version. We aim to obtain \(M^_\) based on the original mapping set \(M^_\) between the ontologies \(\mathcal _S^j\) and \(\mathcal _T^j\). At time \(j+1\), newly added concepts appear in \(\mathcal _S^\) and we attempt to refine the original mapping set \(M^_\) to provide a set of valid mappings \(M^_\).
We study how \(\mathcal ^j_\) can be refined (e.g., new mappings derived) based on ontology changes related to addition of knowledge. To this end, our work addresses the following research questions:
How can existing mappings be exploited for mapping refinement based on added new concepts?
Is it possible to reach mapping refinement for the alignment of new concepts without applying a matching operation in the whole target ontology?
What is the impact of using the context of concepts \(CT(c_i, \lambda )\), including evolution information, in both source and target ontologies on the mapping refinement effectiveness?
Analysing old ontology version to refine mappings. (cf. Section “Analysing old ontology version to refine mappings”) Consider two versions of the same source ontology \(\mathcal _S^\) at time \(j-1\) and \(\mathcal _S^j\) at time j. Note that \(\mathcal _S^j\) is the current ontology under use, and \(\mathcal _S^\) refers to an old version of the same ontology. In this study, it is useful to understand how a given concept in \(\mathcal _S^j\) has evolved from \(\mathcal _S^\). In our problem modeling, there is a target ontology \(\mathcal _T^j\), and a set of mappings \(\mathcal ^j_\) between \(\mathcal _S^j\), and \(\mathcal _T^j\) at time j. We suppose that the frequency of new releases of \(\mathcal _S\) and \(\mathcal _T\) is different, and at time j, only \(_S\) has evolved. We assume that concepts added by the evolution will likely provide useful information for mapping refinement of \(\mathcal ^j_\). We aim to analyze previous concept information (in the old ontology version – at time \(j-1\)) to enrich semantic relations in mappings and obtain the refined mapping set \(\mathcal _^j\) at time j. All mappings in \(\mathcal ^j_\) have initially the type of semantic relation equivalent [\(\equiv\)] or overlapped [\(\approx\)], and we assume them as a mapping candidate set.
In this problem, given a mapping \(m_ \in \mathcal ^j_\) associated with a concept \(c_1\) affected by changes in the ontology, the challenging issue is to determine an exact and suited action of refinement to apply to \(m_\). To address this challenge, we define and formalize a set of mapping refinement actions (cf. Section “Analysing old ontology version to refine mappings”). The mapping refinement actions are part of refinement procedures, playing a key role in improving the quality of mappings. The objective is to enrich the mapping set by considering different semantic relations between concepts. For instance, equivalence relations are refined to is-a or part-of.
We aim to obtain \(\mathcal '^_\), a refined mapping set based on the input original mapping set \(\mathcal ^_\) (already produced and given as input to our technique). We refine mappings in \(\mathcal ^_\) based on new concepts added to \(\mathcal _S^j\) when compared to \(\mathcal _S^\). In particular, we address the following research questions:
How to apply mapping refinement actions for deriving mappings based on changes concerning the addition of concepts?
How to modify the type of semantic relation in mapping observing past release versions of the ontology?
How to explore the context of concepts \(CT(c_i, \lambda )\) (neighborhood) in mapping refinement attempting to benefit from a local re-matching in the procedure?
Analysing new ontology version to refine mappingsWe aim to propose adequate correspondences for each newly added concept at time \(j+1\). In the first step, our approach identifies all newly added concepts using the Conto-Diff tool [9]. This tool allows the identification of atomic and complex ontology changes. Next, we extract the contextual information, i.e., super, sub, and sibling concepts of those newly added concepts (cf. Formula 1). It is important to distinguish between contextual information and linguistic context. While contextual information represents the neighborhood of the concept, linguistic context refers to the surrounding words and phrases that provide clues to the meaning of a concept. In this method, we used the first definition. We then examine the existing mappings between the source concept in the context of the newly added concept and the corresponding target concepts. The idea behind the context-oriented technique is that the candidate mapping is established between a newly added concept and a target concept of an existing mapping at time t.
The proposed method is based on three main parameters: source level, target level, and threshold. The source level defines the maximum distance between the newly added concept and the concept to be explored in the source ontology. The target level defines the maximum distance between the concept with mapping in the previous version and the candidate concept in the target ontology (cf. Formula 1). Threshold defines the minimum similarity value between two concepts to create a new mapping.
Figure 1 (a) illustrates a situation where two ontologies are presenting an alignment in time j. Figure 1 (b) illustrates a situation where source ontology evolves and some concepts are added to the ontology source at time \(j+1\) (new concepts added). The algorithm finds newly added concepts and explores the context of each newly added concept. Source level is the maximum distance between the newly added concept and the concept to be explored. In this example, the context of the right concept is explored using source level 1.
After finding concepts inside the context of newly added concepts that align at time j, the aligned concepts from target ontologies are added as candidate concepts. The context of each aligned concept in the target ontology is explored and added as candidate concepts. Target level is the maximum distance between the aligned concept and the candidate concept in the target ontology. Figure 2 illustrates this situation using target level 1. The number of candidates depends on how dense the ontology is. The denser and more connected, the higher the number of candidate concepts.
Fig. 1
Situations before applying alignment algorithm. Adapted from [7]
Fig. 2
Calculating similarity with candidate concepts. Adapted from [7]
Algorithm 1 requires a source ontology in time j, source ontology in time j + 1, target ontology in time j, mapping between source and target ontology in time j, a natural number \(\gamma\) as source level, a natural number \(\lambda\) as a target level and a real number \(\tau\) defining the threshold. The source level, target level, and threshold can be defined by the user. The algorithm computes the difference between two given versions of the source ontology (line 1). For each newly added concept \(c_i^\), the algorithm considers a candidate concept, namely \(c_t^\) in the target ontology by exploiting already existing mappings related to \(CT(c_i^, \gamma )\) (lines 4-8). This algorithm explores information from the past version of the ontology to refine new mapping for the newer version. Hence, the mapping used to explore is recovered from the previous evolution version (\(c_k^\)) of the concept \(c_k^\) found in the context of \(c_i^\).
For each \(c_t^\), the algorithm obtains a set of concepts from \(CT(c_t^, \lambda )\). We determine a new refined mapping by calculating the similarity between a new concept \(c_i^\) of \(\mathcal ^_S\) and a candidate \(c_n \in \mathcal _t\). Algorithm 1 searches for the candidate \(c_t\) that yields the maximum similarity value. To calculate the similarity between those concepts, each attribute of the evaluated concept is compared with attributes in candidate concepts. The best similarity value obtained between those attributes is defined as the similarity between two concepts. If the maximum similarity among attributes of the concept is greater than or equal to a threshold \(\tau\), the algorithm establishes a mapping between the newly added concept and the candidate target concept (lines 10-18).

Algorithm 1 Contextual approach to mapping refinement
In order to compare with the results obtained by our approach, we propose another algorithm that ignores new concepts’ context to calculate similarity. It means that the algorithm computes the similarity between each newly added concept with all concepts in the target ontology.
Algorithm 2 computes the difference between two given versions of the source ontology (line 1). For each newly added concept, the algorithm compares the concept with all concepts from the target ontology using similarity computed with concept attributes. If the maximum similarity is greater than a given threshold \(\tau\), a new mapping is created between the newly added concept and the concept from the target ontology with the best similarity (lines 2-13).

Algorithm 2 All concepts approach mapping refinement
In our algorithms, the attributes of each source concept are compared with attributes of all target concepts to obtain similarity value between concepts. The value of similarity between two concepts is the maximum value of similarity from their attributes.
Let n be the quantity of newly added concepts and m the quantity of all concepts in the target ontology. Algorithm 1 computes the similarity of each newly added concept and all candidate concepts in the target ontology. The size of candidate concepts for each added concept varies by the source level and target level used. If the source level and target level are high enough, the number of candidates can be approximated by m, resulting in time complexity of \(O(n \times m)\). However, the source level and target level explored in this research used low numbers. For this reason, the size of candidate concepts is approximated as a constant resulting in time complexity O(n). Algorithm 2 computes the similarity of each newly added concept and all concepts in the target ontology, consequently, the time complexity is \(O(n \times m)\).
Analysing old ontology version to refine mappingsIn this section, we define mapping refinement actions and design algorithms to use them as pre-defined behavior to enrich ontology mappings according to ontology evolution.
Three distinct actions for refining mappings are defined (cf. Fig. 3): derivation of source concept, derivation of target concept and semantic relation modification. In the following, we formally describe each action. To this end, let \(m_ \in \mathcal _^j\) be the mapping between two particular concepts \(c_s \in \mathcal _S^j\) and \(c_t \in \mathcal _T^j\).
Fig. 3
Mapping refinement actions. New mappings added by actions are represented by dashed blue lines. Note: Reprinted from [6]
Mapping derivation source: an existing mapping from \(\mathcal _^j\) derives a new mapping with the same target concept and different source concept. This action results in the addition of a new mapping \(m_\) to \(\mathcal '^j_\).
$$\begin \begin deriveS(m_,c_k)\longrightarrow m_\in \mathcal ^j_ \wedge m_\notin \mathcal ^j_ \wedge \\ (\exists c_k \in \mathcal _S^j, m_ \in \mathcal '^j_\wedge sim(c_s,c_k)\ge \sigma ) \wedge \\ m_ \in \mathcal '^j_ \end \end$$
(5)
where \(sim(c_s,c_k)\) denotes the similarity between \(c_s\) and \(c_k \in CT(c_s, \gamma )\) (neighborhood), and \(\sigma\) denotes the threshold used to compare the derived mapping.
Mapping derivation target: an existing mapping \(m_\) in \(\mathcal ^j_\) derives a new mapping with the same source and a different target, resulting in the addition of a new mapping \(m_\) to \(\mathcal '^j_\).
$$\begin \begin deriveT(m_, c_k)\longrightarrow m_\in \mathcal ^j_ \wedge m_\notin \mathcal ^j_ \wedge \\ (\exists c_k\in \mathcal _T^j, m_\in \mathcal '^j_\wedge sim(c_s,c_k)\ge \sigma ) \wedge \\ m_ \in \mathcal '^j_ \end \end$$
(6)
Where \(c_k \in CT(c_t, \gamma )\) represents the neighborhood of the concept in the target ontology.
Semantic relation modification: the type of the semantic relation of a given mapping is modified. This action is designed for supporting the refinement of mappings with different types of semantic relations rather than only considering the type of equivalence relation (\(\equiv\)). The action can be applied simultaneously with the actions of the derivation of mappings. When deriving a mapping, it is also possible to modify the type of semantic relation of such mapping.
$$\begin \begin modSemType(m_, new\_semType_)\longrightarrow m_ \in \mathcal '^j_ \wedge \\ new\_semType_ \in \ \\ \wedge semType_ \ne new\_semType_ \end \end$$
(7)
In the mapping refinement phase, concepts from two versions of the source ontology (\(\mathcal _S^\) and \(\mathcal _S^j\)) are taken into account to refine a candidate mapping set. The necessary instances of ontology change operations are identified from one ontology version at time \(j-1\) to another at time j with a comparison computation procedure [9]. It generates a set of changes identified between two versions of the same ontology. The change history of the ontology, provided by the authors or curators of the ontology, may also be used if available. In this article, we only consider the newly added concepts from version \(\mathcal _S^\) to \(\mathcal _S^j\).
As input for our mapping refinement procedure, we consider a set of input mapping set candidates \(\mathcal ^j_\). In this sense, our procedure is not responsible for creating the initial whole set of mappings. We describe the mapping refinement procedure in two phases:
1Either the change history or the output of executed ontology change detection tools is used to identify mappings with the potential of refinement, based on the type of ontology evolution operations affecting the concepts in \(\mathcal _S^\). For instance, the addition of a concept to an ontology may indicate a specialization of another concept (e.g., the concept Eagle in \(\mathcal _S^\) was added as a child of the concept Bird, being the former a specialization of the latter). Therefore, any candidate mapping involving the concepts Eagle and Bird are identified with the possibility of refinement.
2After the selection of mappings for refinement, for each selected mapping from \(\mathcal _^\), an action is executed based on the type of ontology change. The action may include a direct decision to perform modification in the semantic relation of the candidate mapping (e.g., a \(\equiv\) relationship may be replaced with a \(\sqsubseteq\)), or other appropriate action. This work emphasizes the concept of addition operation in ontology evolution. In this sense, all candidate mappings in \(\mathcal _^\) related to a newly added concept from \(\mathcal _S^\) are subject of refinement by our technique.
AdditionProcedure. This procedure is invoked when \(c_s\) is a new concept added to \(\mathcal _S^j\). Algorithm 3 presents the proposed approach to refining mappings associated with the addition of concepts changes. For each mapping, \(m_\), the neighborhood of both \(c_s\) and \(c_t\) is retrieved to perform a local rematch. The rematch function receives a set of source concepts \(C_s\) and a set of target concepts \(C_t\) and returns a similarity matrix (simMatrix). The objective of applying a local rematch is to compare the similarities between the neighborhood of the source and target concepts.
The similarity values found drive modifications to the semantic relation established in \(m_\). For example, if \(sim(sup(c_s), c_t) > sim(c_s, c_t)\), the algorithm modifies the semantic relation in \(m_\) to the same semantic relation of \(sup(c_s) \text c_t\); and add a new mapping between \(sup(c_s)\) and \(c_t\). The local rematch helps establish a derivation of mapping when the \(sim(c_s, sub(c_t)) \ge sim(c_s, c_t)\) or \(sim(c_s, sup(c_t)) \ge sim(c_s, c_t)\).

Algorithm 3 Mapping refinement for additional changes
We present an example to illustrate the AdditionProcedure. Ontology \(\mathcal _S\) evolved over time by generating different versions from time \(j-1\) to time j, as illustrated by Fig. 4(A). A set of candidate mappings \(\mathcal ^_\) between \(\mathcal _S^\) and \(\mathcal _T^\), at time j, is given as input for the refinement procedure. Figure 4(B) illustrates the mapping \(m_st \in \mathcal ^_\) between concepts \(c_s\) Angina and \(c_t\) Cardiopathy. The refinement procedure requires as input the list of newly added concepts detected from one version of the source ontology to another. Similarity values between concept \(c_s\) Angina and the concepts of the neighborhood of the target concept Cardiopathy at time j are calculated via local rematch (cf. Fig. 4(C)). If the similarity value between the concepts \(c_s\) Angina and some neighbor \(c_\) of \(c_t\) is higher than the original similarity value given by \(sim(c_s,c_t)\), i.e. \(sim(c_s,c_) \ge sim(c_s,c_t)\), the algorithm derives a mapping between \(c_s\) and \(c_\) to reflect this finding (cf. Fig. 4(D)).
Fig. 4
A Ontology change operations (OCO) on \(\mathcal _S\). B Illustration of the mapping \(m_ \in \mathcal ^_\) candidate for refinement. C Computing similarity values between \(c_s\) and the \(CT(c_t, \gamma )\) (neighborhood). D Resulting \(\mathcal '^_\) after our refinement procedure (application of the derivation target action). Note: Reprinted from [6]
For evaluation purposes, we considered an existing mapping set between Logical Observation Identifiers Names and Codes (LOINC) ontology published in English and its linguistic variant in Spanish. LOINC provides a standard for identifying clinical information (laboratory and clinical test results) in electronic reports [23].
This dataset was chosen because LOINC is freely available, widely used in 176 countriesFootnote 1 and presents a regular update schedule of twice a year, providing a number of ontology changes in every new version available. Any matching system may be used for the rematch phase. We used a cross-language matching system available from previous studies [24].
LOINC authors provide the updated changes in the ontology entities in every release in a separate document, specifying the change operations undergone by the entities. The version selected for this evaluation was the 2.65, released in December 2018. The English variant of LOINC contains 89,271 entities, and the Spanish variant contains 54,599 entities.
Our proposed technique requires an initial mapping set as input. For this purpose, we used the existing mapping set between the two linguistic variants of LOINC (one ontology in English and the other in Spanish). Each entity has a unique permanent identifier named LOINC code (in the sense that it cannot be reused even if the entity is deprecated). This code is invariable across linguistic variants. We use LOINC code to identify equivalent entities between the two selected ontologies. In particular, we focused our evaluation on new concept additions actions.
Comments (0)