
Remember me








Embodied cognition, a fundamental theory in cognitive linguistics, posits that human cognition and language are grounded in perceptual experiences and shaped through bodily interactions with the world (Johnson, 1987; Lakoff, 1987; Barsalou, 1999, 2008; Evans and Green, 2006). It challenges the traditional view that language processing involves the manipulation of abstract symbols, proposing instead that it relies on the activation of mental imagery associated with the meaning of sentences or utterances (Zwaan, 2014). The cognitive process of mentally simulating actions, sensations, or spatial configurations described in a text is thought to be an integral part of language comprehension, as it connects linguistic representations to our rich perceptual and experiential knowledge (Zwaan, 2004; Bergen and Chang, 2013; Bergen, 2015).
The early embodied mental simulation theories, such as the perceptual symbol system (Barsalou, 1999, 2008) and the immersed experiencer framework (Zwaan, 2004), propose that cognition is inherently perceptual. According to these theories, our understanding of concepts emerges from integrating modal representations based on multimodal sensory-motor experiences, including vision, audition, movement, and mental states. These experiences are stored symbolically as image schemas in long-term memory, with forms that act as multimodal analogs to the referents. When encountering real-world referents, top-down memory retrieval routinely reactivates these image schemas. These theories emphasize the engagement of language comprehenders in depicted situations where linguistic input triggers their perceptual and motor representations and highlight the dynamic nature of mental representations and experiential states in language processing. While these theories strongly advocate for embodied mental simulation, they have faced criticism. They are more successful in explaining spatial language comprehension than abstract language (Wiemer-Hastings and Graesser, 1999; Zwaan, 2004; Barsalou, 2020), as abstract language often lacks perceptual and experiential grounding without concrete referents in the world (Moseley et al., 2012). Additionally, these theories prioritize the detailed mechanism of sensorimotor activation over language processing, leading to criticism for neglecting the role of linguistic input constructions in mental imagery (Bergen et al., 2007). Nevertheless, they laid the theoretical groundwork for subsequent developments in mental simulation models.
Building upon earlier theoretical frameworks of mental imagery, Bergen and Chang (2005) proposed a computational simulation model and further refined it in 2013. This model represents one of the latest simulation-based language understanding models, which divides language comprehension into three core processes (i.e., constructional analysis, contextual resolution, and embodied simulation). These processes are argued to overlap temporally and mutually influence each other, highlighting the dynamic nature of mental imagery. The constructional analysis process involves identifying the constructional information (form and meaning) instantiated by a given utterance and assembling a corresponding semantic specification that depicts the evoked meaning schemas and their interconnections (Bergen and Chang, 2013). The contextual resolution process maps objects and events in the semantic specification to the current communicative context, resulting in a resolved semantic specification. This stage activates world knowledge about entities and events in the communicative context. The third process, embodied simulation, involves dynamic embodied structures in the resolved semantic specification generating contextually appropriate inferences. According to this computational simulation model, language comprehension not only mirrors traditional syntactic parsing processes that automatically analyze the syntactic structure of a given utterance but also extends its scope to consider the specific communicative context that best situates the meaning of the utterance.
The theoretical models of mental imagery in language comprehension have established robust foundations, prompting empirical studies to validate and refine these frameworks. Most research has focused on visual and motor simulation in processing words and sentences in the first language (L1) (Bergen et al., 2003, 2007, 2010; Bergen, 2005; Bergen and Wheeler, 2005, 2010; Sato and Bergen, 2013; Liu and Bergen, 2016). However, there has been a fast-growing interest in embodied cognition in the context of second language (L2) processing over the last decade. Empirical questions have centered on understanding the accessibility of sensorimotor activation mechanisms in L2 processing and the L2-related factors that influence the interaction between sensorimotor simulation and linguistic processing. Despite the growing body of empirical evidence on L2 mental imagery, there remains a lack of an underpinning theoretical framework. Therefore, the current study aims to make an initial attempt to propose an L2 model of mental simulation, drawing on Bergen and Chang’s (2013) simulation-based L1 processing model. The findings from the current empirical study will also contribute to refining this proposed L2 model.
1.1 Mental imagery in first language processingPrevious studies on embodied mental imagery have explored the interaction between image schema and linguistic representations, uncovering compatibility and interference effects in the language comprehension process. The compatibility effect suggests that language processing activates perceptual neurons associated with mental representations, resulting in faster responses to corresponding images compared to incompatible ones (Stanfield and Zwaan, 2001; Zwaan et al., 2002; Bergen, 2007). For instance, when processing a sentence like A boy climbs a mountain, the UP-DOWN schema might be activated, leading to quicker responses to a vertical spatial configuration than to a horizontal one. In contrast, the interference effect indicates that language processing occupies the same perceptual neurons of mental representation, potentially hindering responses to corresponding images and causing delays compared to incompatible images. This phenomenon has been observed in studies where language processing interferes with the mental imagery of corresponding visual representations (Bergen, 2005; Kaschak et al., 2005; Bergen et al., 2007; Connell, 2007). These early findings establish the foundation for understanding how language comprehension involves mental imagery and how the embodied nature of cognition shapes the interpretation of linguistic expressions.
The sentence-picture verification task (SPVT) paradigm is widely used to examine mental imagery effects, often employing response time (RT) analysis (Stanfield and Zwaan, 2001; Bergen et al., 2003; de Koning et al., 2017a). In the SPVT, participants are presented with a sentence followed by a picture, and they must quickly determine whether the picture matches or mismatches the content of the preceding sentence. For instance, a seminal study by Stanfield and Zwaan (2001) utilized the SPVT to investigate compatibility effects in mental simulation related to spatial orientation. Participants read a sentence implying the orientation of a concrete object, e.g., “John put the pencil in the drawer” (horizontal) or “John put the pencil in the cup” (vertical), and viewed a picture of the object presented in either horizontal or vertical orientation. The results indicated that verification RTs were 44 milliseconds shorter in the matching condition than the mismatching condition, suggesting a compatibility effect. This implies that recognition of objects by English native speakers (NSs) was influenced by the orientation implied in the sentences. In summary, the SPVT paradigm has been pivotal in revealing the role of mental imagery in L1 processing, particularly highlighting the interplay between activated image schemas and semantic specifications.
So far, mental imagery effects have primarily been investigated in the context of L1 processing by adult NSs. Variations in these effects across studies are attributed to factors such as target languages (Sato et al., 2013; de Koning et al., 2017b; Chen et al., 2020; Bai et al., 2022), abstractness of meaning (Richardson et al., 2003; Bergen et al., 2007; Richardson and Matlock, 2007; Guan et al., 2013; Liu and Bergen, 2016), and processing capacity (Madden and Zwaan, 2006). Regarding crosslinguistic variations, Chen et al. (2020) examined whether mental simulation was affected by object size and orientation through an SPVT among L1 English, Mandarin Chinese, and Dutch speakers. Despite the similar compatibility effects of orientation identified in Chinese and English, the slower RTs and lower accuracy rates (ARs) in L1 Chinese participants underscore potential concerns about the validity of task stimuli in Chinese. Moreover, they found the effect magnitude for orientation was smaller than object size, which raises the question of whether the smaller effect was attributed to the lack of control of semantic dynamicity in orientation, given some sentences expressed a static scene (e.g., The pen is on the table), while some expressed dynamic movement (e.g., The missile was flying over the sea). This lack of consideration of dynamicity and between different L1 groups appeal for an examination of mental imagery in processing sentences that express dynamic spatial orientation (i.e., directionality) in particular and further comparisons between languages like Mandarin Chinese and English to deepen our understanding of language-specific influences.
Previous empirical findings have confirmed the controversy surrounding the applicability of embodied mental simulation theories (Barsalou, 1999, 2008; Zwaan, 2004) in abstract language processing. The existing findings are mixed, with some studies showing a comparable simulation effect in both concrete and abstract language (Glenberg and Kaschak, 2002; Richardson et al., 2003; Richardson and Matlock, 2007; Guan et al., 2013; Wang and Zhao, 2024), while others observed simulation effects only in concrete language but not in abstract language processing (Bergen et al., 2007; Bergen and Wheeler, 2010; Liu and Bergen, 2016). These mixed findings could be attributed to the different varieties of sensorimotor features being investigated in these studies, such as motion (Glenberg and Kaschak, 2002; Richardson and Matlock, 2007; Bergen and Wheeler, 2010; Guan et al., 2013; Liu and Bergen, 2016), and spatial orientation (Richardson et al., 2003) in the vertical axis (up vs. down)(Bergen et al., 2007). Because these sensorimotor features may engage different cognitive mechanisms depending on the concreteness or abstractness of the language, the inconsistencies in previous research may arise from variations in how these features interact with different types of linguistic content. Therefore, the present study focuses on mental imagery in the processing of literal and abstract language expressing spatial directionality.
1.2 Mental imagery in second language processingThere is a recent surge in interest in understanding how embodied mental simulation operates in L2 processing (Monaco et al., 2019; Norman and Peleg, 2022; Wang and Zhao, 2023, 2024; Chen et al., 2024; Vanek et al., 2024). Findings from L2 mental imagery studies have revealed both similarities and differences compared to L1 mental imagery patterns. Similar to observations in L1 mental imagery studies, compatibility (Tomczak and Ewert, 2015; Ahn and Jiang, 2018; Koster et al., 2018), and interference effects (Wheeler and Stojanovic, 2006; Vukovic and Williams, 2014) have been reported in the L2 context. However, certain studies also identified partial simulation (Atkinson, 2010; Foroni, 2015; Norman and Peleg, 2022) or no mental imagery effect in L2 processing (Wu, 2016; Chen et al., 2019).
Existing studies argued that L2 mental imagery is modulated by several key factors, including variations across languages and perceptual features (Koster et al., 2018; Zhang and Vanek, 2021). For example, Koster et al. (2018) investigated Spanish learners of L2 German and German learners of L2 Spanish using SPVTs. They examined orientation and size, drawing on crosslinguistic differences between German and Spanish. Their results revealed no mental imagery effects for orientation in both NSs and L2 learners. Interestingly, Spanish NSs exhibited size-related compatibility effects, while L2 Spanish learners did not, mirroring patterns observed in Dutch child speakers (de Koning et al., 2017b). These findings suggest a potential extension of L1 mental imagery effects related to size into the realm of L2, with language-specific factors modulating L2 mental imagery effects, as evidenced by the absence of a size effect in German.
L2 mental imagery can also be modulated by the abstractness of meaning. L2 mental imagery in abstract language processing might not be as intuitive and automatic as in L1. Abstract meaning could be relatively more difficult for L2 learners to comprehend compared to literal meanings (Littlemore and Low, 2006; Littlemore et al., 2011; Shi et al., 2023). Nevertheless, the investigation of L2 mental imagery in abstract language processing are very few and still controversial (Feng and Zhou, 2021; Wang and Zhao, 2023, 2024). Feng and Zhou (2021) adopted a picture priming paradigm to examine the embodiment of verbs in predicate metaphor processing in L1 Mandarin and L2 English. In the priming task, participants were presented with a related or unrelated picture prime and then read L2 English and L1 Mandarin sentences containing conventional or novel metaphors. Results showed stronger compatibility effects on processing novel predicate metaphors (e.g., The tax pinched the industry.) in both high-proficiency and low-proficiency L2 learner groups but weaker compatibility effects on processing conventional predicate metaphors (e.g., The newspaper bent the truth.) in the lower L2 proficiency group. The finding suggests the graded compatibility effects could be affected by metaphor novelty and L2 proficiency.
Wang and Zhao, (2023, 2024) adopted a semantic priming paradigm to examine the mental imagery effects on processing prepositional phrases (PPs) encoding spatial (e.g., in the drawer) and abstract meanings (in the fear). The spatial meaning of the target preposition represents the prototypical sense, while the selected abstract meaning was chained to the prototypical spatial meaning and motivated by the conceptual metaphor (i.e., STATE IS A CONTAINER). In the semantic priming task, participants saw a related or unrelated schematic diagram prime embedded with a trajector (TR) word (e.g., knife) and then judged the grammaticality of the target PP containing a preposition and landmark (LM). Results showed compatibility effects on processing both spatial and abstract language in L2 adolescent English learners (Wang and Zhao, 2023) and interference effects on processing both spatial and abstract language in L2 adult English learners (Wang and Zhao, 2024). The existing evidence of interference and compatibility effects and their interactions with L2 proficiency is insufficient to conclude the patterns of L2 mental imagery in abstract language processing, hence further research on this issue is indispensable.
It was suggested that language proficiency is a significant factor influencing L2 mental imagery effects. Ahn and Jiang (2018) compared L1 and L2 mental imagery related to orientation and shape using the SPVT. Results indicated that both Korean NSs and advanced L2 Korean learners exhibited faster responses in the matching condition compared to the mismatching condition, suggesting native-like semantic integration abilities in advanced L2 proficiency. However, Chen et al. (2019) found distinctive patterns between L1 Cantonese, L2 Mandarin, and L3 English in SPVT results, with compatibility effects observed in L1 processing but no effects in L2 or L3, despite comparable proficiency levels in L1 and L2 but higher proficiency levels in L2 than L3. The results suggest robust evidence of L1 mental imagery but a conspicuous absence of embodied imagery in non-native language comprehension, implying distinct conceptual systems between L1, L2, and L3. Similarly, Norman and Peleg (2022) observed contrastive findings between L1 and L2 mental imagery. Using the SPVT, they investigated bilingual speakers’ L1-Hebrew and L2-English mental imagery effects of shape. Results showed compatibility effects in L1 processing, whereas this pattern was not observed in L2 processing with an intermediate level, leading the authors to argue for reduced mental imagery effects in L2 relative to L1.
Two possible accounts can explain the interactions between L2 proficiency and mental imagery. Firstly, limited L2 proficiency can result in considerable cognitive resources allocated to L2 comprehension, leaving fewer resources for perceptual simulation (Atkinson, 2010). This often leads to partial simulation (Norman and Peleg, 2022) or even no simulation (Chen et al., 2019). Secondly, compared to L1, there is a weaker link between perceptual representations and L2, as L2 comprehension may not be as grounded in sensorimotor knowledge as L1 comprehension (Dudschig et al., 2014). This discrepancy leads to distinct formations of L1 and L2 mental representations, resulting in different mental imagery outcomes in L1 and L2 (Chen et al., 2019; Norman and Peleg, 2022). However, as L2 proficiency increases, L2 mental representations may converge with the established L1 representation system (Foroni, 2015), potentially reducing differences between L1 and L2 imagery (Ahn and Jiang, 2018).
Moreover, L2 mental imagery may be influenced by the context of language acquisition. Participants in these studies were late bilinguals who acquired L1 in naturalistic settings and received L2 instruction primarily in formal school settings (Ahn and Jiang, 2018; Chen et al., 2019; Norman and Peleg, 2022). Due to different contexts of language acquisition, the sensorimotor activation in L1 and L2 can be distinct. For late bilinguals acquiring L2 after puberty, their perceptual systems have been shaped by the fully developed L1 system (Pavlenko, 2005; Perani and Abutalebi, 2005; Dudschig et al., 2014). However, with accumulated exposure to L2 instruction and increased L2 proficiency, weaker connections between perceptual representations in sensorimotor neurons and L2 can become stronger and richer (Monaco et al., 2019). In summary, these divergent findings related to proficiency and the context of language acquisition underscore the need for further investigation of their interaction with L2 mental imagery.
Building upon evidence from empirical L2 mental imagery studies and the theoretical model of simulation-based L1 comprehension (Bergen and Chang, 2005, 2013), we propose a simulation-based L2 comprehension model. We hypothesize that the L2 model shares three primary processes—constructional analysis, contextual resolution. and embodied simulation—with slight variations in moderators compared to the L1 model. We posit that L2 mental imagery can be influenced by language-internal, learner, and contextual factors. Firstly, the identification of L2 constructions, based on both L2 forms and meanings, can be influenced by corresponding elements in L1. The language-internal factors, known as the L1 transfer (Ortega, 2013) or L1 entrenchment (MacWhinney, 2005), may have positive or negative effects depending on cross-linguistic similarities and differences. Learner factors such as L2 proficiency might impact the constructional analysis process. Similar to the L1 model, semantic specifications are identified during contextual resolution and then resolved for embodied simulation in the L2 model. Throughout these processes, world knowledge and communicative context are incorporated as contextual factors, instantiated by the length of immersion in an L2 environment and the amount of communication in the L2. Notably, we emphasize the role of the instructional context quantified by the amount of L2 classroom instruction. The context of acquisition is assumed to be a key differentiating factor that may impact the mental imagery effects between L1 and L2 comprehension. Finally, after the simulation process, contextually appropriate inferences are generated to support L2 comprehension.
2 The present studyTheoretically, we aim to validate the proposed L2 mental simulation model by examining language-internal, learner, and contextual factors. Existing studies have discussed potential influential factors of L2 mental simulation, with relatively more studies focusing on language-internal (Vukovic and Williams, 2014; Tomczak and Ewert, 2015; Wu, 2016; Koster et al., 2018) and learner factors (Wheeler and Stojanovic, 2006; Qian, 2016; Ahlberg et al., 2018; Ahn and Jiang, 2018; Chen et al., 2019) and less attention on contextual factors (Ahn and Jiang, 2018; Chen et al., 2019; Norman and Peleg, 2022). Given the limited quantitative testing of the contextual factor in previous studies, the current study aims to explore its contribution to mental simulation effects in L2 processing.
The present study examined mental imagery of spatial directionality in two satellite languages, Mandarin Chinese and English. In Mandarin, directionality is typically encoded in a resultative verb compound (RVC) construction comprised of two components: a displacement verb and a directional verb (Li and Thompson, 2009). The displacement signals the manner of motion (e.g., zǒu, ‘walk’, and pǎo, ‘run’) or changes in conditions or situations (e.g., tuī, ‘push’, and sòng, ‘send’). The directional verb (e.g., jìn, ‘enter’, and chū, ‘exit’) indicates the path of motion or the directional result of the action implied by the displacement verb. In English, manner is typically encoded in verbs, and path is encoded in prepositions. Into and out of as translation equivalents of Chinese directional verbs jìn (‘enter’) and chū (‘exit’) express dynamic paths of motion deriving from the non-dynamic prepositions in and out (Li and Thompson, 2009; Lindstromberg, 2010). The spatial sense of into expresses “a spatial relation in which the TR is located on the exterior of a bounded LM and is oriented toward the LM” (Tyler and Evans 2003, pp. 199). Tyler and Evans (2003) argued a parallel distinction between out and out of and between in and into. Therefore, the spatial sense of out of expresses a spatial relation in which the TR is located on the interior of a bounded LM and is oriented away from the LM. An abstract sense is also selected according to the conceptual metaphor STATE IS A CONTAINER for each English preposition (Lakoff and Johnson, 1980; Lakoff, 1987) and for each Chinese directional verb (Yin, 2011). Table 1 presents the spatial and abstract meanings of two Chinese directional verbs (jìn, ‘enter’ and chū, ‘exit’) along with two corresponding diagrams with sample sentences. These similarities allow cross-linguistic comparisons between the two languages.
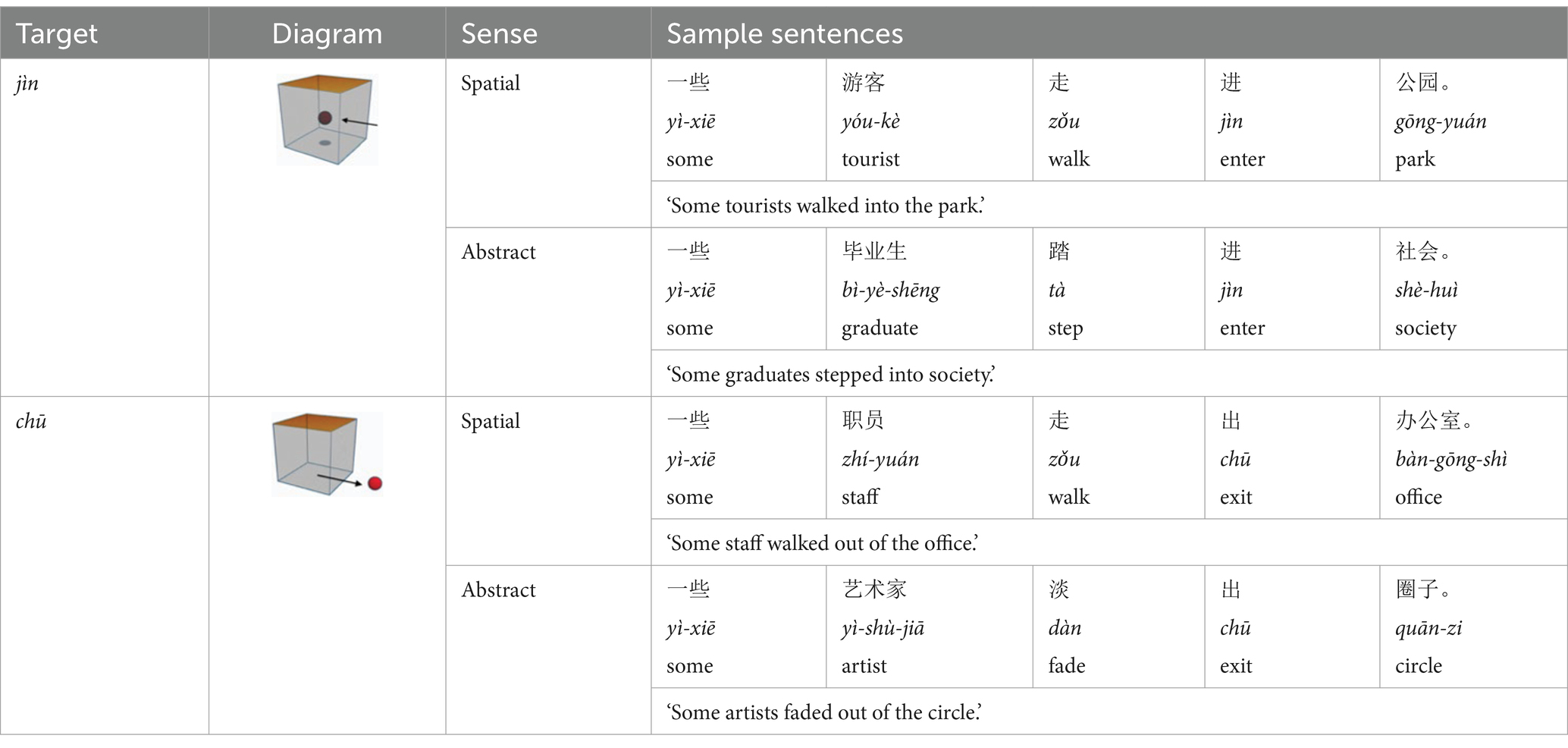
Table 1. Diagrams, senses and sample sentences for jìn (enter) and chū (exit).
Methodologically, our study applies an innovative approach by implementing a sentence-diagram verification task (SDVT), aiming to refine existing methods to address current limitations and provide a more nuanced understanding of mental imagery processes in both L1 and L2 contexts. These diagrams, three-dimensional image schematic representations, capture the spatial configurations of both concrete and abstract meanings in language (Richardson et al., 2003; Tyler and Evans, 2003; Langacker, 2008) and illustrate visual contrasts and figure-ground relationships in mental configurations. Furthermore, diagrams play a crucial role in studying mental abstraction, which demands a higher level of imagination (Zwaan, 2014). In contrast, the SPVT paradigm used in prior sentence-processing studies with concrete pictures (Stanfield and Zwaan, 2001; Zwaan et al., 2002; de Koning et al., 2017b; Schütt et al., 2023) captures the lowest level of embeddedness (i.e., demonstration) and falls short in providing reliable imagery cues for abstract mental concepts and measuring mental representations of abstract language meanings accurately. Schematic diagrams, being abstract visual symbols, are more suitable than pictures for investigating mental representations triggered by the processing of abstract grammatical and semantic domains such as tense-aspect-modality (Tyler et al., 2010; Tyler and Jan, 2017), countability (Langacker, 2008), and figurativeness (Holme, 2004). These domains are argued to have theoretical underpinnings in concrete spatial domains (Lakoff, 1987).
In summary, further empirical evidence is required to substantiate and refine the proposed L2 mental imagery model. Due to the limited research on L2 mental imagery, particularly the scarcity of L2 studies utilizing schematic diagrams to investigate mental imagery in bilingual language processing Wang and Zhao, (2023, 2024), it remains challenging to generalize the extent to which L2 aligns with or diverges from L1 mental imagery and the factors influencing these differences. Motivated by these research gaps, the present study employs an innovative SDVT to explore the presence of perceptual representations or mental imagery during language comprehension in adult L1 Chinese (Experiment 1) and L2 English sentence processing (Experiment 2). Guided by the simulation-based L2 understanding model, we manipulate two semantic specifications, namely spatial directionality and abstractness of senses. More specifically, the study aims to address the following research questions:
1. Do Chinese L2 learners of English enact mental imagery in L1 Chinese and L2 English sentence processing?
2. If yes, to what extent is the mental imagery modulated by spatial directionality (jìn / into vs. chū / out of) and abstractness of senses (spatial vs. abstract) in L1 Chinese and L2 English, respectively?
3. Does contextual factor interact with L2 mental imagery?
3 Experiment 1 3.1 Participants21 Chinese adults (4 males and 17 females) were recruited from a public university in Australia (mean age = 22.62, SD = 1.94). Among them, 9 were undergraduates and 12 were postgraduates majoring in fields such as arts, education, science, and commerce. All participants spoke Mandarin Chinese as their L1. They were asked to rate their L1 proficiency on a numeric scale ranging from 10 to 100, and their average self-rated L1 proficiency was 89.05 (SD = 13.48). Additionally, some participants reported knowledge of other languages, including Cantonese (n = 2), Japanese (n = 2), Korean (n = 1), and German (n = 1). Moreover, several participants were proficient in various Chinese dialects, including Shanghainese (n = 2), Wu dialect (n = 2), Anhui dialect (n = 1), Fujian dialect (n = 1), Hebei dialect (n = 1), Sichuan dialect (n = 1), Zhoushan dialect (n = 1) and Suzhou dialect (n = 1). Informed written consent was obtained from each participant in advance. Upon task completion, each participant received monetary compensation for their time of participation.
3.2 Materials and designExperiment 1 aimed to test whether the shared image schemas between spatial and abstract senses could generate mental imagery effects in L1 Chinese sentence processing. The stimuli in Experiment 1 consisted of 80 target sentences (20 sentences × 2 directional verbs × 2 senses) and 40 filler sentences. Among the 80 target sentences, 56 sentences (14 sentences × 2 directional verbs × 2 senses) were used as the SDVT stimuli, and the remaining 24 sentences (6 sentences × 2 directional verbs × 2 senses) were used as the semantic rating task stimuli. For the SDVT, we adopted a 2 directional verb (jìn, chū) × 2 sense (spatial, abstract) × 2 Congruency conditions (matching, mismatching) factorial Latin-square design. To counterbalance the target sentence stimuli in the matching and mismatching conditions, we created two stimuli lists so that there was no overlap of target sentence stimuli between the matching and mismatching conditions. In addition to the 56 target sentences, each SDVT stimuli list comprised 40 filler sentences, which remained the same in the two counterbalanced lists. All filler sentences were adapted from sample sentences in the Chinese grammar book (Ross and Ma, 2014), which had comparable lengths to the target sentences but did not involve the two target Chinese directional verbs (e.g., shí táng de yān cōng yī dào zhōng wǔ jiù mào yān, ‘The canteen chimney starts to emit smoke at noon’). In addition to the target into and out-of diagrams, two diagrams representing the UP-DOWN schema were created as fillers in the SDVT. Altogether, 96 sentences and 4 diagrams were used in the SDVT. For the semantic rating task, there was only one stimuli list with 24 target sentences but no filler sentences. The target sentences in the SDVT and semantic rating task shared the same syntactic construction with six segments, including a determiner, an adjective, a subject, a displacement verb, a directional verb, and an object noun (Example 1). There was no overlap in the target sentence stimuli between the two tasks (Supplementary material 1).
Example 1

Frequencies of RVC phrases and RVC-object collocations in 80 target sentences were checked using the Corpus of Chinese Linguistics (CCL) (Zhan et al., 2003, 2019). After log-transformation, one-way ANOVA results revealed no significant differences in RVC phrasal frequency between items of the two directional verbs (F = 1.808, p = 0.183) or senses (F = 3.396, p = 0.069). Similarly, there were no significant differences in RVC-location collocation frequency between items of the directional verbs (F = 1.104, p = 0.297) or senses (F = 0.302, p = 0.584). Additionally, the sentence lengths in characters between stimuli of directional verbs (F = 1.960, p = 0.165) or senses (F = 0.002, p = 0.962) were balanced.
To norm the semantic congruency between the conceptualizations of embodied scenes in two diagrams and Chinese sentences containing two directional verbs, an untimed semantic rating task was conducted. In this task, participants were presented with two blocks one by one. In each block, they saw one of the two diagrams (into or out-of diagram) and 12 Chinese sentences containing the corresponding directional verbs jìn (‘enter’) or chū (‘exit’). Half of the sentences expressed the spatial meaning, while the other half expressed the abstract meaning. Participants were instructed to rate the consistency of spatial configurations between diagrams and Chinese sentences on a 7-point Likert scale (1 = completely inconsistent, 7 = completely consistent) (see Figure 1). No time constraints were imposed, and no corrective feedback was provided during this task.

Figure 1. Sample stimuli of the Chinese semantic rating task.
The SDVT in the current study followed the Chinese SPVT procedure described by Chen et al. (2020). Participants were initially presented with a fixation spot for 1,000 milliseconds. Subsequently, a prime sentence was displayed at the center of the screen (e.g., yī-wèi qín-fèn-de yuán-gōng zǒu jìn bàn-gōng-shì, translated as ‘A diligent employee walked into the office.’). Participants read the prime sentence at their own pace and pressed the space bar as soon as they finished reading. Once the space bar was pressed, the prime sentence was replaced by another fixation point at the center of the screen, which remained visible for 500 milliseconds. Finally, participants were presented with a diagram and tasked with verifying whether the spatial configuration depicted in the diagram was consistent with the meaning conveyed in the sentence they read. Participants made a binary judgment within 5 s by pressing ‘F’ or ‘J’ on the keyboard, representing ‘No’ or ‘Yes’ responses (Zwaan et al., 2004). If a response was not made within 5 s, the screen advanced to the fixation point for the next trial. A sample trial, depicting a sentence containing the spatial sense of jìn in the matching condition, is illustrated in Figure 2.
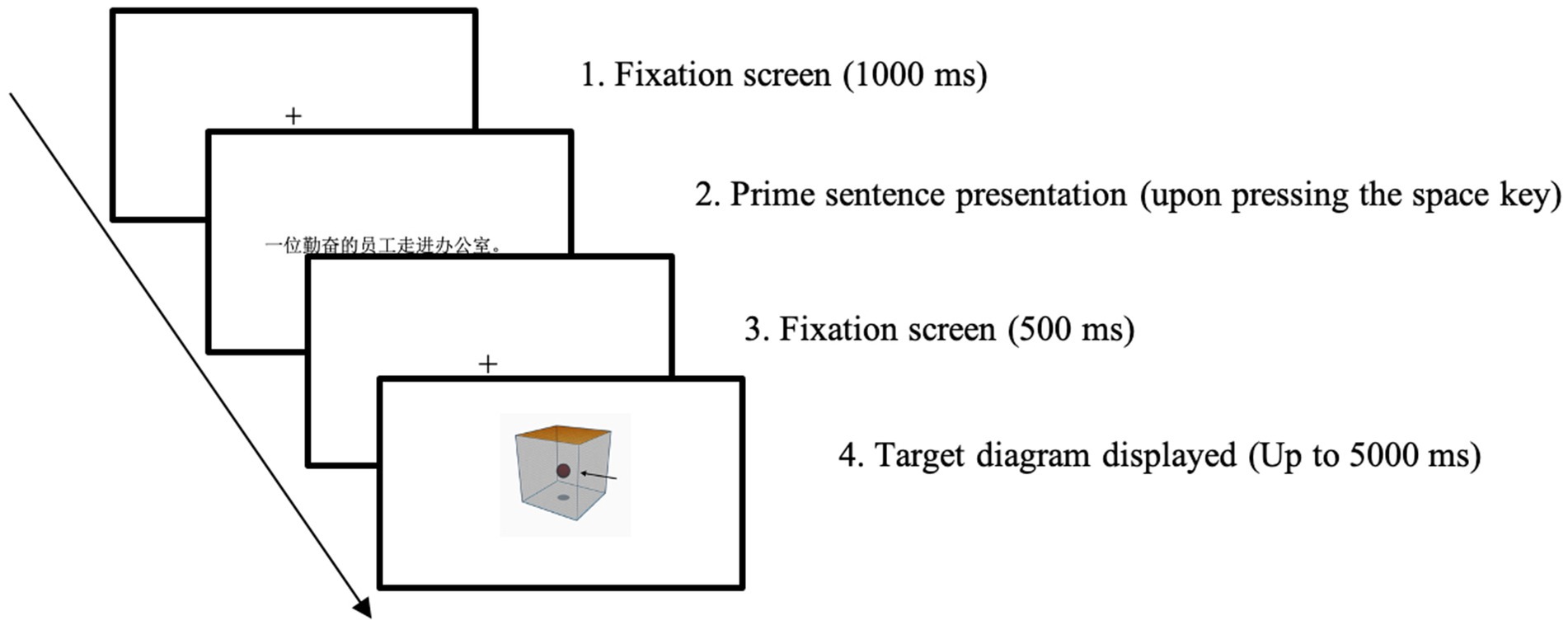
Figure 2. A sample matching trial of the SDVT (prime—a sentence of spatial sense of jìn; target—into diagram).
To familiarize participants with the SDVT procedure, a practice session was added before the formal session. In the practice phase, participants completed 20 practice trials and received corrective feedback with L1 explanations on each practice trial. The explanations demonstrate the one-on-one corresponding relationship between the TR and LM in the sentence stimuli and their referents (the red circle and gray cube) in diagram. Data from practice trials were excluded from the analysis. In the formal session, participants did 96 trials without any feedback. Only the RTs (from the onset of the diagram display to the onset of a button response) and ARs of the trials in the formal session were analyzed.
3.3 ProcedureData collection sessions were implemented online using PsyToolkit (version 3.4.4)(Stoet, 2010, 2017). Before the commencement of the experiment, written informed consent was obtained from each participant. Following this, participants completed a demographic questionnaire, which gathered basic information including gender, age, educational background, and language history. Subsequently, participants were randomly assigned to one of the two counterbalanced lists and completed the SDVT. After a short break, the untimed semantic rating task was carried out. The reason for conducting the Chinese semantic rating task after the SDVT was to minimize the potential influence of revealing the research focus through the rating task before the SDVT. Each data collection session had a duration of approximately 20 min. Only one attempt was allowed for each participant to complete the tasks, and they were not permitted to revisit or modify their previous answers.
3.4 Data analysisData were analyzed using R software (version 4.0.3) (R Core Team, 2024). Before the analysis, data trimming was performed. Since all participants achieved ARs above 80% (ranging from 89 to 100%) in the SDVT, all participants’ data were deemed reliable and included in the data pool. Only RTs with correct diagram verification responses to target trials in the formal task phase were subjected to analysis. Trials with verification RTs shorter than 200 milliseconds and longer than 3,000 milliseconds were excluded due to unreliability, resulting in the removal of 2.6% of data points. The lme4 package (Bates et al., 2022) was used to construct mixed-effects models, which tested the fixed effects of the condition and the random effects of participants and stimuli on RTs. The lmerTest package (Kuznetsova et al., 2017) was used to calculate p values. Semantic ratings, RTs, self-rated L1 proficiency, and sentence reading time were log-transformed. RTs were analyzed using linear mixed-effects models (Linck and Cunnings, 2015). We included random intercepts for participants and items and by-participant random slopes for directional verbs and senses. Self-rated L1 proficiency and sentence reading time were treated as covariates in the initial model. We used anova function to compare the fits of models and justify the choice of these models. The models converged well and were checked for statistical assumptions. The emmeans package (Lenth et al., 2023) was used to apply Tukey correction for pairwise comparisons. Cohen (1977) was reported as the effect size for RTs and was interpreted based on the recommendation in Plonsky and Oswald (2014): 0.60, 1.00, 1.40 corresponding to small, medium, and large effect sizes for within-subject contrasts, and 0.40, 0.70, and 1.00 as small, medium, and large effect sizes for between-group contrasts. Graphics were generated using the ggplot2 package (Wickham, 2016).
3.5 Results 3.5.1 Results of the Chinese semantic rating taskTable 2 presents the means and SDs of semantic ratings for the consistency between diagrams and sentences involving two directional words with spatial and abstract senses. The results of one-way ANOVA revealed no significant differences in the ratings across the four diagram—sense categories (F = 1.187, p = 0.32), between directional verbs (F = 1.248, p = 0.271), or between senses (F = 2.075, p = 0.157). Given that the average rating scores all exceeded 6 out of 7, it can be concluded that the diagrams were consistently and reliably aligned with the spatial configurations of both the spatial and abstract senses of the two Chinese directional words in the sentences. Consequently, responses verifying a matching diagram after reading a sentence with a consistent meaning were categorized as correct judgments, while responses rejecting a mismatching diagram after reading a sentence with an inconsistent meaning were classified as incorrect judgments in the SDVT.

Table 2. Descriptive statistics of the Chinese semantic rating task.
3.5.2 Results of the L1-SDVTTable 3 shows the means and SDs of sentence reading time, and RTs and ARs of diagram verification by Directional verb, Sense, and Congruency of the Chinese SDVT.
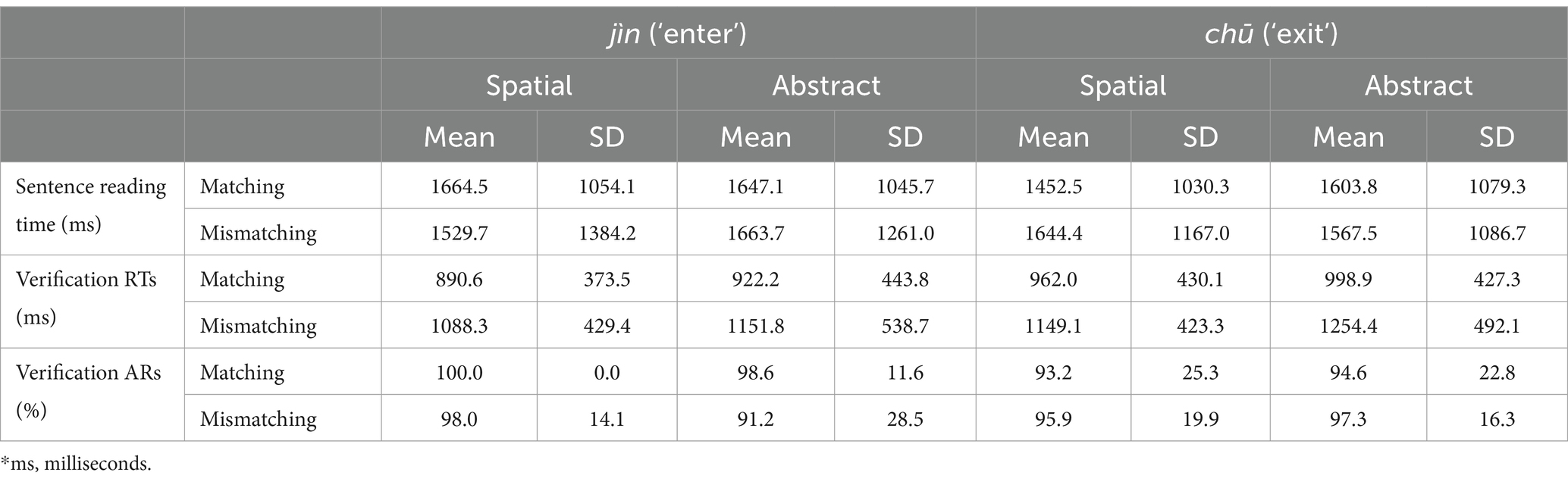
Table 3. Descriptive statistics of sentence RTs, and diagram RTs and ARs of the Chinese SDVT.
We compared the fits of the three-way interaction model with the two-way interaction model. The results showed the two-way interaction model better fit the data. Results of the two-way interaction model revealed that sentence reading time was a significant covariate, but L1-Mandarin self-rated proficiency was not. Sense did not have significant fixed effects on RTs or have significant interaction with Congruency (Supplementary material 2). After removing the non-significant covariate and Sense, results of the simplified model (Table 4) showed sentence reading time was a significant covariate, indicating as sentence reading time increased, RTs of diagram verification increased. Results also revealed that Directional verb and Congruency had significant fixed effects, but their interaction was not significant.
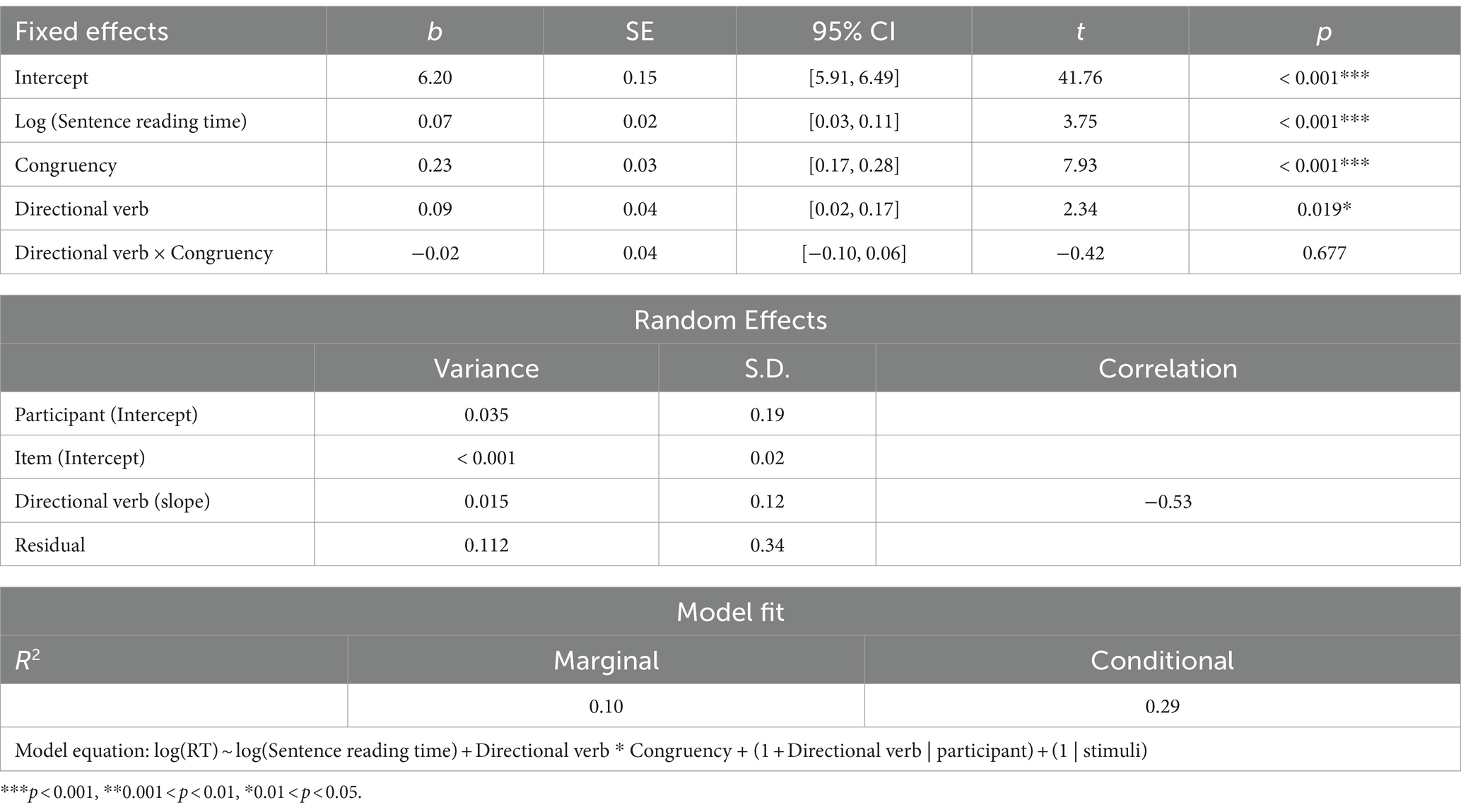
Table 4. Results of the linear mixed-effects model for RTs of the Chinese SDVT.
The post hoc analyses revealed that the mean RTs in the matching condition [M = 883, SE = 34.0, df = 23.6, 95% CI (816, 957)] were estimated to be 214 ms shorter than those in the mismatching condition [M = 1,097, SE = 42.4, df = 23.8, 95% CI (1,013, 1,188)] [Cohen’s d = 0.65, SE = 0.06, df = 23.6, 95% CI (0.52, 0.78), corresponding to a small compatibility effect]. Furthermore, the post hoc analyses indicated that the mean verification RTs after reading sentences with jìn (‘enter’) [M = 944, SE = 41.1, df = 20.5, 95% CI (862, 1,033)] were estimated to be 83 ms shorter than those of chū (‘exit’) [M = 1,027, SE = 39.3, df = 20.7, 95% CI (948, 1,112)] [Cohen’s d = 0.25, SE = 0.10, df = 20.5, 95% CI (0.04, 0.47), corresponding to a small effect]. Figures 3, 4 present the RTs of diagram verification by Congruency and Directional verbs, respectively. Additionally, we build a follow-up model including self-rated proficiency as a covariate to examine the sentence reading time (Supplementary material). Results revealed no significant fixed effects of any variables.
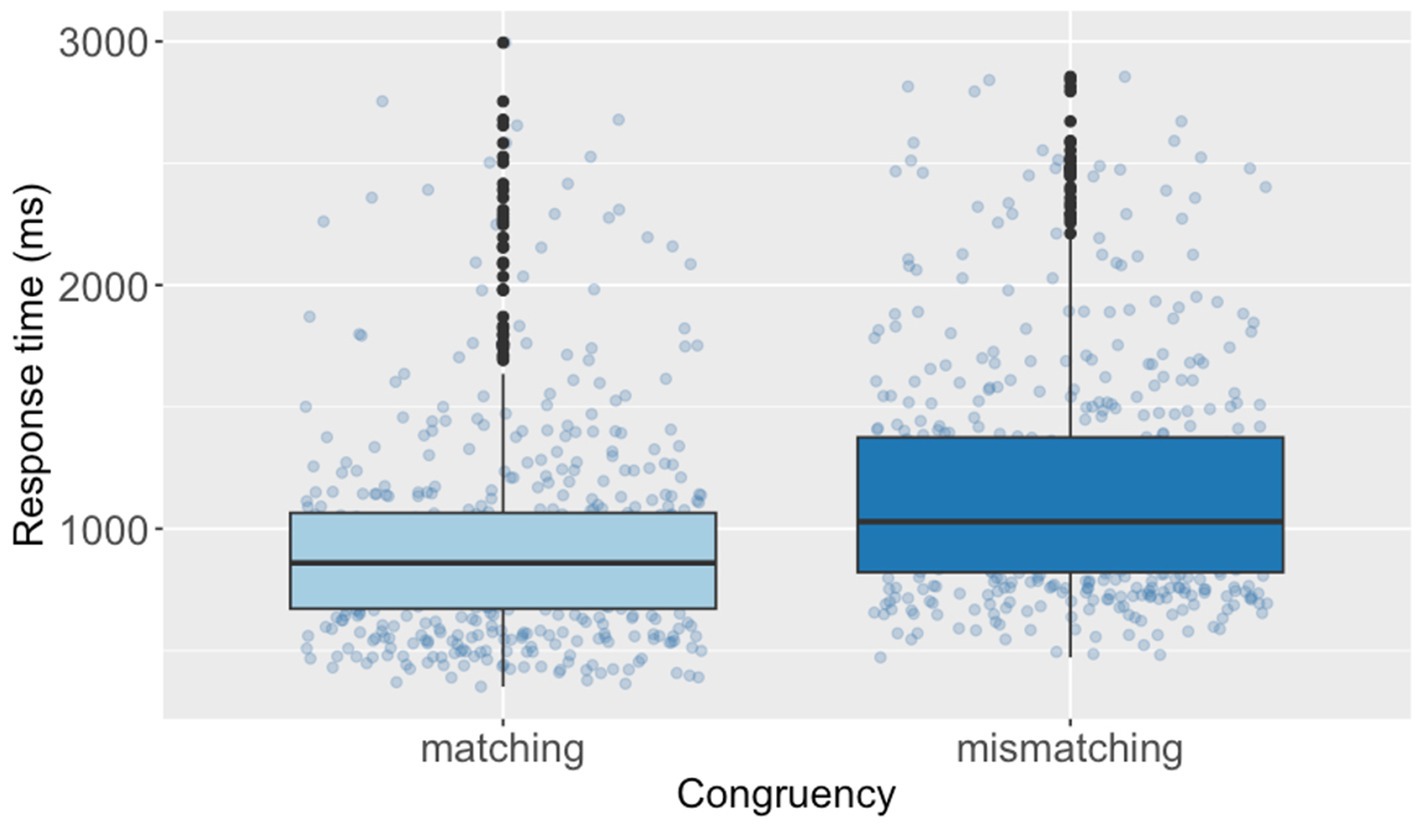
Figure 3. Response times of diagram verification by congruency of the Chinese SDVT.
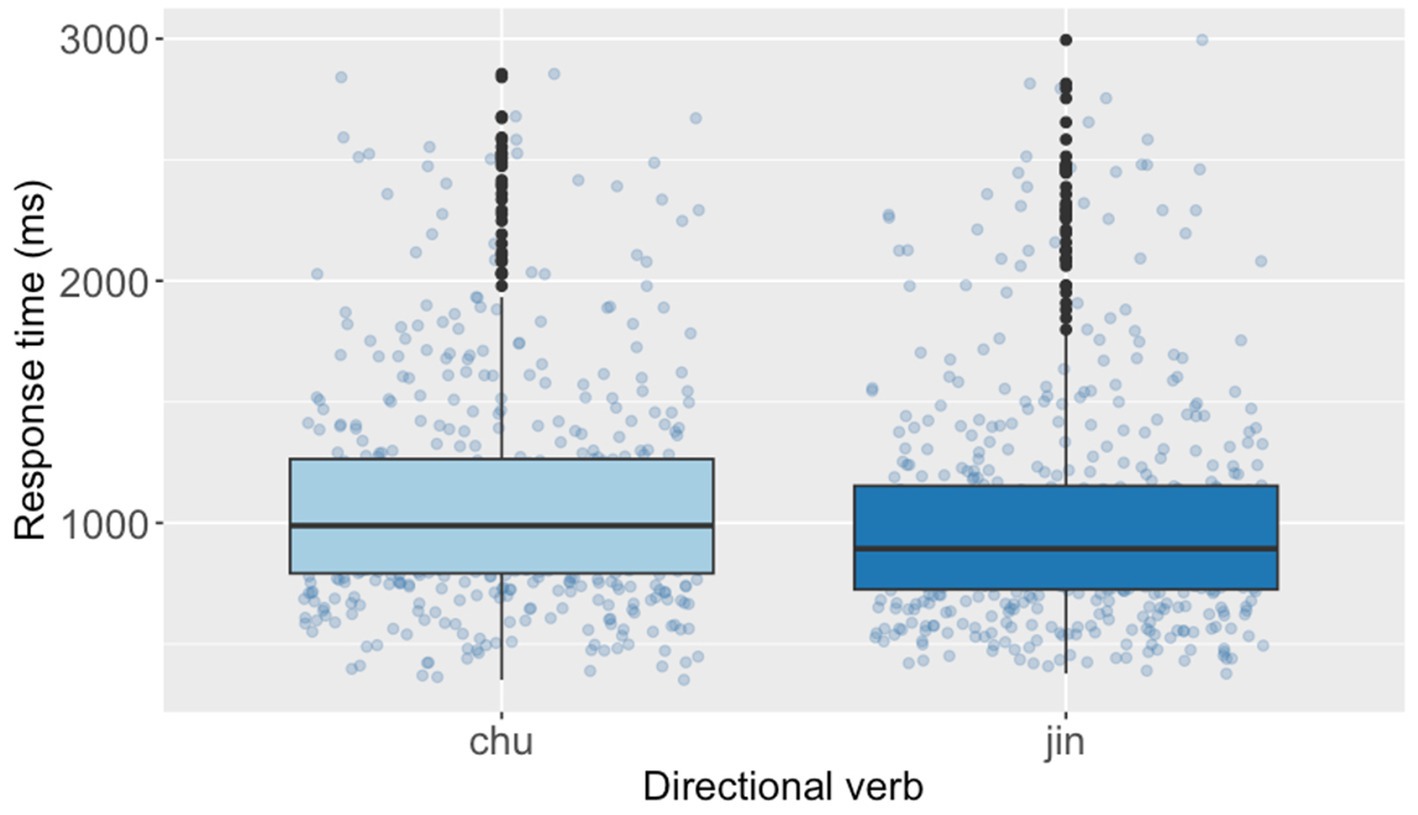
Figure 4. Response times of diagram verification by directional verb of the Chinese SDVT.
4 Experiment 2 4.1 Participants20 adult L1-Chinese learners of L2-English (3 males and 17 females) were recruited from a public university in Australia (Mean age = 24.60, SD = 3.91). All participants were postgraduates pursuing a master’s degree in applied linguistics. Their average onset age of English learning was 8.60 (SD = 3.19) years old. On average, they spent 9.90 h per week reading English articles (SD = 8.39). The length of study abroad experiences ranged from 1 to 50 months (Mean = 15.00, SD = 15.33).
According to the Common European Framework of Reference (CEFR, Council of Europe, 2020), all participants were classified as higher intermediate to advanced L2 learners since their overall IELTS score fell between 6.5 and 7.5, with no bands less than 6.0 (Mean = 6.80, SD = 0.30). Their IELTS reading score ranged from 6.5 to 8.5 (Mean = 7.13, SD = 0.60). In addition to English, most participants reported some knowledge of other languages, including Japanese (n = 5), French (n = 3), Korean (n = 2), Cantonese (n = 1), German (n = 1), Thai (n = 1) and Latin (n = 1). Furthermore, many participants were also proficient in various Chinese dialects, such as Teochew dialect (n = 3), Hokkien (n = 2), Hunan dialect (n = 1) and Henan dialect (n = 1). Upon task completion, each participant received monetary compensation for their time. No participant in Experiment 1 participated in Experiment 2.
4.2 Materials and designExperiment 2 aimed to investigate the mental imagery effects in L2-English online sentence processing. A timed SDVT in English was conducted by adopting the same factorial Latin-square design as Experiment 1. The same untimed semantic rating task was conducted in English to check the semantic consistency between the conceptualizations of the embodied scenes represented by the diagrams and the English sentences containing prepositions.
Experiment 2 utilized the same diagrams as Experiment 1 and targeted both spatial and abstract senses of English prepositions into and out of. All 80 target sentence stimuli in Experiment 2 were translation equivalents of Chinese sentence stimuli used in Experiment 1 (e.g., A diligent employee walked into the office). The stimuli include 56 target sentences and 40 filler sentences for the English SDVT (2 lists), and 24 target sentences for the semantic rating task. All target sentences were generated by following the sentence structure of determiner + adjective + noun + verb + preposition + determiner + noun. The frequencies of verb – preposition collocations and verb – preposition – location collocations were checked using the Corpus of Contemporary American English (COCA) (Davies, 2008). After log-transformation, the results of one-way ANOVA indicated no significant differences in the verb – preposition collocation frequency between prepositions (F = 2.504, p = 0.118) or senses (F = 2.710, p = 0.104). Similarly, no significant differences were observed in the verb – preposition – location collocation frequency between prepositions (F = 0.003, p = 0.953) or senses (F = 1.459, p = 0.231), as well as in the sentence length of characters between prepositions (F = 0.091, p = 0.764) or senses (F = 1.044, p = 0.310).
4.3 ProcedureThe procedure of Experiment 2 was the same as Experiment 1.
4.4 Data analysisData were analyzed using R software (version 4.4.0) (R Core Team, 2024). Data trimming was conducted before the data analysis, following the same trimming criteria on the L1-SDVT data. Since all participants achieved ARs above 80% (ranging from 82 to 100%) in the English SDVT, data from all participants were deemed reliable and retained in the data pool. Only the RTs from target trials with the correct judgment responses in the formal task phase were analyzed. The trials in which the RTs were shorter than 200 milliseconds and longer than 3,000 milliseconds were excluded due to unreliability, resulting in the removal of 3.2% of data points. Experiment 2 used the same R packages and models to analyze the diagram verification RTs as Experiment 1. Variables of individual differences, including the age of acquisition, months of study abroad, hours of reading English articles, IELTS overall score, IELTS reading score, and sentence reading time were log-transformed and treated as covariates in the initial model.
4.5 Results 4.5.1 Results of the English semantic rating taskTable 5 displays the means and SDs of semantic ratings for the consistency between diagrams and English sentences involving two prepositions with spatial and abstract senses. The results of one-way ANOVA revealed significant differences in the consistency ratings between the four diagram – sense categories (F = 9.276, p < 0.001). Tukey post-hoc analysis results indicated ratings to the spatial sense were significantly higher than the abstract sense, applying to both the into diagram (p = 0.031) and out-of diagram (p < 0.001).
Comments (0)