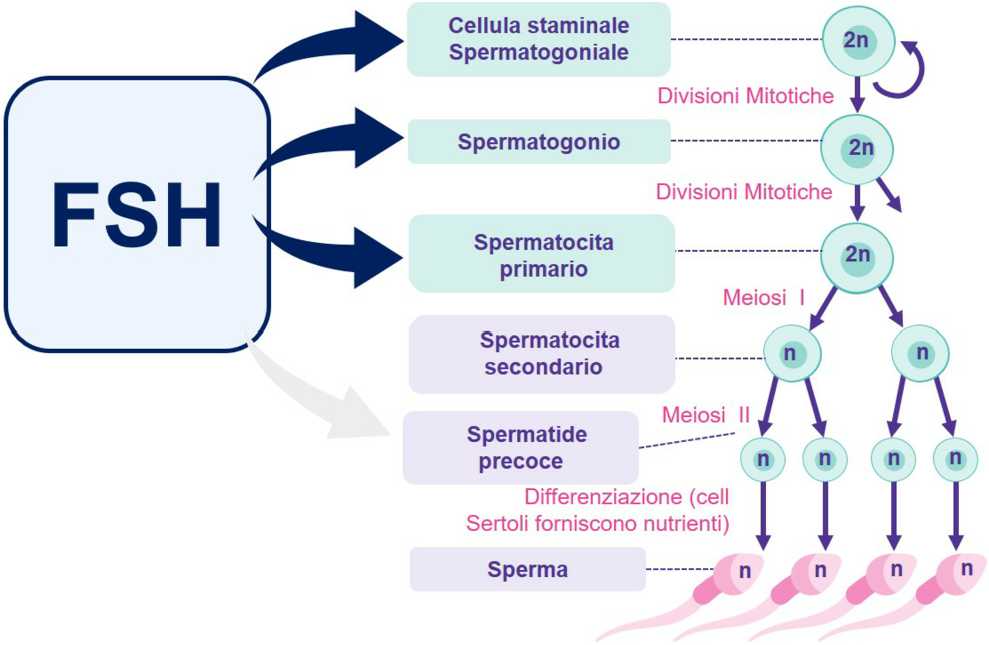
In this study, we developed an AI algorithm to measure clinically relevant spinopelvic parameters on radiographs and validated it in an interdisciplinary multi-reader setting with six experienced physicians, equally consisting of radiologists and surgeons.
All automatic measurements (TK, LL, SS, and SVA) showed excellent correlations with the reference standard, and deviations were all within the range of the readers. Further, no significant differences were found between the errors of the AI to those of the multiple human readers, thereby placing the AI within the field of the naturally occurring differences of multiple clinicians.
Specifically, the mean absolute error was < 5° for all AI-based angles, which has been shown previously as the normal inter-reader variability and is generally regarded acceptable [8, 31]. In-depth analysis showed, that this threshold was undercut in 70–80% of cases, underlining clinical usability. Further, we used a comprehensive validation pipeline including various statistical tests, which offers a high transparency of the results.
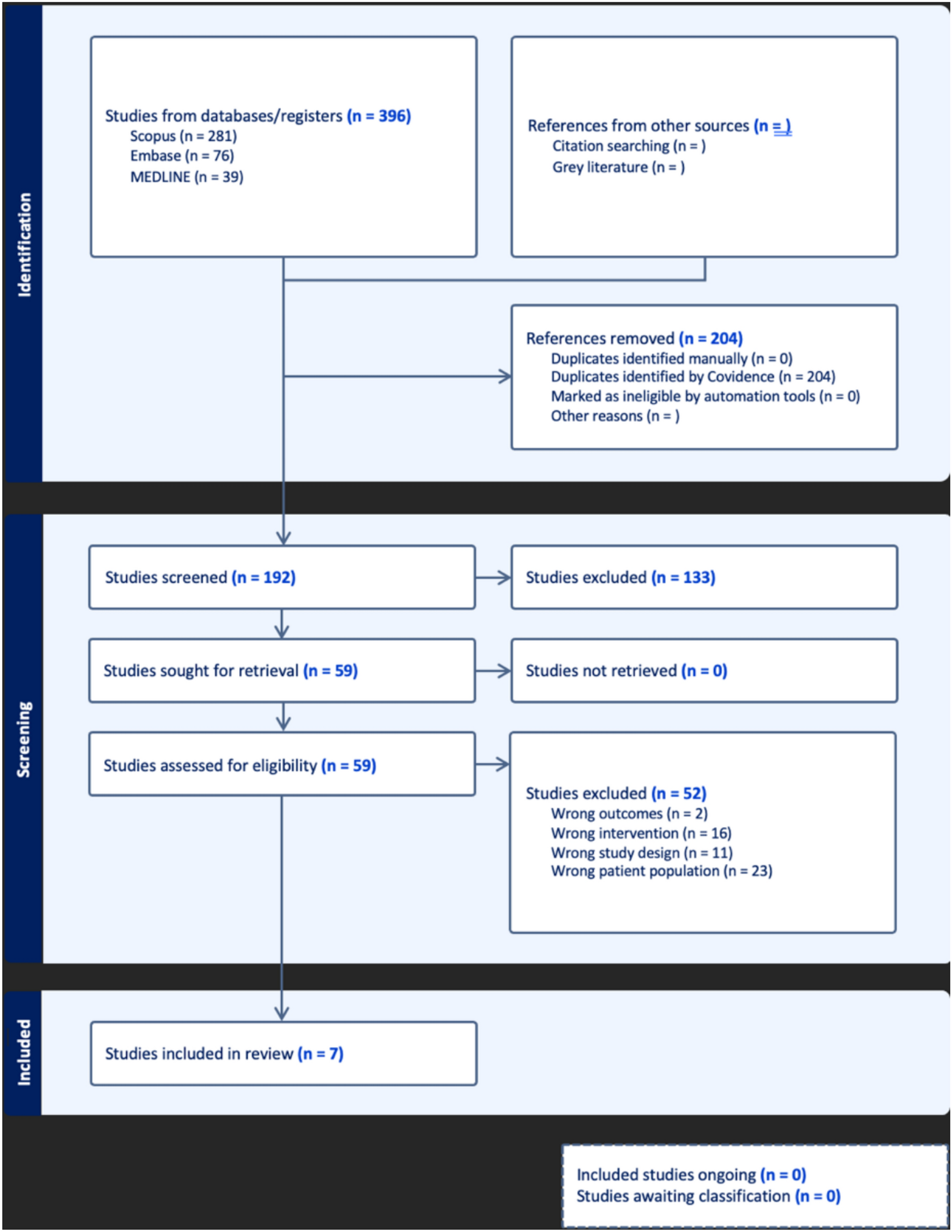
Our model was able to analyze all test cases (success rate 100%), including those with deformities, fractures, or spinal instrumentation, due to the diverse data used for training, increasing clinical value even for challenging cases. In contrast, a previous study reported a success rate of 84% [20], and even in a recent publication [22], some cases failed automatic analysis. Further, even most recent studies only focused on normal cases and excluded spinal pathologies or foreign materials [20,21,22]; while, their strict case selection may have led to better performance in a laboratory setting, their inability to process pathologic cases minimizes clinical value.
Unsurprisingly, automatic measurements only took a fraction of the reading time (< 1 s); while, humans spend on average over 2 min per case. Given the possibility for a human reader to visually counter check a render of the AI-detected landmarks within seconds, this is an excellent use case of “explainable AI” [32] and holds great potential to shorten reading times. Also, automatic analysis over time could identify any abnormal changes and thus help to flag cases suspicious for, e.g., new fractures or failing therapies [5, 6]. For example, a recent meta-analysis proved a significant increase for TK and SVA with the occurrence of osteoporotic vertebral fractures [33]; while, LL and SVA have been shown to be predictive of distal junctional failure after corrective surgery of osteoporotic vertebral fractures [34], and a higher increase in lordosis after lumbar fusion was related to post-operative L5 radiculopathy [35].
In today’s world, where the gap between the steadily increasing number of medical procedures and the stagnating number of medical professionals is widening, resulting in alarming stress levels and burn-out rates [36], AI-based support systems are becoming more a necessity than an option. As multiple recent studies showed, physicians can clearly benefit from AI-systems [11,12,13,14, 37, 38], and through continuous use they can build trust toward an AI, by understanding its’ capabilities and weaknesses, and use the systems effectively [39].
Also, we saw reduced AI performance in a few cases, e.g., with lumbar variations or severe deformities and resulting artifacts—however, these cases also remained challenging for human readers and are known to result in a higher inter-reader-variability in clinical practice. Yet our approach to set the median of the readers as the reference standard (which for an even number of values, such as our six readers, is defined as the mean of the two middle values), also showed a robust reference standard in demanding cases, as every single reader had a relevant number of outliers, which would have led to a false reference standard, but was mitigated by our method.
As one of our study’s biggest strengths, we see our extended interdisciplinary multi-reader comparison, which allowed us to prove the algorithm comparable to multiple clinically experienced experts.
So far, nearly all previous studies only chose a single radiologist or surgeon for the reference standard and comparison [17, 18, 40]. In notable exceptions, a single resident was reviewed by a single senior radiologist [22], or a second reader measured at least half of the cases [23], and only one group so far included three surgeons in comparison [19, 20]. To the best of our knowledge, no study yet has made the effort to include more than three readers; while, we analyzed a total of six readers, consisting equally of experienced radiologists and surgeons.
Our study had limitations, including the retrospective and single-center character. Nevertheless, the proposed model could be used as a starting point for further investigation, e.g., utilizing a federated learning approach with prospective or multi-center data, for re-training and further optimization. Further, we only included data from the EOS System, which has been shown superior to conventional radiographs for higher image quality and lower radiation exposure [25, 26], but may limit the generalizability of our model—however, the deep learning techniques used (CNN) enable transfer learning and the applicability to unseen conventional radiographs should be investigated in future studies. Another limitation could be seen in our relatively small dataset of 295 training cases. However, modern pre-trained models and effective augmentation techniques enable generalizability even with little training data, especially if this represents a broad spectrum of variation (as in our case), and notable performance was previously achieved with comparable [41], or even smaller datasets [18].
In conclusion, we showed that our AI algorithm provides spinopelvic measurements accurate within the variability of multiple experienced readers, but with the potential to save time and increase reproducibility. Future studies should extend these works and further evaluate the clinical impact of AI-assisted reading.




Comments (0)